
大数据问题排查系列 - 开启 Kerberos 安全的大数据环境中,Yarn Container 启动失败导致 spark/hive 作业失败
前言
大家好,我是明哥!
最近在若干个不同客户现场,都遇到了
大数据集群中开启 Kerberos 后,spark/hive 作业提交到YARN 后,因 YARN Container 启动失败作业无法执行的情况,在此总结下背后的知识点,跟大家分享下,希望大家有所收获。
1 问题1问题现象
某客户现场,大数据集群中开启了 kerberos 安全认证,提交 hive on mr/hive on spark 任务给 yarn 后执行失败,查看 yarn web ui 可见报错信息:
Application xxx failed 2 times due to AM container for xxx exited with exitCode -1000
......
main : run as user is hs_cic
main : requested yarn user is hs_cic
User hs_cic not found
Failing the application.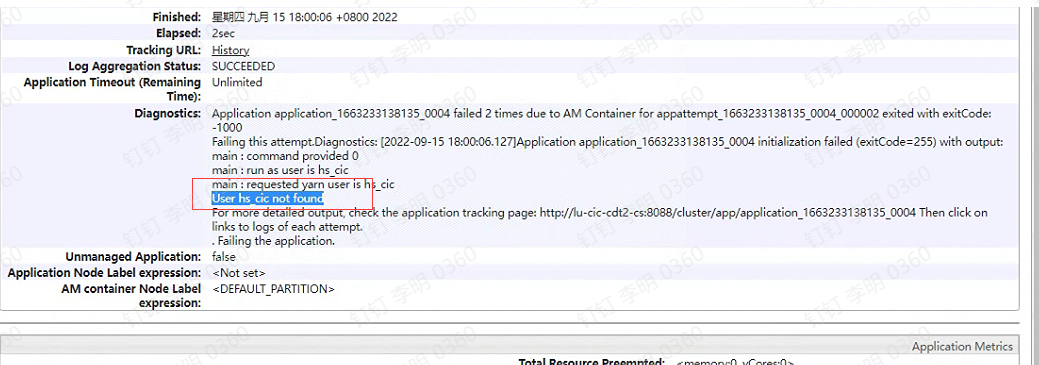
2 问题2问题现象
某客户现场,大数据集群中开启了 kerberos 安全认证,提交 spark on hive 任务给 yarn 后执行失败,查看 yarn web ui 可见报错信息:
main : run as user is app-user
main : requested yarn user is app-user
User app-user not found
Failing the application.3 问题分析
上述问题出现后,在分析过程中,笔者注意到,使用命令 yarn logs -applicationId xxx 查询作业详细日志时,查询不到任何相关日志 (以确认 yarn 已经开启了日志聚合 yarn.log-aggregation-enable),且查看 hdfs 文件系统时发现已经创建了该作业日志对应的目录但该目录下没有文件;
另外在 hive on mr/spark 作业失败的集群中,笔者留意到集群中启用了hive代理:hive.server2.enable.doAs=true.
结合 yarn web ui中的关键报错信息 "Application xxx failed 2 times due to AM container for xxx exited with exitCode -1000...
User hs_cic not found
Failing the application.",可以确认,是因为集群中 YARN nodeManager 节点上没有相关业务用户,所以启动 yarn container 失败,导致作业无法执行。
4 问题原因
- 在没有开启 Kerberos 安全的集群里,启动 yarn container 进程时,yarn.nodemanager.container-executor.class 可以使用 DefaultContainerExecutor 或 LinuxContainerExecutor;
- 在启用了Kerberos 安全的集群里,启动 yarn container 进程时,yarn.nodemanager.container-executor.class 只能使用 LinuxContainerExecutor,其在底层会使用 setuid 切换到业务用户以启动 container 进程,所以要求所有 nodemanager 节点必须有业务用户;
- 当集群中仅仅在 KDC 中添加了业务用户,而没有在 yarn nodemanager 节点建立对应的业务用用户时,nodemanager 节点就会因为没有相关用户而无法启动 container进程,而作业也就会因为无法获取到 contariner 资源从而无法执行而报错了。
5 解决方案
- 解决方案很简单,就是在集群中各个节点上(至少是yarn nodemanager 节点)使用命令 useradd 创建对应的业务用户即可(底层会创建相关用户和用户组并写入到文件/etc/passwd中);
- 如果节点过多嫌弃操作麻烦的话,也可以配置使用 ldap 并在ldap中集中创建相关业务用户,注意是配置 NodeManager 从 LDAP 中查找相关用户,不是使用ldap认证相关用户(--enableldap vs --enableldapauth),具体细节这里不再赘述;
- 针对 hive on mr/spark 的情形,也可以关闭 hive 的代理(hive.server2.enable.doAs=false),此时hiveserver2编译提交sql作业到yarn时,会使用系统用户 hive 的身份进行提交,由于cdh安装时已经自动在集群各节点创建了hdfs/yarn/hive等系统用户,所以执行不会有问题;
6 技术背景
- DefaultContainerExecutor: When using the default value for yarn.nodemanager.container-executor.class,which is org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor, the launched container process has the same Unix user as the NodeManager,which normally is yarn;
- LinuxContainerExecutor: The secure container executor on Linux environmentis org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor, this executor runs the containers as either the YARN user who submitted the application (when full security is enabled) or as a dedicated user (defaults to nobody) when full security is not enabled.
- When full security is enabled, the LinuxContainerExecutor requires all user accounts to be created on the cluster nodes where the containers are launched. It uses a setuid executable that is included in the Hadoop distribution. The NodeManager uses this executable to launch and kill containers. The setuid executable switches to the user who has submitted the application and launches or kills the containers.
- The LinuxContainerExecutor does have some requirements:If running in non-secure mode, by default, the LCE runs all jobs as user “nobody”. This user can be changed by setting “yarn.nodemanager.linux-container-executor.nonsecure-mode.local-user” to the desired user. However, it can also be configured to run jobs as the user submitting the job. In that case “yarn.nodemanager.linux-container-executor.nonsecure-mode.limit-users” should be set to false.
- after integrating hadoop with openldap, hdfs/hive/sentry can find user in openldap, but yarn cannot(the only exceptional is yarn)














