
背景
黑河—腾冲线,又名胡焕庸线,是我国人口密度分布的东西近似分界线。今天把地级市坐标分布密度做成热力图,并与胡焕庸线一起展示时,惊奇的发现,胡焕庸线貌似也是我车东西地级市分布密度的分界线。
生成folium地图
以下30行代码,用于生成一个folium地图,并在地图上绘制一条黑河—腾冲线,同时绘制地级市坐标的分布密度热力图。
# -*- coding:UTF-8 -*-
# region 引入必要依赖
from selfPyTools.MapModule import *
# endregion
# 准备一个地图类对象, 添加 智图GeoQ 的瓦片图
地图 = 地图类(中心点=常用坐标.上海市).添加瓦片.智图GeoQ().地图
# 添加一行网页标题
地图.添加网页标题(网页标题样式类(标题文本='感谢智图GeoQ提供的基础瓦片资源', 文本字体='楷体', 文本颜色=颜色名.灰))
# 生成一个折线对象(折线是由多段直接段组成的,所以一个直线段也可以看成一个折线,只是只有一段而已)
折线 = 折线类(线条样式=线条样式类(透明度=0), 线上文本样式=线上文本样式类(文本=' ★ ', 文本颜色=颜色名.蓝))
折线.添加路径点(常用坐标.腾冲市)
折线.添加路径点(常用坐标.黑河市)
# 将折线添加到图层上
地图.添加标记(地图.添加图层('黑河-腾冲线, 胡焕庸线', 默认显示=True), 折线)
热力层 = 地图.添加热力层()
for 城市, 坐标 in 常用坐标.常用坐标字典.items():
if 坐标.有效:
地图.添加热力点(热力层, 坐标)
# 将地图对象生成一个html的文档保存,并顺便打印这个文档
地图.支持坐标拾取.生成html(文档名='黑河-腾冲线 胡焕庸线', 目标路径='.').打开()
以上代码生成的html地图效果如下: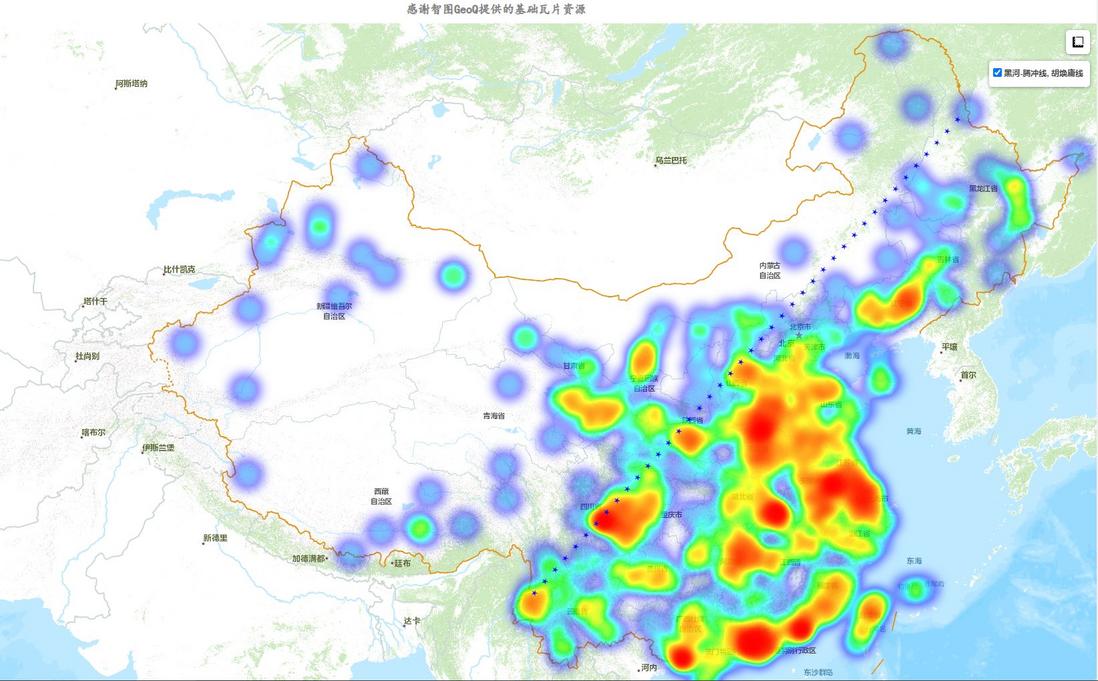
根据地市坐标分布密度热力图,可以大致判断以黑河—腾冲线为东西分界,西侧地市分布密度明显稀疏,而东侧地市分布密度明显稠密。
小结
可以看出,黑河—腾冲线,不仅做为我国东西人口密度的分界线,也大致是我国东西地市分布密度的分界线了。










