
关于事务,简单来说,就是为了保证数据完整性而存在的一种工具,其主要有四大特性:原子性,一致性,隔离性和持久性。对于Spring事务,其最终还是在数据库层面实现的,而Spring只是以一种比较优雅的方式对其进行封装支持。本文首先会通过一个简单的示例来讲解Spring事务是如何使用的,然后会讲解Spring是如何解析xml中的标签,并对事务进行支持的。
1. 使用示例
关于事务最简单的示例,就是其一致性,比如在整个事务执行过程中,如果任何一个位置报错了,那么都会导致事务回滚,回滚之后数据的状态将和事务执行之前完全一致。这里我们以用户数据为例,在插入用户数据的时候,如果程序报错了,那么插入的动作就会回滚。如下是用户的实体:
public class User {
private long id;
private String name;
private int age;
// getter, setter...
}
如下是模拟插入用户数据的业务代码:
public interface UserService {
void insert(User user);
}
@Service
@Transactional
public class UserServiceImpl implements UserService {
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public void insert(User user) {
jdbcTemplate.update("insert into user (name, age) value (?, ?)",
user.getName(), user.getAge());
}
}
在进行事务支持时,Spring只需要使用者在需要事务支持的bean上使用@Transactional注解即可,如果需要修改事务的隔离级别和传播特性的属性,则使用该注解中的属性进行指定。这里默认的隔离级别与各个数据库一致,比如MySQL是Repeatable Read,而传播特性默认则为Propagation.REQUIRED,即只需要当前操作具有事务即可。如下是xml文件的配置:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="url" value="jdbc:mysql://localhost/test?useUnicode=true"/>
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="username" value="****"/>
<property name="password" value="******"/>
</bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource"/>
</bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<context:component-scan base-package="com.transaction"/>
<tx:annotation-driven/>
上述数据库配置用户按照各自的设置进行配置即可。可以看到,这里对于数据库的配置,主要包括四个方面:
- DataSource配置:设置当前应用所需要连接的数据库,包括链接,用户名,密码等;
- JdbcTemplate声明:封装了客户端调用数据库的方式,用户可以使用其他的方式,比如JpaRepository,Mybatis等等;
- TransactionManager配置:指定了事务的管理方式,这里使用的是DataSourceTransactionManager,对于不同的链接方式,也可以进行不同的配置,比如对于JpaRepository使用JpaTransactionManager,对于Hibernate,使用HibernateTransactionManager;
- tx:annotation-driven:主要用于事务驱动,其会通过AOP的方式声明一个为事务支持的Advisor,通过该Advisor和事务的相关配置进行事务相关操作。
按照上述配置,我们的事务功能即配置完成,如下是我们的驱动类程序:
public class TransactionApp {
@Test
public void testTransaction() {
ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService = ac.getBean(UserService.class);
User user = getUser();
userService.insert(user);
}
private User getUser() {
User user = new User();
user.setName("Mary");
user.setAge(27);
return user;
}
}
运行上述程序之后,可以看到数据库中成功新增了一条数据。这里如果我们将业务代码的插入语句之后手动抛出一个异常,那么,理论上插入语句是会回滚的。如下是修改后的service代码:
@Service
@Transactional
public class UserServiceImpl implements UserService {
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public void insert(User user) {
jdbcTemplate.update("insert into user (name, age) value (?, ?)",
user.getName(), user.getAge());
throw new RuntimeException();
}
}
这里我们手动抛出了一个RuntimeException,再次运行上述程序之后我们发现数据库中是没有新增的数据的,这说明我们的事务在程序出错后是能够保证数据一致性的。
2. 标签解析
关于事务的实现原理,我们首先讲解Spring是如何解析标签,并且封装相关bean的,后面我们会深入讲解Spring是如何封装数据库事务的。
根据上面的示例,我们发现,其主要有三个部分:DataSource,TransactionManager和tx:annotation-driven标签。这里前面两个部分主要是声明了两个bean,分别用于数据库连接的管理和事务的管理,而tx:annotation-driven才是Spring事务的驱动。根据本人前面对Spring自定义标签的讲解(Spring自定义标签解析与实现),可以知道,这里tx:annotation-driven是一个自定义标签,我们根据其命名空间(www.springframework.org/schema/tx)在全局范围内搜索,可以找到其处理器指定文件spring.handlers,该文件内容如下:
http\://www.springframework.org/schema/tx=org.springframework.transaction.config.TxNamespaceHandler
这里也就是说tx:annotation-driven标签的解析在TxNamespaceHandler中,我们继续打开该文件可以看到起init()方法如下:
@Override
public void init() {
registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());
registerBeanDefinitionParser("annotation-driven",
new AnnotationDrivenBeanDefinitionParser());
registerBeanDefinitionParser("jta-transaction-manager",
new JtaTransactionManagerBeanDefinitionParser());
}
可以看到,这里的annotation-driven是在AnnotationDrivenBeanDefinitionParser中进行处理的,其parse()方法就是解析标签,并且注册相关bean的方法,如下是该方法的实现:
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 注册事务相关的监听器,如果某个方法标注了TransactionalEventListener注解,
// 那么该方法就是一个事务事件触发方法,即发生某种事务事件后,将会根据该注解的设置,回调指定
// 类型的方法。常见的事务事件有:事务执行前和事务完成(包括报错后的完成)后的事件。
registerTransactionalEventListenerFactory(parserContext);
String mode = element.getAttribute("mode");
// 获取当前事务驱动程序的模式,如果使用了aspectj模式,则会注册一个AnnotationTransactionAspect
// 类型的bean,用户可以以aspectj的方式使用该bean对事务进行更多的配置
if ("aspectj".equals(mode)) {
registerTransactionAspect(element, parserContext);
} else {
// 一般使用的是当前这种方式,这种方式将会在Spring中注册三个bean,分别是
// AnnotationTransactionAttributeSource,TransactionInterceptor
// 和BeanFactoryTransactionAttributeSourceAdvisor,并通过Aop的方式实现事务
AopAutoProxyConfigurer.configureAutoProxyCreator(element, parserContext);
}
return null;
}
可以看到,对于事务的驱动,这里主要做了两件事:①注册事务相关的事件触发器,这些触发器由用户自行提供,在事务进行提交或事务完成时会触发相应的方法;②判断当前事务驱动的模式,有默认模式和aspectj模式,对于aspectj模式,Spring会注册一个AnnotationTransactionAspect类型的bean,用于用户使用更亲近于aspectj的方式进行事务处理;对于默认模式,这里主要是声明了三个bean,最终通过Aop的方式进行事务切入。下面我们看一下Spring是如何注册这三个bean的,如下是AopAutoProxyConfigurer.configureAutoProxyCreator的源码:
public static void configureAutoProxyCreator(Element element,
ParserContext parserContext) {
// 这个方法主要是在当前BeanFactory中注册InfrastructureAdvisorAutoProxyCreator这个
// bean,这个bean继承了AbstractAdvisorAutoProxyCreator,也就是其实现原理与我们前面
// 讲解的Spring Aop的实现原理几乎一致
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
// 这里的txAdvisorBeanName就是我们最终要注册的bean,其类型就是下面注册的
// BeanFactoryTransactionAttributeSourceAdvisor,可以看到,其本质是一个
// Advisor类型的对象,因而Spring Aop会将其作为一个切面织入到指定的bean中
String txAdvisorBeanName = TransactionManagementConfigUtils
.TRANSACTION_ADVISOR_BEAN_NAME;
// 如果当前BeanFactory中已经存在了目标bean,则不进行注册
if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {
Object eleSource = parserContext.extractSource(element);
// 注册AnnotationTransactionAttributeSource,这个bean的主要作用是封装
// @Transactional注解中声明的各个属性
RootBeanDefinition sourceDef = new RootBeanDefinition(
"org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");
sourceDef.setSource(eleSource);
sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
String sourceName = parserContext.getReaderContext()
.registerWithGeneratedName(sourceDef);
// 注册TransactionInterceptor类型的bean,并且将上面的封装属性的bean设置为其一个属性。
// 这个bean本质上是一个Advice(可查看其继承结构),Spring Aop使用Advisor封装实现切面
// 逻辑织入所需的所有属性,但真正的切面逻辑却是保存在其Advice属性中的,也就是说这里的
// TransactionInterceptor才是真正封装了事务切面逻辑的bean
RootBeanDefinition interceptorDef =
new RootBeanDefinition(TransactionInterceptor.class);
interceptorDef.setSource(eleSource);
interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registerTransactionManager(element, interceptorDef);
interceptorDef.getPropertyValues().add("transactionAttributeSource",
new RuntimeBeanReference(sourceName));
String interceptorName = parserContext.getReaderContext()
.registerWithGeneratedName(interceptorDef);
// 注册BeanFactoryTransactionAttributeSourceAdvisor类型的bean,这个bean实现了
// Advisor接口,实际上就是封装了当前需要织入的切面的所有所需的属性
RootBeanDefinition advisorDef =
new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);
advisorDef.setSource(eleSource);
advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
advisorDef.getPropertyValues().add("transactionAttributeSource",
new RuntimeBeanReference(sourceName));
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
if (element.hasAttribute("order")) {
advisorDef.getPropertyValues().add("order", element.getAttribute("order"));
}
parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);
// 将需要注册的bean封装到CompositeComponentDefinition中,并且进行注册
CompositeComponentDefinition compositeDef =
new CompositeComponentDefinition(element.getTagName(), eleSource);
compositeDef.addNestedComponent(
new BeanComponentDefinition(sourceDef, sourceName));
compositeDef.addNestedComponent(
new BeanComponentDefinition(interceptorDef, interceptorName));
compositeDef.addNestedComponent(
new BeanComponentDefinition(advisorDef, txAdvisorBeanName));
parserContext.registerComponent(compositeDef);
}
}
如此,Spring事务相关的标签即解析完成,这里主要是声明了一个BeanFactoryTransactionAttributeSourceAdvisor类型的bean到BeanFactory中,其实际为Advisor类型,这也是Spring事务能够通过Aop实现事务的根本原因。
3. 实现原理
关于Spring事务的实现原理,这里需要抓住的就是,其是使用Aop实现的,我们知道,Aop在进行解析的时候,最终会生成一个Adivsor对象,这个Advisor对象中封装了切面织入所需要的所有信息,其中就包括最重要的两个部分就是Pointcut和Adivce属性。这里Pointcut用于判断目标bean是否需要织入当前切面逻辑;Advice则封装了需要织入的切面逻辑。如下是这三个部分的简要关系图:
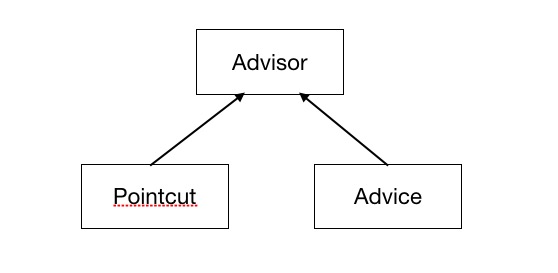
同样的,对于Spring事务,其既然是使用Spring Aop实现的,那么也同样会有这三个成员。我们这里我们只看到了注册的Advisor和Advice(即BeanFactoryTransactionAttributeSourceAdvisor和TransactionInterceptor),那么Pointcut在哪里呢?这里我们查看BeanFactoryTransactionAttributeSourceAdvisor的源码可以发现,其内部声明了一个TransactionAttributeSourcePointcut类型的属性,并且直接在内部进行了实现,这就是我们需要找的Pointcut。这里这三个对象对应的关系如下:
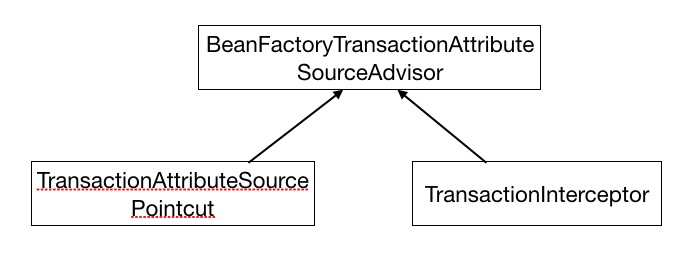
这样,用于实现Spring事务的Advisor,Pointcut以及Advice都已经找到了。关于这三个类的具体作用,我们这里进行整体的上的讲解,后面我们将会深入其内部讲解其是如何进行bean的过滤以及事务逻辑的织入的。
- BeanFactoryTransactionAttributeSourceAdvisor:封装了实现事务所需的所有属性,包括Pointcut,Advice,TransactionManager以及一些其他的在Transactional注解中声明的属性;
- TransactionAttributeSourcePointcut:用于判断哪些bean需要织入当前的事务逻辑。这里可想而知,其判断的基本逻辑就是判断其方法或类声明上有没有使用@Transactional注解,如果使用了就是需要织入事务逻辑的bean;
- TransactionInterceptor:这个bean本质上是一个Advice,其封装了当前需要织入目标bean的切面逻辑,也就是Spring事务是如果借助于数据库事务来实现对目标方法的环绕的。
4. 小结
本文首先通过一个简单的例子讲解了Spring事务是如何使用的,然后讲解了Spring事务进行标签解析的时候做了哪些工作,最后讲解了Spring事务是如何与Spring Aop进行一一对应的,并且是如何通过Spring Aop实现将事务逻辑织入目标bean的。
5. 广告
读者朋友如果觉得本文还不错,可以点击下面的广告链接,这可以为作者带来一定的收入,从而激励作者创作更好的文章,非常感谢!












