
背景
根据本人写博客的惯例,先交代下背景。在公司的系统中,我们的配置文件是切分有好几个的,不同的配置文件里面配置内容有着不同,对于日志的输出,也需要对不同的环境做出不同的输出,这是一个前提,本文即将讲述到的将日志输出到oracle数据库就是分环境输出的,本地测试的日志是非常多的,服务也时常重启,调试等,因此本地环境的日志不宜输出到数据库,而线上环境不同,线上环境的日志输出比本地要少很多,也不经常重启服务。因此本文要讲的内容有以下两点:
- 如何在logback的配置文件中配置不同的profile?
- 如何将日志输出到数据库?这个过程遇到了什么坑?怎么解决的?
本文将在以下软件版本中进行,不同版本是否存在差异尚未测试
springboot v2.1.0
logback v1.2.3
oracle 11.2
java 1.8.0_171
Logback的不同环境配置
在中国,但凡有什么不懂的,第一个想到的就是百度,当然,本人第一反应也是先百度,果不其然,第一页各种解决方案琳琅满目,不过经过本人的实践,得出以下比较有用的,也是本人最终采用的方案,各位看官如果看到这篇文章,可以直接参考。
网上的说法有很多,有些是定义多个logback的文件,例如logback-dev.xml和logback-prod.xml等等诸如此类的,然后在application.yml内进行根据不同的profiles.active来选择不同的日志配置文件。不过这种方式我并没有测试过,重点讲一下下面的方法。
在同一个logback配置文件中,根据不同的<springProfile>来区分,具体可以类似以下的写法:
<springProfile name="prod">
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="infoAppender"/>
<appender-ref ref="errorAppender"/>
<appender-ref ref="DbAppender"/>
</root>
</springProfile>
<springProfile name="dev">
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<!--<appender-ref ref="infoAppender"/>-->
<!--<appender-ref ref="errorAppender"/>-->
<appender-ref ref="DbAppender"/>
</root>
</springProfile>
通过不同的<springProfile>标签来区分不同的环境使用那些appender,但是当本人在原来的logback.xml中这样配置的时候,并不起作用。打开了logback的日志,发现如下的报错
21:35:42,913 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@64:32 - no applicable action for [springProfile], current ElementPath is [[configuration][springProfile]]
21:35:42,913 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@65:28 - no applicable action for [root], current ElementPath is [[configuration][springProfile][root]]
21:35:42,913 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@66:42 - no applicable action for [appender-ref], current ElementPath is [[configuration][springProfile][root][appender-ref]]
21:35:42,914 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@67:47 - no applicable action for [appender-ref], current ElementPath is [[configuration][springProfile][root][appender-ref]]
21:35:42,914 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@68:48 - no applicable action for [appender-ref], current ElementPath is [[configuration][springProfile][root][appender-ref]]
21:35:42,914 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@69:45 - no applicable action for [appender-ref], current ElementPath is [[configuration][springProfile][root][appender-ref]]
21:35:42,914 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@72:31 - no applicable action for [springProfile], current ElementPath is [[configuration][springProfile]]
21:35:42,914 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@73:28 - no applicable action for [root], current ElementPath is [[configuration][springProfile][root]]
21:35:42,914 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@74:42 - no applicable action for [appender-ref], current ElementPath is [[configuration][springProfile][root][appender-ref]]
21:35:42,914 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@77:45 - no applicable action for [appender-ref], current ElementPath is [[configuration][springProfile][root][appender-ref]]
日志的输出也是按照默认的输出,这是为什么呢?正在本人百思不得其解的时候,突然灵机一动,下面开始敲黑板了!既然是<springProfile>那么是不是和spring有关的?如果spring的context没有被加载,那么怎么知道到底是哪个profiles起作用呢?
对于这个问题,本人尝试将logback.xml替换成了logback-spring.xml,重启应用,发现可以通过。
logback.xml在springboot中,是先于spring上下文加载的,因此,在加载这个配置文件时,还不知道到底采用哪个profile,也就是说<springProfile>这个标签并不会在这个阶段起作用。logback-spring.xml是先初始化spring上下文,这个时候<springProfile>才生效
Logback将日志输出到数据库
我这里采用的是oracle数据库,因此针对oracle数据库做一些简单说明,并且指出所遇到的坑。
可能有朋友会问,我想将日志输出到数据库,那么数据库的表我是要自己建吗?要建成怎么样的呢?答案是不需要的,logback官方有提供有对应的sql脚本,直接找到对应的数据库脚本进行创建即可,要不然你自己建的表,logback也不认识啊对吧。 logback数据库脚本
以下是针对oracle的数据库脚本
CREATE SEQUENCE logging_event_id_seq MINVALUE 1 START WITH 1;
CREATE TABLE logging_event
(
timestmp NUMBER(20) NOT NULL,
formatted_message VARCHAR2(4000) NOT NULL,
logger_name VARCHAR(254) NOT NULL,
level_string VARCHAR(254) NOT NULL,
thread_name VARCHAR(254),
reference_flag SMALLINT,
arg0 VARCHAR(254),
arg1 VARCHAR(254),
arg2 VARCHAR(254),
arg3 VARCHAR(254),
caller_filename VARCHAR(254) NOT NULL,
caller_class VARCHAR(254) NOT NULL,
caller_method VARCHAR(254) NOT NULL,
caller_line CHAR(4) NOT NULL,
event_id NUMBER(10) PRIMARY KEY
);
-- the / suffix may or may not be needed depending on your SQL Client
-- Some SQL Clients, e.g. SQuirrel SQL has trouble with the following
-- trigger creation command, while SQLPlus (the basic SQL Client which
-- ships with Oracle) has no trouble at all.
CREATE TRIGGER logging_event_id_seq_trig
BEFORE INSERT ON logging_event
FOR EACH ROW
BEGIN
SELECT logging_event_id_seq.NEXTVAL
INTO :NEW.event_id
FROM DUAL;
END;
/
CREATE TABLE logging_event_property
(
event_id NUMBER(10) NOT NULL,
mapped_key VARCHAR2(254) NOT NULL,
mapped_value VARCHAR2(1024),
PRIMARY KEY(event_id, mapped_key),
FOREIGN KEY (event_id) REFERENCES logging_event(event_id)
);
CREATE TABLE logging_event_exception
(
event_id NUMBER(10) NOT NULL,
i SMALLINT NOT NULL,
trace_line VARCHAR2(254) NOT NULL,--# 此处需要注意
PRIMARY KEY(event_id, i),
FOREIGN KEY (event_id) REFERENCES logging_event(event_id)
);
上述脚本大体上并不会有什么大的问题,但是要注意logging_event_exception这个表的trace_line这个字段,在这里是定义了254个长度,这个字段主要是用来记录异常堆栈的,一条堆栈对应一条记录,那么有时候堆栈的信息远远不止254个字符,因此,这个长度就会造成不够长而报错。针对这种情况,建议设置成1024个长度。
有些包名类名就比较长的堆栈,怎么可能只有254个长度呢!
创建好数据表之后,接下来就是配置logback-spring.xml了,为了提高性能,采用了数据库连接池,由于项目中采用的是druid,因此,沿用项目中的数据库连接池。在经过一番搜索之后,得到了不少类似下面的配置,呃呃呃呃呃
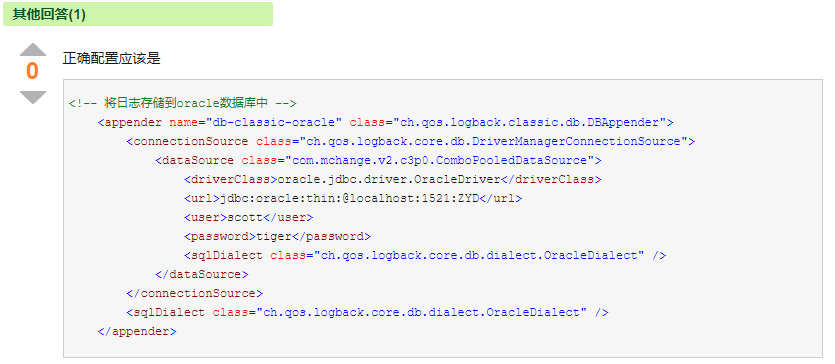
从上面的配置看,不难看出,配置了c3p0的数据库连接和数据库方言,看着似乎没有什么问题,动手试试看吧,直接复制粘贴到自己的配置文件,运行^^^ 似乎不好使啊!再仔细认真看一遍,似乎没有错误啊,只不过是把C3P0换成了Druid而已啊
<appender name="DbAppender" class="ch.qos.logback.classic.db.DBAppender">
<connectionSource class="ch.qos.logback.core.db.DataSourceConnectionSource">
<dataSource class="com.alibaba.druid.pool.DruidDataSource">
<driverClass>oracle.jdbc.OracleDriver</driverClass>
<user>username</user>
<password>pass</password>
<url>jdbc:oracle:thin:@ip:1521:orcl</url>
<sqlDialect class="ch.qos.logback.core.db.dialect.OracleDialect"/>
</dataSource>
</connectionSource>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
</appender>
结果,报错了……心碎
10:25:33,859 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@47:30 - no applicable action for [driverClass], current ElementPath is [[configuration][appender][connectionSource][dataSource][driverClass]]
10:25:33,864 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@48:23 - no applicable action for [user], current ElementPath is [[configuration][appender][connectionSource][dataSource][user]]
10:25:33,867 |-ERROR in ch.qos.logback.core.joran.spi.Interpreter@51:83 - no applicable action for [sqlDialect], current ElementPath is [[configuration][appender][connectionSource][dataSource][sqlDialect]]

最主要的报错原因和最上面的springProfile类似,就是没有适用的action……巴拉巴拉,奇了怪了!后面猜测是不是因为指定了数据源,不同的数据源里面的配置不一样?在初始化数据库连接池的时候,通过反射构造连接池的时候,没有找到对应名字的字段?于是乎根据druid的配置,换成了如下的配置
<appender name="DbAppender" class="ch.qos.logback.classic.db.DBAppender">
<connectionSource class="ch.qos.logback.core.db.DataSourceConnectionSource">
<dataSource class="com.alibaba.druid.pool.DruidDataSource">
<driverClassName>oracle.jdbc.OracleDriver</driverClassName>
<username>username</username>
<password>pass</password>
<url>jdbc:oracle:thin:@ip:1521:orcl</url>
<sqlDialect class="ch.qos.logback.core.db.dialect.OracleDialect"/>
</dataSource>
</connectionSource>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
</appender>
重新运行,这次虽然还是没有成功,但是报错明显变少了,仅有sqlDialect报错……啊哈哈,似乎发现了黎明之前的黑暗!
对于不同的数据库连接池,logback是不知道内部跟jdbc相关的配置的名称是怎么样的,因此,使用不同的数据库连接池时,要根据其内部的名称来配置
dataSource标签!根据这个规律,一些数据库的其他配置,例如最大连接数,最大空闲连接数等应该也是可以修改的,本人并没有测试。
在挣扎了一段时间之后,实在想不出为什么<sqlDialect>会报错,是logback不支持吗?还是?看来只能一探源码方知究竟了。在查看了logback的源码之后,发现在一个叫DBUtil的类里面终于找到了真相!
public class DBUtil extends ContextAwareBase {
private static final String POSTGRES_PART = "postgresql";
private static final String MYSQL_PART = "mysql";
private static final String ORACLE_PART = "oracle";
// private static final String MSSQL_PART = "mssqlserver4";
private static final String MSSQL_PART = "microsoft";
private static final String HSQL_PART = "hsql";
private static final String H2_PART = "h2";
private static final String SYBASE_SQLANY_PART = "sql anywhere";
private static final String SQLITE_PART = "sqlite";
public static SQLDialectCode discoverSQLDialect(DatabaseMetaData meta) {
SQLDialectCode dialectCode = SQLDialectCode.UNKNOWN_DIALECT;
try {
String dbName = meta.getDatabaseProductName().toLowerCase();
if (dbName.indexOf(POSTGRES_PART) != -1) {
return SQLDialectCode.POSTGRES_DIALECT;
} else if (dbName.indexOf(MYSQL_PART) != -1) {
return SQLDialectCode.MYSQL_DIALECT;
} else if (dbName.indexOf(ORACLE_PART) != -1) {
return SQLDialectCode.ORACLE_DIALECT;
} else if (dbName.indexOf(MSSQL_PART) != -1) {
return SQLDialectCode.MSSQL_DIALECT;
} else if (dbName.indexOf(HSQL_PART) != -1) {
return SQLDialectCode.HSQL_DIALECT;
} else if (dbName.indexOf(H2_PART) != -1) {
return SQLDialectCode.H2_DIALECT;
} else if (dbName.indexOf(SYBASE_SQLANY_PART) != -1) {
return SQLDialectCode.SYBASE_SQLANYWHERE_DIALECT;
} else if (dbName.indexOf(SQLITE_PART) != -1) {
return SQLDialectCode.SQLITE_DIALECT;
} else {
return SQLDialectCode.UNKNOWN_DIALECT;
}
} catch (SQLException sqle) {
// we can't do much here
}
return dialectCode;
}
// 以下代码省略……
}
原来logback是可以根据Connection获取到DatabaseMetaData对象,然后根据meta来获取到底是哪个数据库产品,从而自动返回对应的方言。换句话说就是,根本不需要手动配置什么sqlDialect,自动可以获取,(其实根据jdbcurl都知道是什么数据库了)那么我们在里面设置方言其实有点画蛇添足了。
可能以前的历史版本是需要手动设置dialect的,在现在的版本应该是改进了,本人也没有去比对过历史源码,只是猜测而已!有兴趣的看官可以自己去github比对下。
好了,到了这里,踩坑就结束了,下面就贴上logback+druid连接池的appender配置,对于其他数据库连接池,我想如果看了上面的内容,应该也都会怎么配置避免掉进这个坑里面了。
<appender name="DbAppender" class="ch.qos.logback.classic.db.DBAppender">
<connectionSource class="ch.qos.logback.core.db.DataSourceConnectionSource">
<dataSource class="com.alibaba.druid.pool.DruidDataSource">
<driverClassName>oracle.jdbc.OracleDriver</driverClassName>
<username>username</username>
<password>pass</password>
<url>jdbc:oracle:thin:@ip:1521:orcl</url>
</dataSource>
</connectionSource>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
</appender>
后记
针对一些场景,报错日志比较多的情况下,异常堆栈也是比较多的,存放在数据库视情况而定,从性能的角度来说,数据库并不是最优的选择。本文也只是抛砖引玉而已,如果对日志的搜索和存储性能有比较大的需求,并不建议直接存放到数据库。如果是一套比较大的系统,还是建议使用ELK套件来实现这个功能。如果是一些不太大的系统,也可以使用本文所讲述的方式进行存储。












