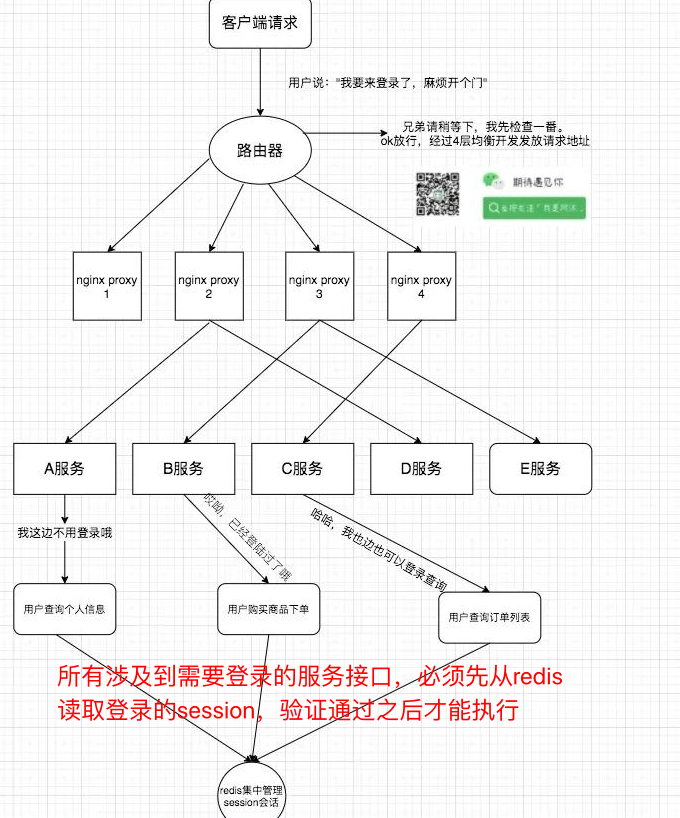
英国弗兰明曾说过一句话:“不要等待运气降临,应该去努力掌握知识。”
1 前言
大家好,我是阿沐!你的收获便是我的喜欢,你的点赞便是对我的认可。
今天呢,我们就不聊redis面试系列,我们一起来聊一聊限流操作以及使用场景。很奇怪哈,为啥突然转变画风了,之前一篇文章中提到 redis的限流操作,并没有实际给小伙伴们演示以及场景的使用演练。所以呢,既然有人私聊问我了,那么今天我们来聊一聊这个。
当然想写这篇文章并不是空穴来风,实际的面试场景中是会被面试官问及到。一般一个成熟的公司它的限流是通过一个中台服务(此中台并非阿里出的中台,其实就是一个网络上游服务),你app的所有请求都要经过上游的验证、检测处理,如果配置了哪些接口限流,那么它就能自动监控告警,然后才去限流、降低、熔断措施。可是并不是很多公司都有一套这种规范流程,所以大部分还是基于redis做简单版的限流服务。
好吧,开始新的面试侧重点!
2 什么是接口限流
面试官:“经验一年,不会不知道什么是限流操作吧”。可以说一说你对限流的理解嘛?
面试者:“卧槽,过分了呀,我之前可是在外包公司,用户数不多,流量也并不大,qps更不提了,这分明是在搞我,要我搬出理论知识”。硬着头皮说道:顾名思义,限流就是限制请求流量;那么它又分为一定时间内总的请求流量和并发流量。

面试官:看你的回答中把限流分为两种情况,单位请求并发量和一段时间内总流量,可以分别描述它的使用场景嘛?
面试者:“我真是嘴贱啊,干嘛没事说那么多,给自己找事做了都,桌子下面竖起了中指”。断断续续的降到:① 并发流量大致是指网站在同一时间访问的人数,人数越多,瞬间带来的流量就对带宽受到影响。② 一定时间内总流量是指在单位时间内总共请求数带来的流量。
面试官:可以,了解的挺清楚的的,那么一般你是怎么应对因为大流量带来服务性能受到影响的情况呢?“心里默念到:虽然你才工作一年,但是也想考验下你对这方面的了解程度,看看是否是可造之才”
面试者:“老babe啊,你这是要干什么嘛?是不是觉得我像是一个高级开发哦,我这么年轻,这么帅,这样为难我?想了想自己平常在网络上看到的名词,吹一吹吧”。我们应对大流量常用的手段有:① 缓存(尽早接入缓存,防止大量频繁请求DB);② 限流(在一定时间内把请求限制在一定范围内,保证系统不会击垮);降级(是指对部分服务有策略的不处理或者简单处理)。
PS:缓存和降级并不是能解决所有大流量情况。比如之前我做电商,千万级别的用户瞬间秒杀下单,大量的写库操作是我们无法控制的,db的吞吐量是有瓶颈的。所以服务引入限流操作,就会大大降低服务的崩溃问题。
面试官:“知道的挺多的,超出了我的预料,再探探这个小伙子的底子”。基本上说的还可以吧,可以简单说下你再实际项目中如何使用限流,限流的方案有哪些嘛?
3 这个面试官肯定在搞我
目前限流常用的方式:计数器、滑动窗口、漏桶算法、令牌桶算法四种方案,下面我们逐一讲解下(ps:在之前公司已经实践过)。
3.1 计数器算法
计数器算法是限流算法中最简单最容易实现的方式,用途比较广泛。一般在做接口时,都会使用这种方式进行接口限流。
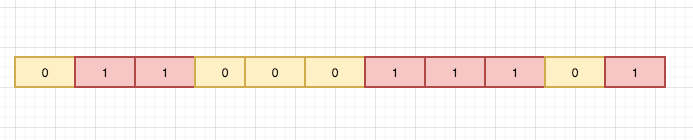
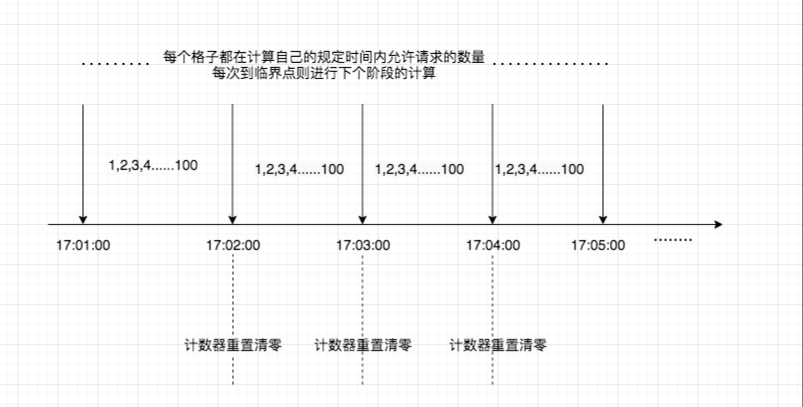
例如:比如说我们网站活动任务接口,假设qps为100/min。那么我们的方案可以这样做:① 设置计数器counter ;② 请求过来时counter+1;③ 假如counter值大于1000且当前请求时间与第一个请求时间差小于等于1min,则表示请求超出站点负载,直接阻断;④ 若当前请求与第一个请求时间差大于1min且counter值小于等于100,则重置计数器归0(全网都是抄来抄去);
我个人理解是:我们限流操作除了针对大流量,那么还可以用来控制用户的行为,避免产生垃圾请求。最常见的发帖、点赞、回复评论这些行为都是要经过限流控制(针对个人用户行为)。不单单只是针对某一个接口所有用户的集中请求。
下面画了一张示意图:
/**
* @desc 计数器限流
* @return bool
*/
public function counter()
{
$curr_time = time();
// 如果当前请求时间大于第一次请求时间+最大限制时间
if ($this->first_request_time + $this->fix_time > $curr_time) {
//若当前的请求数量 大于等于 限制的总数量
if ($this->request_count >= $this->request_limit) return false;
$this->request_count++;
return true;
} else {
// 重置第一次请求时间 和 请求总次数
$this->first_request_time = $curr_time;
$this->request_count = 1;
return true;
}
}面试官:微微点头,那么限流它有什么优点和缺点呢?
面试者:① 优点:访问量限流实现简单,适用于绝大多数的场景。同时qps/min的值我们可以用个服务端动态来配置,只需要大概估算qps的数值即可。② 缺点:存在时间上的临界点,如果最后1s跟下一分钟的开始集中请求量,那么依然存在大流量的恶意请求,甚至超出预估的系统瓶颈,导致服务瘫痪。
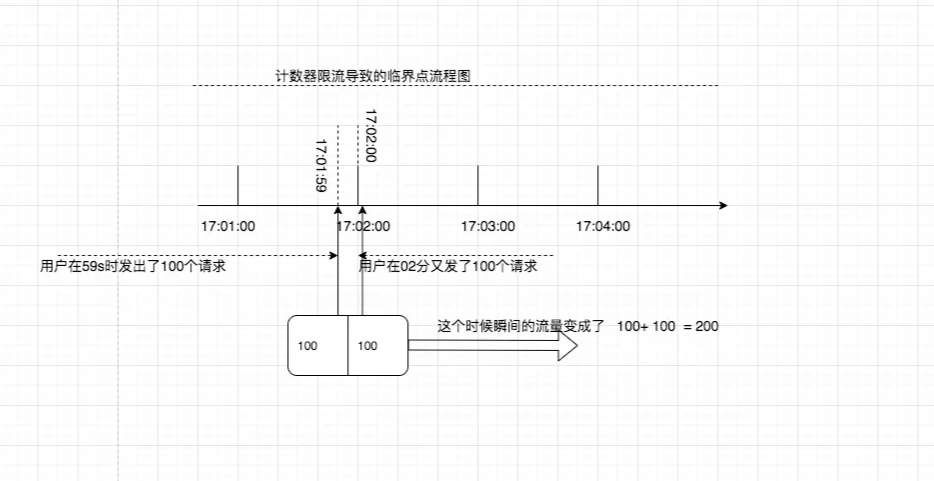
从上面不难看出,其实这个用户在1秒里面,瞬间发送了200个请求;那么完全超出我们我们刚才规定的是1分钟最多100个请求,那么限流就相当于无效了,用户有可能利用这个节点瞬间击垮服务。
面试官:“既然你都已经说到缺点了,那我就勉为其难的问你下有无方案解决,仿佛在说:你这么牛,我是不是很没面子”。那你针对计数器的缺点,有没有思考过解决方案呢?

面试者:“我特么想一拳锤晕你,这叫个什么事,我没搞过,没有实践过啊;这不是故意让我回答补上来,压我工资嘛;硬着头皮吹了,反正不要钱”。恩恩额.....,我依稀记得还有一种方案叫做滑动窗口算法,就是用来弥补计数器的缺陷。
3.2 滑动窗口算法
滑动窗口的意思简单来说就是将固定的时间进行分片处理,分割成多分,并且随着时间的流逝,进行往前移动。那么计数器的临界点就可以很好的避免掉,每一个格子都有自己独立的计数器counter,每个格子计算自己的阀值;这就说明了,当滑动窗口的格子划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。下面我们画图说明:
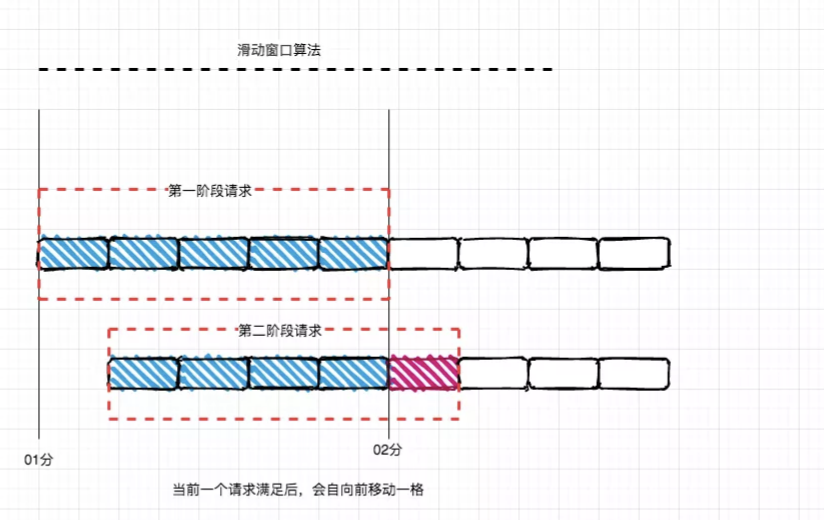
从上面图可以看出滑动窗口是如何解决临界点:1分59秒时到达的100个请求会落在蓝色格子里,在2分时用户又到达了100个请求,这个时候就落在了红色格子里;但是这个时候格子会自动向右边移动一格,导致此时会有200个请求,超过了我们执行的100,就触发了限流操作(大家可以自行谷歌查阅相关资料)。这里展示代码如下:
/**
* @desc 平滑移动方法
* @return bool
*/
public function slide()
{
$key = 'slide:test:key:user';
$redis = new \Redis();
$now_time = time();
// 事务处理 按照先后顺序把命令放进一个队列当中
$redis->multi();
// value + score 都使用毫秒时间戳
$redis->zAdd($key, $now_time, $now_time);
// 移除时间窗口之前的请求记录,剩下的就全部都是时间窗口内的
$redis->zRemRangeByScore($key, 0, $now_time - $this->fix_time);
// 获取窗口内的记录数量
$redis->zCard($key);
// 设置 移动窗口的过期时间 避免占用过多的内存 过期时间等于最大窗口长度 额外补加1s
$redis->expire($key, $this->fix_time + 1);
// 批量执行 此操作是原子性的
$result = $redis->exec();
$current_count = isset($result[3]) ?$result[3]:0;
return $current_count < $this->request_limit;
}面试官:“必须给你一个赞,讲的确实明了,虽然还有一些瑕疵,但是细想更重要”。 恩,恩,你这里说的还算清楚,有一些细节还不到位,有空可以自己查阅文档看看。不过总体来说,回答的已经很ok了。比较符合我预期的想法...
3.3 漏桶算法
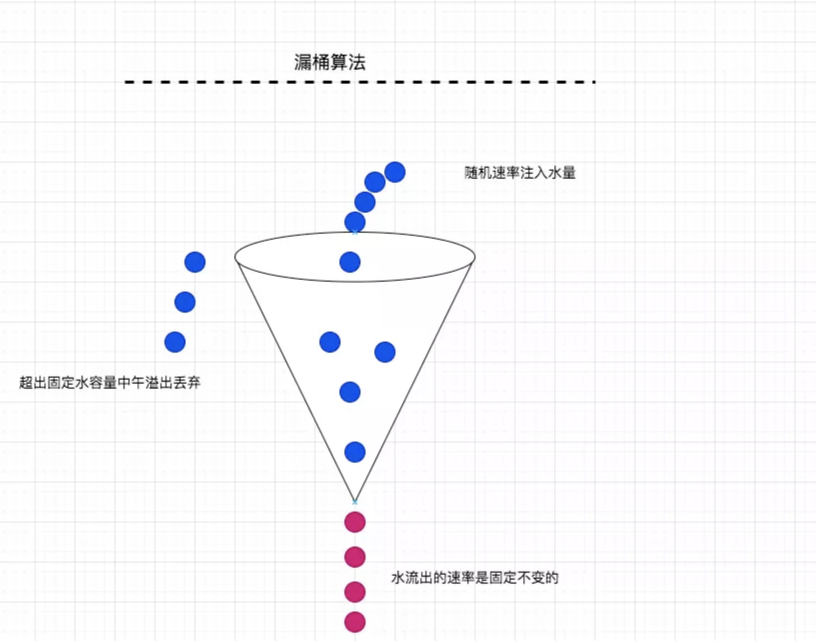
面试者:漏桶算法相对来说比较简单,大概就是这么个过程:① 找一个固定容量的漏斗;② 往漏斗里注入数量,随机速率注入;③ 保证漏斗的容量不变,均匀速率流出水量;④ 超出容量的水直接溢出丢弃;一下是整体的流程图:“心里嘀咕着,这个真没啥可讲的,知道原理就可以了吧,别问我了好不!”
/**
* @desc 漏桶算法
* @return bool
*/
public function leaky()
{
// 当前请求时间戳
$curr_time = time();
// 计算当前请求的使用水量
$out_water = ($curr_time - $this->last_request_time) * $this->rate;
// 计算漏斗内的水量剩余多少
$this->water = max(0, $this->water - $out_water);
$this->last_req_time = $curr_time;
// 若桶内水量还没有满 则往桶内继续加水
if ($this->water < $this->capacity) {
$this->water = $this->water + 1;
}
// 抱歉水桶已经满了,拒绝加水量
return false;
}面试官:“不错,核心的逻辑走向看来挺清晰的”。嗯嗯嗯,漏桶算法比较简单,只要原理流程就ok。知道有这么一回事,虽然用的不多,不过还是要考察你对这方便的知识点的(内心在波动,现在一年经验的小伙子都知道这么多了)。那么可以在说说你在项目中是否用到了令牌桶算法呢?
3.4 令牌桶算法
面试者:面试官你好,其实在实际的项目中我基本上很少用到令牌桶的算法,因为稍微复杂化了点,并且我们公司并没有特别大的流量,并发性的用到的更少了。涉及知识面比较欠缺,所以我才想着能换一个工作环境;能通过更大的平台以及优秀技术的方案来提升自己的水平;“内心慌的一瞥,还是要谦虚一点,不能太突出了,显的面试官很菜,我简单的说说自己的看法算了”。虽然我没使用过,但是我想说一说我对令牌桶的看法吧。
我们可以看到漏桶算法会出现这样的一个场景:因为漏桶的水流速度是固定不变的,若瞬间的大流量冲击过来,可能会导致桶内水的溢出意味着大批的请求被丢弃掉;因此令牌桶就出现了,用来解决这个问题。 ① 令牌桶的生成速率依然是恒定不变 ② 请求过来拿令牌的速率是不受限制(随机) ③ 请求拿不到桶内令牌则拒绝请求 ④ 桶内容量达到满值则丢弃多余令牌 ⑤ 保证绝大部分流量请求正常,牺牲小部分流量请求
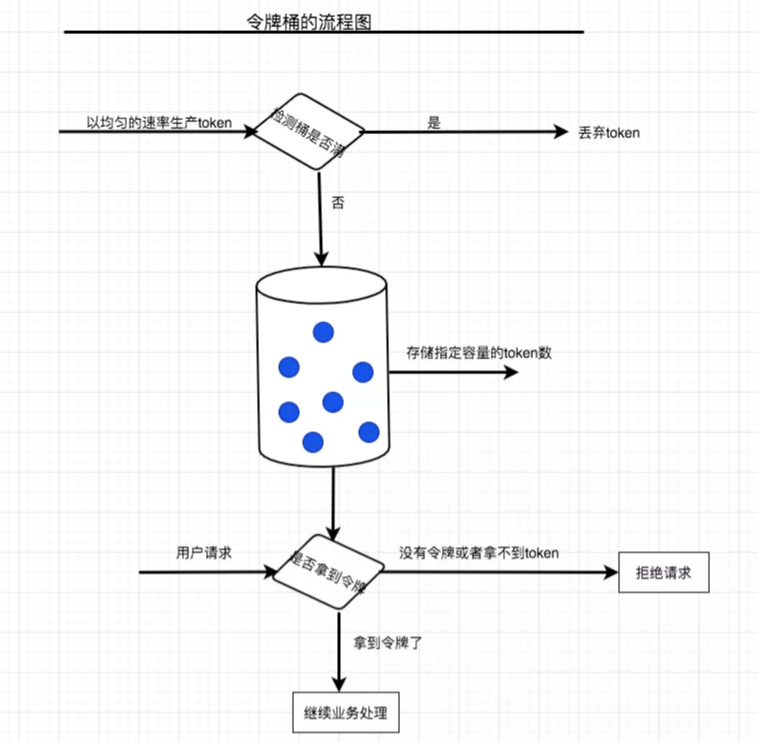
原理是:桶内token数据开始为0,以固定的速率生产token并填充桶内,知道桶内容量满,多余token被丢弃;每一个请求过来先拿token令牌,拿到移除,否则拒绝请求。
下面是是令牌桶使用案例代码:
/**
* @desc 令牌桶方法
* @return bool
*/
public function token()
{
// 当前请求时间戳
$curr_time = time();
// 计算当前生产的令牌数
$inside_token = ($curr_time - $this->last_request_time) * $this->create_token_rate;
// 计算桶内还能使用的令牌数量
$this->tokens = min($this->capacity_size, $this->tokens + $inside_token);
$this->last_req_time = $curr_time;
// 假如桶内的令牌数少于1个 则拒绝获取
if ($this->tokens < 1) return false;
// 令牌数还有 则移除一个
$this->tokens = $this->tokens - 1;
return true;
}面试官:“不是说讲的不咋地嘛,看来还是挺了解嘛”。你上面已经情况分析和使用流程原理已经很清晰了。说白了都是差不多的原理,只是让它会变得越来越紧凑,就是越来越完善。假如让你使用redis来做令牌桶,你有没有自己的想法呢?
面试官:使用redis做令牌桶,我之前在网上看过php+swool做限流操作,其中就是使用lPush(入队)、rPop(出队)用来实现令牌的增加和移除操作。那么配合使用swool的定时器刚好可以算是完美解决这个问题。下面是我凭着记忆来书写代码:
/**
* @desc 网令牌桶内添加令牌操作
* @param int $num 添加的数量
* @return int
*/
public function insert($num = 0)
{
// 当前桶内令牌剩余数量
$curr_count = intval($this->redis->lLen($this->queue_name));
// 计算当前桶内最大可添加多少令牌 若大于桶内令牌 则相减获取应添加数量 否则直接添加
$num = $this->max_volume >= $curr_count + $num ? $num : $this->max_volume - $curr_count;
// 若不能添加令牌 则返回添加0个元素
if ($num <= 0) return 0;
//添加令牌操作 生成令牌数据
$tokens = array_fill(0, $num, 1);
// 批量添加令牌进入队列
$result = $this->redis->lPush($this->queue_name, ...$tokens);
if ($result) return $num;
return 0;
}面试官:“不赖不赖,这还说是凭着记忆讲解呢,感觉像是实战过的样子,给你点个赞。看来得让其他的小组长也面试下这个小伙子,看看表现怎么样”。没想到你对接口限流了解的这么透彻,这么详细,相比较起来你是我面试中基础比较扎实的一个;经验虽然不是最丰富的,但是后劲十足,希望后面也能更好的进一步提升自己技能。我们休息一下,等下二面的小组长面试你吧...
PS:以上则是实现限流的集中方案的部分代码,详细代码:https://github.com/woshiamu/amu/tree/master/redis
最后总结
面试者:你好面试官,虽然我并没有全部用于实战中,但是也是尽量的自己会在本地实践,然后去模拟并发大流量,测试下结果;这样也加深了自己对这些概念的理解,希望可以进入贵公司跟着你能继续进一步的去在项目上实践。
那么上面呢,我们是通过一步一步的引导然后产生一个疑问,用来解答整个限流方案的流程。说实话:网络上基本上都有很多案例,大同小异;希望能通过这种慢慢迭代引入的方式解开限流场景与实战。那么更倾向于大家去使用计数器和redis令牌桶实现限流,一个是普通使用,一个是可以精确使用,根据自己的场景去选择。当然还会有更多的方案,例如:限流中间件(大家自己谷歌查询吧)、Nginx+Lua(本人常使用这种方案)等可以更好的实现。
好了,我是阿沐,一个不想30岁就被淘汰的打工人 ⛽️ ⛽️ ⛽️ 。