英国弗兰明曾说过一句话:“不要等待运气降临,应该去努力掌握知识。”
1 前言
大家好,我是阿沐!你的收获便是我的喜欢,你的点赞便是对我的认可。
上一章节面试官问了我们关于string数据结构的使用场景以及注意的点。虽然我们对答如流,但是毕竟只是redis很基础的知识点,下面面试官即将开始新的一轮面试要点,注重考查我们的日常工作中使用的场景以及怎样解决出现的弊端。
当前的面试角色可能只有一年多开发经验,绝大部分(非运气好/985/211毕业)可能刚毕业不一定进入大厂(百度、网易、阿里、腾讯、字节等),一般都是在小公司几个人或运气好点几十个人的团队,运气差的可能就在外包做;PS:并未说外包不好,因为它是绝大部分开发的一个过渡阶段。可能经常的重复工作增删改查或者更广的技术,但是因数据量级、用户量级、服务器量级等等影响,无法实践。但是跳槽经常面对的是:面试造火箭,进去拧螺丝的场景。所以我们要了解更多的面试知识,才能有机会进入大厂,才能有学到更多更先进且能亲自实践的机会。
好了,开始我们新的一轮面试知识焦点!
2 数据结构list的理解
面试官:心里暗暗说道,小伙子,不要以为string的数据结构说的很好,就暗暗窃喜,你以为我们只是问这么简单的基础知识;你以为让你进来拧螺丝就可以放松技术含量,不可能滴!虽然进来让你干简单业务,但是怎么也得技术牛叉点,有后发之力哦。来来来,说下你对数据结构list的理解?
面试者:我特么我的刀呢?我就只是面试一个初级开发岗位,你这是要跟我动真格的呀。问的没玩没了还,差不多就行了吗,问这么多。算了,就让你面试造下火箭🚀吧,下面是我对list的理解:

Redis官方术语:列表是简单的字符串列表(说通俗点,存储的还是字符串),按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边),个列表最多可以包含^32-1个元素(每个列表超过40亿个元素)。
注意点:列表它并不是数组而是数据结构中的链表,这就说明列表的插入和删除操作速度很快,在插入的时候可以达到O(1)的复杂度,但是通过索引去查找一个节点是非常慢的,时间复杂度O(n)的时间。列表内部是一个双链表,它的每个数据结点中都有两个指针,分别指向后节点和前节点。所以从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。当列表的最后一个元素被弹出后,该数据结构就会被自动删除,内存被回收。
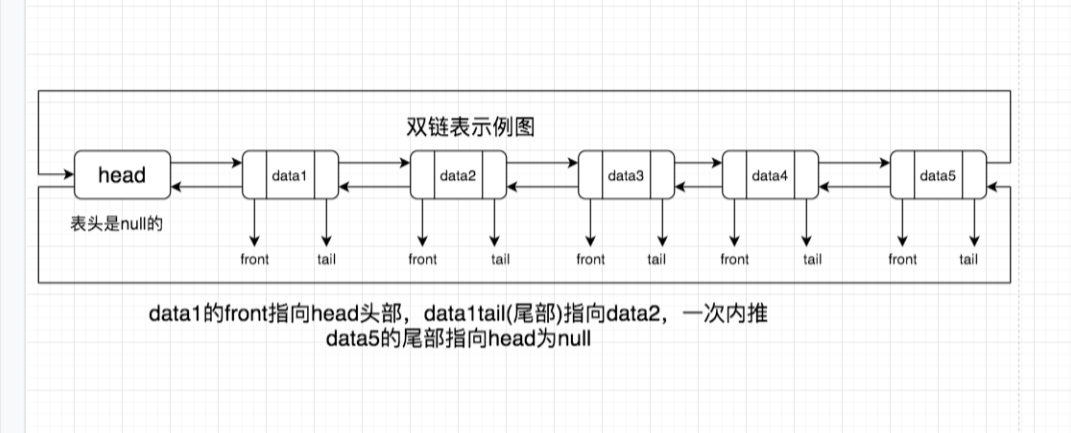
面试官:恩恩,讲的挺细致的!既然你提到了数组和链表,那么你知道数组和链表之间的区别嘛?单链表和双链表又有什么区别嘛?可以简单地说下的理解
面试者:“默默的骂着:我是来面试什么岗位啊,这也要问,我求求你不要再问了,不然我就直接走人啦”。沉默想了一会说道:
1 、数组与链表区别
数组是静态分配内存,且内存是连续的;索引定位时间复杂度O(1),插入和删除时间复杂度O(n),内存利用率低(申请数组之前必须规定数组大小);随机访问性强可通过下标进行快速定位(这就知道为啥索引定位复杂度是O(1)了吧)
链表是动态分配内存,且不需要内存连续;索引定位时间复杂度O(n),插入和删除时间复杂度O(1),内存利用率高(可使用内存中不连续空间且需要空间时才创建);不能随机查找,必须从第一个数据开始遍历(这就知道为啥索引定位复杂度是O(n)了吧)
2、单链表和双链表的区别
单链表只有一个指向下一个节点的指针,只能next不能prev(单项读取);存储空间较少,只需要存储单项指针;插入数据需遍历链表,时间复杂度O(n)。
双链表有指向下一节点的指针外还有一指向前一节点的指针,可next可prev(双向读取);存储空间较大(保存next指针时,还保存prev指针)。
面试者:”随便说一下就这样了,已经超出我的知识范围了,大学学的数据结构都已经忘完了,谁还记得那么多”。面试官你好,上面就是我对数组和链表区别的看法。
面试官:“小伙子可以的嘛,还是了解一点的,基础比较扎实了”。恩,回答的还算可以,虽然不够深入的理解区别性,总体来说相当全面了。我看你简历上你使用redis做了一系列的功能实现,那我们开始聊一聊你在实际项目中是怎样运用列表命令的吧!
3 额,这才是正式问答嘛
3.1 列表常用命令以及注意事项
面试官:可以简单的说一说,你在项目中经常使用哪些列表的命令呢?
面试者:“雕虫小技,我都已经整理好了的,难不倒我的!”。恩,可以的!
1.添加insert指令操作:
lpush指令:lpush key value ... 从左边插入元素(将一个或多个值插入到列表头部);时间复杂度O(1)。
rpush指令:rpush key value ... 从右边插入元素(将一个或多个值插入到列表的尾部(最右边));时间复杂度O(1)。
linsert指令:linsert key before|after pivot(指定元素) value(插入值) 向某个元素前/后插入元素,返回结果为当前列表长度,注意列表不存在或者指定元素不存在列表中时,都将不执行任何操作。时间复杂度O(n),n为寻找指定元素中经过的元素数量。2.查找select指令操作:
lrange指令:lrange key start end 获取列表中指定范围内的元素列表;若start值大于列表end值则返回空列表;时间复杂度O(s+n) s为偏移量start,n为指定区间元素数量。
lindex指令:lindex key index(可负值) 获取列表指定索引下标的元素;时间复杂度O(n),n为到达下标index过程中经过的元素数量;列表头部和尾部元素获取,时间复杂度O(1)。
llen指令:llen key 获取列表长度;列表不存在则返回0,时间复杂度O(1)。
3.删除delete指令操作:
lpop指令:lpop key 从列表左侧弹出元素并返回头部元素;时间复杂度O(1)
rpop指令:rpop key 从列表右侧弹出元素并返回尾部元素;时间复杂度O(1)
lrem指令:lrem key count value 从列表中找到等于value的元素进行删除,根据count的不同分为三种情况,时间复杂度O(n),n为列表的长度:
count > 0,从表头开始向表尾,移除数量为count个元素;
count < 0,从表尾开始向表头,移除数量为count的绝对值个元素;
count = 0,移除表中所有与 value 相等的值;
ltrim指令:ltrim key start end 按照索引范围修建列表,相当于切片操作;时间复杂度O(n),n为被移除的元素的数量。4.修改update操作:
lset指令:lset key index value 修改指定下标的元素的值设置为value;时间复杂度:① 对头元素(第一个)或尾元素(最后一个)进行操作时,复杂度为O(1)。② 其他情况下,复杂度为O(n),n为列表的长度。5.阻塞block指令操作:
blpop指令:blpop key [key ...多个key] timeout 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止;时间复杂度O(1)。
brpop指令:brpop key [key....多个key] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止;时间复杂度O(1)。面试官:“我去,这这这...整理的这么详细,还按照同类功能划分,看来是下功夫了!”。从你的回答来看还是有点功底的,那么我想知道使用这些指令是如何考虑什么场景下使用什么列表指令来实现?
3.2 列表的使用场景
面试者:“又开始老套路了,又开始问我使用场景了,又开始问我项目用到哪些功能了,我真的只有一年经验呀,回忆下看过的文章,做过的项目”。支支吾吾说:目前我工作中使用到了一下场景:消息队列、延迟消息队列、关注列表、粉丝列表、人气榜单、热点新闻等等。目前我做过的项目大概就用过这几种场景,除了消息队列用的不是很多(一般都用rabbitmq、kafka)。
面试官:“咦,用的场景还怪多嘞,看来还要继续追问下,如何实现的”。哦哦,那么能问下,你项目中是怎样具体实现这些功能的嘛,有没有什么弊端?
面试者:“面目表情已经逐渐变化,一股怒火即将冲上天,难道我是大神嘛,咋还要继续深入了解呢?心不甘情不愿的开始讲解”。以下是我在实际项目中使用场景介绍和代码展示。
3.2.1 人气榜单+热点新闻
我们在实际项目中会有这样的要求,每个月/星期会重新计算生成一份活动排行榜的列表展示。可以使用lpush+lrange来实现排行榜。假如我们有一个抽奖活动,展示最近20个抽中奖励的人,做全站高亮轮播;那么可以使用lpush+ltrim+lrange来实现。注意点:如果我们的数据实时更新,那么就不可以list列表存储,相应的要改用有序集合sorted set(下下章节会介绍)实时计算榜单数据。下面是热点新闻排行案例与代码实现:
/**
* @desc 列表案例一 热点新闻 固定列表长度 维护列表长度
* @param array $data 需要加入队列的数据
* @return bool|int
*/
public function hotNewsRank($data = array())
{
if (!$data || !is_array($data)) return false;
$data = json_encode($data);
$key = sprintf('every:month:hot:news:%s', date('%Y%m'));
// 每月热点新闻只展示前10条
$length = $this->redis->lLen($key);
if ($length >= 10) return false;
$result = $this->redis->lPush($key, $data);
return $result;
}面试官:“实战中讲的还是不错的”。那么问你下,这种类似排行或者粉丝列表的情景;list类型能做到的 sorted set类型同样可以做,甚至有序集合比list做的更多,那么为什么你在做热点新闻或者粉丝排行榜时是怎么考虑选择使用类型的?
面试者:在做热点新闻时,之所以不选择使用有序集合,最根本原因是sorted set 类型占用的内存空间是列表的多倍。其原因就是list和sorted set底层实现方式复杂度不同。① list底层使用压缩列表或链表来实现,当列表对象保存的所有字符串元素的长度都小于64字节,并且列表对象的元素数量小于512字节时,list对象使用ziplist编码,否则使用linkedlist编码;可以看出它只会使用一种编码格式。② sorted set 底层使用了ziplist(压缩)和skiplist(跳跃表),当元素数量小于128个,并且所有元素成员的长度小于64字节时,使用ziplist编码,否则使用skiplist编码;如果排序需要O(nlogn)的时间复杂度,以及额外的O(n)的内存空间。相对来说列表更适合这种固定不变化的数据存储。
面试官:“不错不错,竟然知道列表和有序集合的底层编码实现方式,看来是没少了解学习”。微微点点头,肯定的说:说的不错,确实在做项目功能时,一定要根据实际的场景选择对应的存储方式,尽量使用较优选的方案,这样对自己也是一种提升。还有没有要补充的场景方案呢?
面试者:你好,有的!也就是大家经常挂在嘴边的消息队列和消息延迟队列,下面我也简简单单的聊一下这个队列。
3.3.2 消息队列
目前市场已经有了专门做消息队列的成熟工具rabbitmq、kafka、rocketmq等,他们的功能比较完善,也拥有ACK机制以及死信队列机制等等。那么我们为什么还要使用redis做队列呢?我想应该有以下几点:① 公司规模不是很大redis现有的队列可以满足需求;② 对队列消息的要求可靠度不高,丢了就不管了;③ 消息的数据量没有上千万上亿级别,redis完全可以支撑满足;④ 公司没钱搞,需要机器,需要成本,需要人力,如果原有机器可以满足就不折腾。
那么假如对消费者的服务器在处理消息的时候出现异常,可能消息还没有处理完成,数据就丢失了;如果对这种数据不是很在意,不需要有消息确定机制,那么我们完全可以使用redis实现,并不是像网络上说的,redis不适合做队列,要用kafka一类的消息队列。其实并不反对这么说:的确,消息队列本身就不是redis的强势所在,可能各有所好吧。
面试者:通常我们会使用rpush+lpop来做队列,rpush生产消息,lpop消费消息,然后开启多进程去跑脚本处理队列,下面是消息队列的流程图。
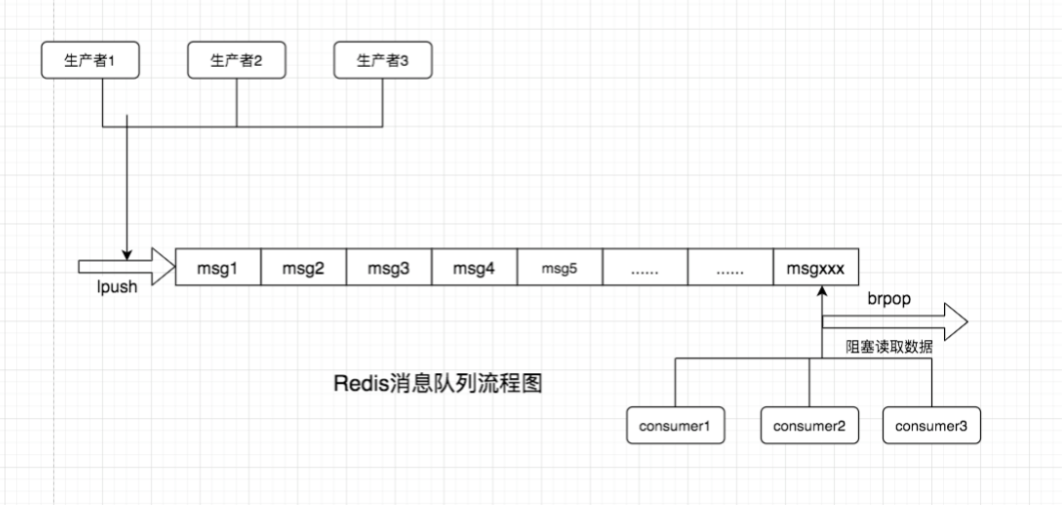
面试官:那么,假如你的队列被消耗空了,但是有没有新的数据产生,就会导致脚本一直在pop进入死循环,这是在消耗服务器的资源,增加了cpu的消耗,当然redis的qps可能也会增高,这个时候你该怎么办呢?
面试者:额,,,这个嘛,支支吾吾的说道:一般我们可以在pop为空数据的时候,适当的增加一个sleep休眠期,例如0.5s,那么这样cpu的消耗就会较小。
面试官:那你有没有考虑到,如果sleep阻塞当前消息处理线程,可能会导致整个消息出现延迟;这样的话,我们又该怎么办,是否还有其他的处理方案呢?
面试者:“我真是服了,我真想一棒槌 打晕你,干嘛要问的这么详细,我真的是醉了,都想跑路了”。咳嗦咳嗦两声喝口水克制一下,然后神态自若的回答道:我在上面的问题上已经回答你了,可以使用list的blpop、brpop指令来实现阻塞读取数据。当队列没有数据时,会进入休眠状态;当队列有数据来时,则唤醒过来,那么消息基本上就不会被延迟处理了。
面试官:“已经回答的很不错了,这个小伙子虽然一年经验,但是看上去很老成的样子,也不往深追问了”。不错不错,基本上回答的很ok了。那么可以再问你最后一个问题嘛,你是如何使用延迟队列来处理消息呢,你的场景是什么样的?
/**
* @desc 队列生产者
* @param string $qname
* @param array $data
* @return bool
*/
public function push($qname = '', $data = [])
{
if (!$qname || !$data) return false;
if (!is_array($data)) $data = json_encode($data);
// 进入队列
$result = $this->redis->rPush($qname, $data);
if ($result) return true;
// 此处可以增加一条失败队列 处理 或者记录日志 方便后续处理 或者增加告警
return false;
}/**
* @desc 消息队列实现 部分代码
*/
while (true) {
$info = $this->redis->lPop($qname);
if (!$info) break;
$data = json_encode($info, true);
if (!$data) break;
$run_count = $run_count + 1;
$retval = call_user_func_array($handler, [$data, $qname]);
if ($retval) break;
if (time() - $start_time > $max_runtime) break;
}以上则是实现消息队列的部分代码,详细代码请在结尾处查阅。
3.3.3 延迟队列
通俗一点的讲:延迟队列就是把队列里的消息体延迟处理,常用的场景有:订单超时取消、游戏超时检测等等,本身也可以结合自己的项目判断是否使用延迟队列。在以往没有rabbitmq、kafka等消息队列的出现,大部分都是基于linux的crontab来定时每分钟执行脚本,从mysql查询指定未付款状态的订单轮询解析处理。这样是很消耗性能的,这样也会增加mysql的压力,如果数据量上百万的订单里,查询未支付状态订单,显然会越来越慢,大家可能会想着加索引,分表。但当你表数据增加到上千万的时候,性能很难在调优。那么redis的引入就能很好的解决这个问题(且不说目前主流做消息的消息中间件多么的好,现在讲的是redis)!
目前看到网上绝大部分甚至是一些书籍描述的redis延迟队列:千篇一律都是在讲使用zset(有序列表)来实现。我大致描述他们所使用的流程:① 将消息序列化字符串作为zset的value ② 将消息的到期时间作为score ③ 开启多个线程轮询去获取检测处理。
首先我并不是不认同这种做法,只是觉得这种做法不太可靠。① zset集合存储数据所占内存远大于list ② 假如消息体比较大,是不是会影响zset的排序性能 ③ 多线程跑必然会引起并发争抢任务,会导致任务被多次执行(当然这个可以使用redis执行lua脚本语言进行原子操作可以解决
下面是不同于zset的一种实现redis延迟队列的使用案例:
while (true) {
$info = $this->redis->lPop($qname);
if (!$info) break;
$data = json_encode($info, true);
if (!$data) break;
$delay_time = isset($data['delay']) ? $data['delay'] : 0;
if ($delay_time <= 0) break;
if ($delay_time > time()) {
$res = $this->redis->lPush($qname, $info);
if ($res) {
$length = $this->redis->lLen($qname);
if ($length > 10000) { // 队列积压严重
// todo 短信告警开发人员 处理
} else {
// todo 失败落入日志文件 人为介入 或者定时检测日志文件数据 重新消费
}
}
break;
}
// 处理逻辑
$run_count = $run_count + 1;
$retval = call_user_func_array($handler, [$data, $qname]);
if (!$retval) break;
if (time() - $start_time > $max_runtime) break;
}面试者:我自己在平常项目中是这样使用延迟队列的,通过push队列数据时,给消息体增加一个delay到期的时间,每次pop出来,解析数据拿到delay跟当前时间戳进行对比,判断是否到期;到期则根据对应逻辑处理,否则重新丢进队列尾部进行消费,我们只需要保证消息队列能不阻塞,能正常的消费完即可。
面试官:你分析的挺细致的,考虑问题也很周全,并不是只有一种方案,这些都是在实际项目中实践才能体验出方案的可行性,以你目前的经验能想到这样做,挺不错的。
PS:面试官暗地里已经对你竖起了大拇指。但是他却不知道的是此刻你却竖起了中指,在椅子背后!
最后总结
面试者:面试官你好,请问这次我的回答是否有不足的地方,还有哪些需要改进,还望你指点出来。
面试官:其实呢,你是我最近面试过几个开发中经验最少,但是基础最扎实的一个。你的基本理论都很ok的,有些列表的实际使用,感觉你还需要加强实践能力,多多的实践才能提升技术。对于你的回答我是肯定的,也期待下面的回答能更好!
总结:我们通过一系列的一问一答的形式,来展示redis的列表使用以及场景,是为了更好地带领大家进入探讨、思考、理解。可能讲的并不是很全面,或许有点浅,实际上本就是一个由浅入深的一个过程,只有我们脚踏实地的去了解运用这些基础知识,才能更好地扩展开来。那么大家有不一样的看法,可以留言哦!
代码地址:https://github.com/woshiamu/amu
好了,我是阿沐,一个不想30岁就被淘汰的打工人 ⛽️ ⛽️ ⛽️ 。