
二分查找是一种非常简单易懂的快速查找算法,生活中到处可见。比如说,我们现在来做一个猜字游戏。我随机写一个0到99之间的数字,然后你来猜我写的是什么。猜的过程中,你每猜一次,我就会告诉你猜的大了还是小了,直到猜中为止。你来想想,如何快速猜中我写的数字呢?
无处不在的二分思想
二分查找是一种非常简单易懂的快速查找算法,生活中到处可见。比如说,我们现在来做一个猜字游戏。我随机写一个0到99之间的数字,然后你来猜我写的是什么。猜的过程中,你每猜一次,我就会告诉你猜的大了还是小了,直到猜中为止。你来想想,如何快速猜中我写的数字呢?
假设我写的数字是23,你可以按照下面的步骤来试一试。(如果猜测范围的数字有偶数个,中间数有两个,就选择较小的那个。)
7次就猜出来了,是不是很快?这个例子用的就是二分思想,按照这个思想,即便我让你猜的是0到999的数字,最多也只要10次就能猜中。不信的话,你可以试一试。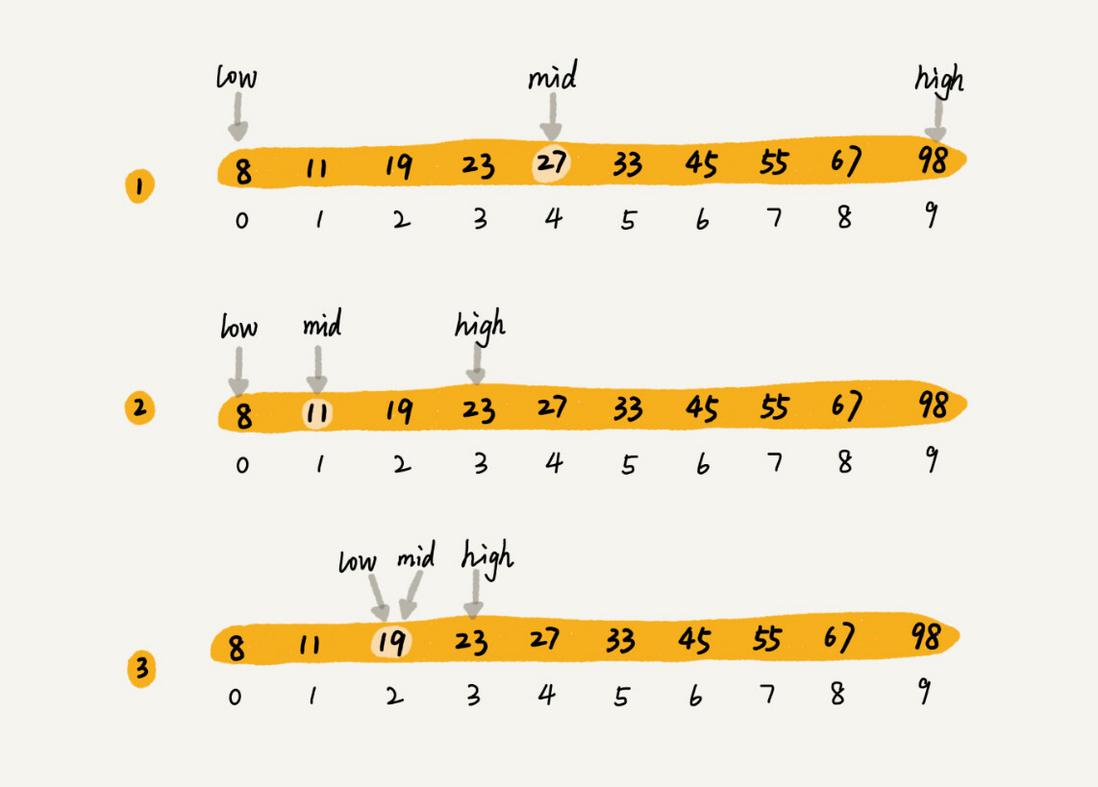
看懂这两个例子,你现在对二分的思想应该掌握得妥妥的了。我这里稍微总结升华一下, 二分查找针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为0。
二分查找惊人的查找速度
二分查找是一种非常高效的查找算法,高效到什么程度呢?我们来分析一下它的时间复杂度。我们假设数据大小是n,每次查找后数据都会缩小为原来的一半,也就是会除以2。最坏情况下,直到查找区间被缩小为空,才停止。
可以看出来,这是一个等比数列。其中n/2k=1时,k的值就是总共缩小的次数。而每一次缩小操作只涉及两个数据的大小比较,所以,经过了k次区间缩小操作,时间复杂度就是O(k)。通过n/2k=1,我们可以求得k=log2n,所以时间复杂度就是O(logn)。
完整内容请点击下方链接查看:
“二分”带来“十分”快感——二分思想的奥秘解析
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。











