
最近又再次回顾了iliyan GeorgeV的light transport course,感觉对于算法背后的思想方法和数学原理又有了很多的启发和思考,因此写下来权当记录。
渲染问题的本质是解渲染方程,实际上也就是解光场在场景中与材质表面相互作用的结果和分布,用数学上的话来说实际上也就是解一个光的路径积分的问题,蒙特卡洛方法去解决也就是朝场景发射光线,然后与表面相互作用,如果击中光源就得到辐射值,最后取均值。这种方法的核心问题在于当光场复杂场景复杂时,盲目而均匀发射的光线样本很难打中光源而成为有效样本(反弹的深度达到了限制,或者能量被吸收干净),造成最终结果的噪声很大。所有的light transport方法的目的就是去把握这个复杂而且未知(在你开始渲染之前你没法知道)光分布的重要性,从而更有效的发射样本解决问题。
光场分布的复杂性是不言而喻的,不仅光源可以分很多种,数目也可以很多,材质表面的复杂属性也可能导致光的分布被改变,最典型的就是焦散。light transport方法解决的问题有点类似先有鸡还是先有蛋的问题,只有当你渲染完成之后你才能知道这个高维函数真实的样子,但是你又必须了解这个函数的样子从而去根据他的形状在强的地方多发射些样本。
这类问题实际上在科学计算领域比较常见,因此现有的很多方法都是借鉴了科学计算中的方法,大体来说可以分成两类,一类属于经典蒙特卡洛方法,另一类是mcmc,也就是利用了markov chain monte carlo。当然以后肯定还有更多的算法和更多学科之间的交叉出现。
先来看最简单的path tracing,前面已经提到过,path tracing是向场景中发射光线并希望他能够顺利打中光源产生贡献,这种方法一般在科研领域叫做implicit sampling(光源并不一定能被击中)问题在于这种方法收敛速度很慢,一个很常见的改进就是所谓的explicit sampling,也就是在每一个光线与物体表面交到的点进行一次与光源的连接尝试,如果没有遮挡(科研上一般把这种光线称为shadow ray)就把这两种结果按照MIS的方式结合(之前的文章说到过,这是一种结合两种采样方法的方式)。这样的改进实际上增加了有效样本的概率(利用了光源的信息)因此提高了收敛速度。

Bidirectional path tracing:刚才所说的方法实际上在复杂场景中,或者存在着caustic路径的场景中依然是效果很差的,想象一个主要用间接照明照亮的场景,上面的两种方法都很难得到击中光源的样本。不过shadow ray的思想实际上启发了BDPT的算法,如果我们从光源和摄像机都发射光线,并且在它们每前进一步的时候都尝试去用shadow ray连接两个端点,那么我们找到有效的光的采样方法的概率就增大了很多。
如图所示,实际上我们可以想象这所有的对光路径采样方式的集合构成了一个空间(也就是所谓的path space)但是在这个路径空间中由于场景的复杂性我们没法知道哪种方法是最好的,哪种方法又几乎打不中光源,因此最保险的方法就是每种都进行一次尝试,然后把所有的结果结合起来,这也就是bidirectional的核心思想了。
BDPT已经是一个非常鲁棒的算法,能够应对大部分的复杂光照和场景,不过如果你细心的话肯定会想到如果这所有的采样方式都很差怎么办?那这种情况下BDPT的效果不是与Path tracing一样糟糕么?很遗憾,这种场景真的存在。
考虑一个阳光照耀下的水池的光路:
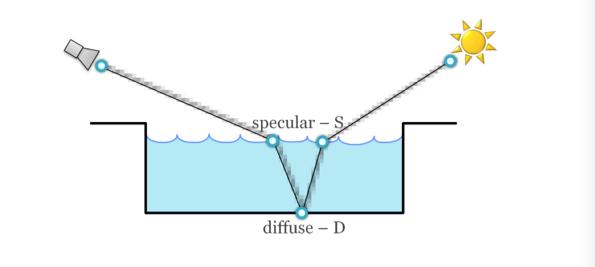
然后尝试着用我们的connection的方法去连接路径中的每个节点,我们会发现,每一种连接都没法进行,因为纯镜面和diffuse之间没法进行shadow ray 连接(或者说连接总是失败)而从光源发出的光没法打中我们理论上无限小的相机,于是我们唯一的希望只能靠从摄像机发出的光线,希望他能随机打中光源(没有更好的采样方式了)那么如果光源体积很小的情况下,情况就会很糟,收敛速度就会狠惨不忍赌,这也就是科研文章常提到的SDS路径。
Vertex Connection and merging: 对于上面的问题一种很明显的思路就是既然我们的连接失败,那把连接的条件放宽可不可以呢?但是放宽的连接条件怎么去精确近似纯镜面呢?这样的方法真的可以有,最近提出的VCM方法就是这个思路:

图中的x1和x2之间的连接是很困难的,因为一个是纯镜面,一个是diffuse,但是假如现在我们从x1发射光线得到交点x2‘并且对于一定半径内的x2 x2’我们把他当成一个vertex,那么我们得到有效采样方法的概率自然就大很多。
换个角度看图的右边,我们会发现这种方法与另一种统计有偏的渲染方法photon mapping有类似之处,VCM把左边类似BD的方法叫做vertex connection, 右边类似photon mapping 的方法叫做vertex merging,而VCM等于是再次在两种方法之间做了一个结合(MIS)在Vertex connection效果好的地方用connection,而在Vertex connection失效的地方用merging.
那么对于merging造成的偏差,VCM采用的是逐步缩小merging的半径来达到最终的一个统计无偏结果。
实际上merging的优势并不是在于他的采样方法比传统方法效率高,而在于他能够重用大量的light path,通过查找photon map的方法用同样的光线实现巨大量的样本收集(空间换时间)。这些实现细节具体可以参阅论文。
VCM能很好处理SDS路径问题,在各种场景中的适应性都比较好。但是我们也看到从PT到BD到VCM算法实现的复杂性越来越高,VCM还需要巨量内存支持photon map,所以工业界基本上还停留在PT的阶段(因为它足够快,适应性强)如何找到这些高级算法和实际生产的结合点,还很值得研究。
从以上的论述中可以看出传统蒙特卡洛方法的特点:暴力搜索每一种可能的采样方法,尽量避免完全靠随机采样去击中目标,如果我们把思路扩展到机器学习和优化理论上的话,就会发现这些方法都是力图求一个local的最优解,换句话说,这些方法找到的有效路径往往是local最优的,如果跳出这个local的限制,每次都尝试去寻找全局最优的采样方式呢?MLT就是把metropolis hasting 算法应用在light transport中的一种算法,下一篇再说把。。





