
小 T 导读:对于青岛协同创新金融研究院来说,一直打交道的交易记录、价格等数据均为时序数据,在选择数据库(Database)时,TDengine “一个设备一张表”的设计吸引了他们的目光。目前 TDengine 已经在其生产系统中稳定运行了 38 周。本文总结了他们在选型、搭建等方面的所思所想,以及应用 TDengine 之后所取得的效果。
企业简介:
为切实服务国家经济、金融发展,中国金融量化科学与技术协同创新中心在山东青岛设立了一个高端智库,即青岛协同创新金融研究院。依托于创新中心的国际顶级专家资源、在量化金融与金融科技领域的国际领先理论研究与实务技术成果,研究院致力于促进我国金融领域创新型尖端理论人才、适用性高端技术人才的教育与培养,提升相关领域在风险管理、资产定价、产品设计等各方面的定量分析与决策技术水平,积极维护金融稳定、促进金融发展。
开门见山地说,我们选择 TDengine Database 的理由很简单——“一个设备一张表”的模型很适合我们的量化分析场景。本质上来讲,交易记录、价格等都是时序数据,其实就是“一只股票一张表”,所以十分契合。
在我们的业务场景中,TDengine 主要负责三点:一是对回测的数据支持,因为它可以轻松抗住海量数据的写入。目前我们的数据入库方式是使用 Python 连接器直接写入 TDengine(6030 端口)。具体方式为:会通过券商的直连接口将他们提供的数据做一个 SQL 拼接,利用拼接 SQL 的方式,单个 SQL 写入几千行数据,将大批数据一次性写入到一个表中。目前,我们每天新增数据量大概在 2000 万行左右。
(注:股票回测是指设定了某些股票指标组合后,基于历史已经发生过的真实行情数据,在历史上某一个时间点开始,严格按照设定的组合进行选股,并模拟真实金融市场交易的规则进行模型买入、模型卖出,得出一个时间段内的盈利率、最大回撤率等数据。)
二是基于以上数据进行的回测数据分析。
三是部分盘中策略的数据预加载。
但因为这块有每秒几万次的查询用在高频业务上,所以暂时还没有尝试应用 TDengine,目前大部分盘中业务使用的还是 Redis。据社区工作人员表示,未来的 TDengine 3.0 版本将会支持自定义时间范围的缓存,届时或许可以帮到我们。
除了上述主要的使用场景之外,TDengine 还帮助我们实现了部分深度学习模型的数据训练和测试。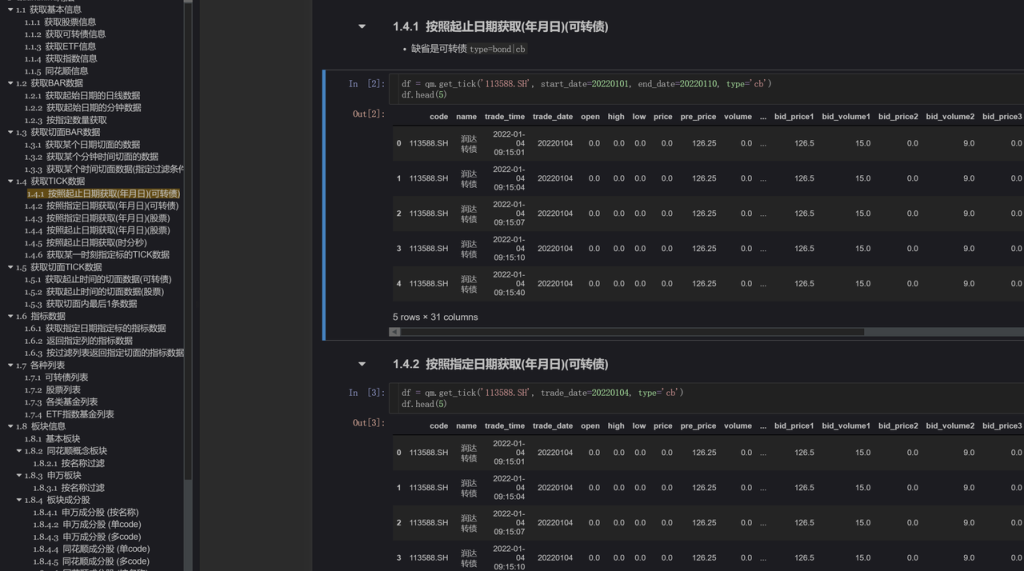
具体落地与实际效果
在目前的业务中,我们选用了三台 8 核 16G 服务器,以此搭建了三副本的集群。
这里大家需要注意,三节点并不代表三副本,也并不代表你的数据库已经具备了高可用性。数据库的高可用是在 "create database xxxx replica 1/2/3" 的过程中指定的,但是如果你忘记了也没关系,后期可以通过 "alter database xxxx replica 1/2/3" 来动态地进行调整。TDengine 会自动复制出一批分片(Vnode),并均匀地分布在各个节点之上,效果如下”show 库名.vgroups”所示。
(注:如果数据量很大,在数据同步的过程中由于网络波动导致数据文件复制中断,也可以手动复制 Vnode 目录下的文件到指定节点再启动。)


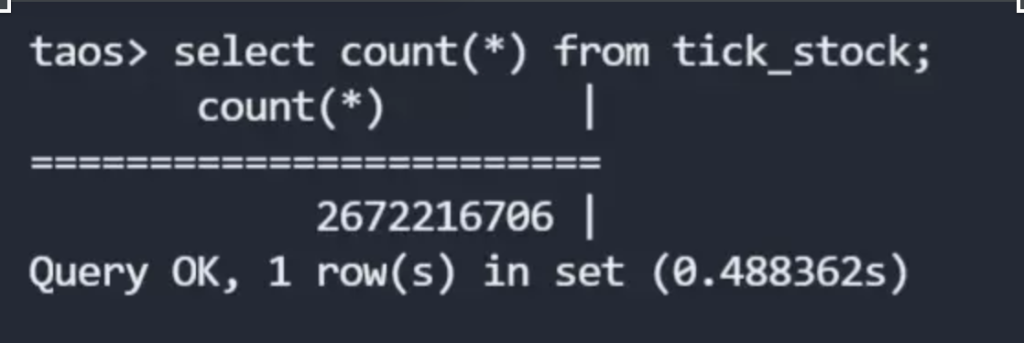
根据不同类型的业务,我们创建了 7 张不同的超级表,子表数量为 33076 张,目前我们导入的数据总量已经达到了 46 亿之多,其中最大的一张超级表达到了 26 亿行,实际磁盘占用大概在 130GB 左右。表的列数如下图”columns”所示,数据类型以 Float 为主。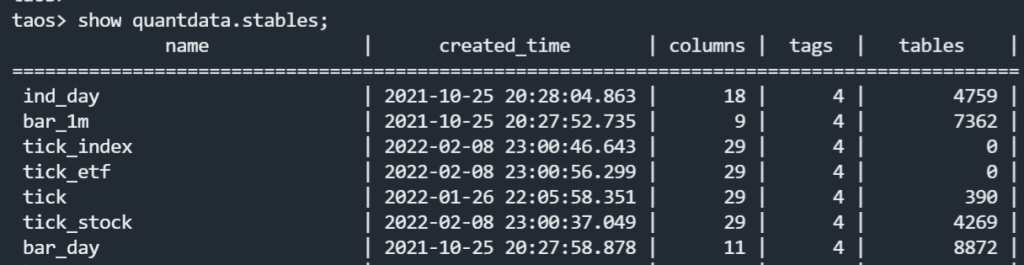

下面我再列举一些典型的查询场景:
select first(open), max(high), min(low), last(close), sum(volume), sum(amount) from 'bar_1m_SH600519' where trade_time >= '2021-12-25 09:30:00' and trade_time <= '2021-12-31 15:00:00' interval(30m) fill(null)下图为用 1 分钟的 bar 数据合成 30 分钟的 bar 数据,查询出的茅台股票在一段时间内的开盘价、最高价、最低价、收盘价。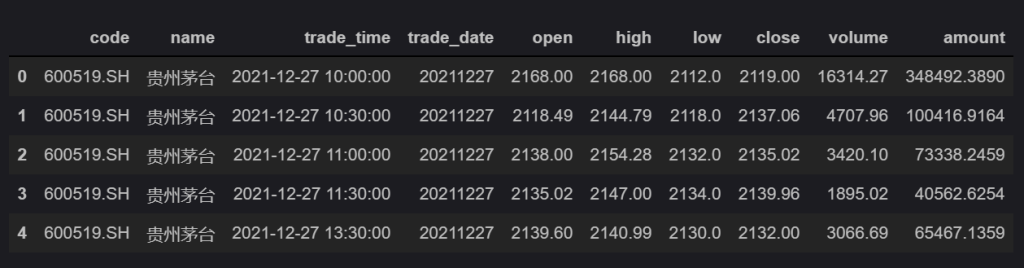
select code,name,trade_time,trade_date,open,high,low,price,pre_price,volume,amount,ask_price1,ask_volume1,ask_price2,ask_volume2,ask_price3,ask_volume3,ask_price4,ask_volume4,ask_price5,ask_volume5,bid_price1,bid_volume1,bid_price2,bid_volume2,bid_price3,bid_volume3,bid_price4,bid_volume4,bid_price5,bid_volume5 from tick_stock where trade_time >='2022-03-18 09:30:00' and trade_time <='2022-03-18 09:30:02' and code in ('002429.SZ', '000006.SZ')下图为查询某两支股票在某个时间范围内的 tick 数据。
期待 TDengine 3.0 版本
除了数据库本身的功能之外,我们也注意到 TDengine 的周边生态也在不断完善。在 2.4 版本发布之后,它实现了很多功能更新,其中包括一款使用了监控数据库(log 库) + Grafana 对 TDengine 进行监控的解决方案——TDinsight。在此之前,我们使用的一直是我自己编写的一款监控程序,但 TDinsight 使最终的展示效果更加清晰直观,数据库的运行状态也更加一目了然。
于是,我们立刻着手更新了 TDengine 2.4 版本,并且部署了 TDinsight。
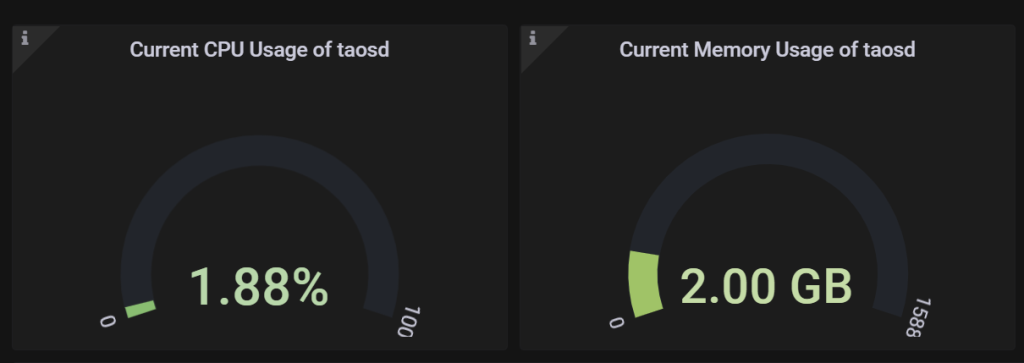
以下就是 Grafana 展示界面的一部分,可以看到,在当前并发写入的规模下(每秒 1 万-1.5 万行),CPU 资源占用率只有 1.88%,内存占用只有 2G。尽管目前我们使用的是三台 8 核 16G 的机器,但却可以在相当长的时间内不用再担心硬件资源问题了。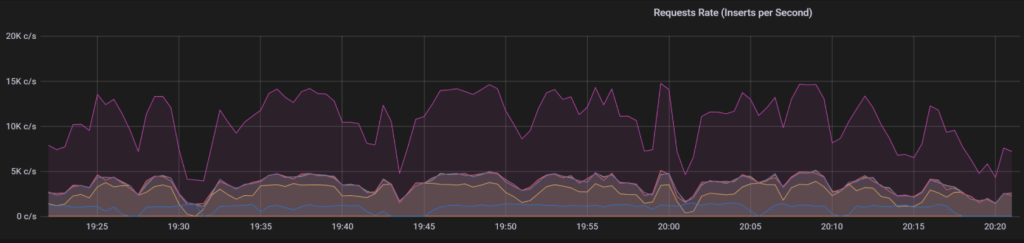
不知不觉中,TDengine 在生产系统中已经跑了 38 周了,整体来说各方面性能都不错。偶尔遇到的一些使用问题,也在 TDengine 社区得到了及时的帮助和解答,运行至今我们发现了两个小 Bug,官方都很快响应处理了。尽管还有一些场景在当前的 2.0 版本还并不能完全适配,但 3.0 版本出炉后就可以解决了。
最后祝 TDengine Database 越来越好吧,期待 3.0 版本的发布让它成为时序数据库里的 Oracle。
作者:
William (QQ: 392667) 16 年股票投资经验,15年软件开发经验,负责青岛金融研究院量化系统整体架构,以及相关高频交易模型的开发。
想了解更多 TDengine Database 的具体细节,欢迎大家在GitHub上查看相关源代码。














