
自适应自旋锁:(java6引入,jvm对锁的预测会越来越精准,jvm也会越来越聪明)
- 自选次数不再固定
- 由前一次在同一个锁上的自旋时间及锁拥有者的状态来决定(如果在同一个锁对象上自旋等待刚刚成功获取过锁并且持有锁的线程正在运行中,jvm会认为该锁自旋获取到锁的可能性很大,会自动增加等待时间,相反jvm 如果可能性很小会省掉自旋过程,避免浪费)
锁消除:jvm的另一种锁优化,更彻底的优化
- JIT编译时,对运行上下文进行扫描,去除不可能存在的竞争的锁,消除毫无意义的锁
锁粗化:另一种极端,锁消除的作用在尽量小的范围使用锁,而锁粗化则相反,扩大加锁范围。比如加锁出现在循环体中,每次循环都要执行加锁解锁的,如此频繁操作比较消耗性能
- 扩大加锁范围,避免反复的加锁和解锁
synchronized的四种状态
- 无锁
- 偏向锁
- 轻量级锁
- 重量级锁
锁膨胀方向:无锁->偏向锁->轻量级锁->重量级锁,synchronized会随着竞争情况逐渐升级,如出现了闲置的monitor也会出现锁降级
偏向锁:减少同一个线程获取锁的代价
- 大多数情况下,锁不存在多线程竞争,总是由同一个线程多次获得
ps:核心思想就是如果一个线程获得了锁,那么锁就进入偏向模式,此时MarkWord的结构也变成偏向锁结构,当该线程再次请求锁时,无需再做任何同步操作,即获取锁的过程只需要检查MarkWord的锁标记位为偏向锁以及当前线程ID等于MarkWord的ThreadID即可,这样就省去了大量有关锁申请的操作
不适合用于锁竞争比较激烈的多线程场合
轻量级锁:
轻量级锁是由偏向锁升级而来的,偏向锁运行再一个线程进入同步块的情况下,当第二个线程加入锁争用的时候,偏向锁就会升级为轻量级锁
适用场景:线程交替执行的同步块
若存在同一时间访问同一锁的情况,就会导致轻量级锁膨胀为重量级锁
轻量级锁的加锁过程:
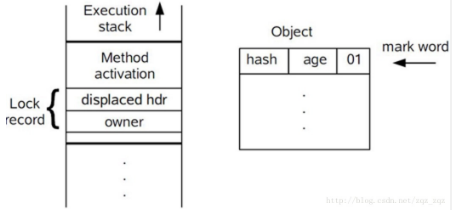 此图来自https://blog.csdn.net/zqz\_zqz
此图来自https://blog.csdn.net/zqz\_zqz
- 在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间(线程私有的栈帧里),用于存储锁对象目前的Mark Word的拷贝(对象是存在堆中的,所以对象的MarkWord也再堆中),官方称之为 Displaced Mark Word。
- 拷贝对象头中的Mark Word复制到锁记录中;
- 拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock record里的owner指针指向object mark word。如果更新成功,则执行步骤4,否则执行步骤5。
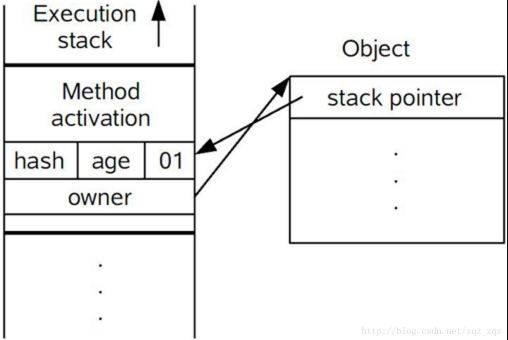
- 如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈与对象头的状态如图所示。
- 如果这个更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。 而当前线程便尝试使用自旋来获取锁,自旋就是为了不让线程阻塞,而采用循环去获取锁的过程。
锁的内存语义
- 当线程释放锁时,java内存模型会把该线程对应的本地内存中的共享变量刷新到主内存中
- 当线程获取锁时,java内存模型会把该线程对应的本地内存置为无效,从而使得被监视器保护的临界区代码必须从主内存中读取共享变量
总结:













