
自 Apache Doris 1.1.0 版本发布距今已经有数月之久,在这一期间,我们重新思考并确立了社区新版本发布的流程,正式引入了 LTS (Long-Term Support,长周期支持)版本的概念,在 1.1.x 系列版本中不再引入大的功能 Feature、仅提供问题修复和稳定性改进,力求满足更多社区用户在稳定性方面的高要求。值得高兴的是,这一行动已经有了明显的成效,目前 1.1.x 系列最新版本的稳定性经受了众多用户生产环境的考验。
而在综合考虑版本迭代节奏和用户需求后,我们决定将众多新特性在 1.2 版本中发布,这其中既包含了在性能方面的优化改进,也包含了诸多社区用户期待已久的功能。经历了漫长的开发、测试、调优等工作后,我们很高兴地告诉大家,Apache Doris 1.2.0 版本已经进入最后的发版准备阶段,预期将于 12 月的第一周与大家见面。
对于社区用户最为关心的性能方面的提升,我们基于 1.2.0 RC(Release Candidate,候选发布版本)进行了多个标准测试集的测试,同时选择了 1.1.3 版本和 0.15.0 版本作为对比参照项。
经测,1.2.0 RC 版本在 SSB-Flat 宽表场景上相对 1.1.3 版本整体性能提升了近 4 倍、相对于 0.15.0 版本性能提升了近 10 倍,在 TPC-H 多表关联场景上较 1.1.3 版本上有近 3 倍的提升、较 0.15.0 版本性能提升了 11 倍以上,多个场景性能得到飞跃性提升。
与此同时,我们将 1.2.0 RC 版本的测试数据提交到了全球知名的数据库测试排行榜 ClickBench,在最新的排行榜中,Apache Doris 以亮眼的性能表现登上榜单前列,取得了全球同类产品导入性能综合排名第一、通用机型(c6a.4xlarge, 500gb gp2)下查询性能 Cold Run 第二和 Hot Run 第三的成绩!
关于 ClickBench
ClickBench 是由知名分析型数据库 ClickHouse 发起的性能测试排行榜,在 ClickBench 性能排行榜中,测试数据均取自真实生产环境、涵盖数据类型多样、覆盖了即席查询和统计报表等典型场景,能真实反映各大数据库在生产环境中的性能,因此吸引了 Snowflake、Redshift、Athena、Greenplum、Druid 等国际知名数据库的参与。所评测的指标为特定机型下导入相同数据集的时间、所占用的存储空间大小以及执行 SQL 的耗时长短,分别用以衡量 数据导入性能、数据压缩比以及查询性能。所有测试结果中表现最优的一条会成为基线,相同测试项的指标会与基线数据进行对比并得出比值,通过这一比值来体现与行业最优的差距。当有新的测试结果超越原有的基线后,将自动成为新的基线。
就查询性能而言,会分别对每条 SQL 执行 Hot Run 和 Cold Run 来统计时长,即重复执行 3 次 SQL 并取其中耗时最短的一次以及启动并清理内存后直接执行,最终对所有 SQL 的执行耗时与基线的比值进行几何平均,即为最终测试结果。因此 ClickBench 更关注的是数据库在所有测试场景下都有着优异的表现,而非某一个或某几个场景,这使得数据库需要全方位的能力提升。
在本次提交的测试结果中,查询性能方面, Apache Doris 在未进行任何调优的情况下, Cold Run 取得同机型所有产品第二名的优异成绩,Hot Run 位列同机型所有产品第三,共有 8 个 SQL 刷新榜单最佳成绩、成为新的性能标杆。导入性能方面,Apache Doris 数据写入效率在同机型所有产品中位列第一,压缩前 70G 数据写入仅耗时 415s、单节点写入速度超过 170 MB/s,在实现极致查询性能的同时也保证了高效的写入效率!
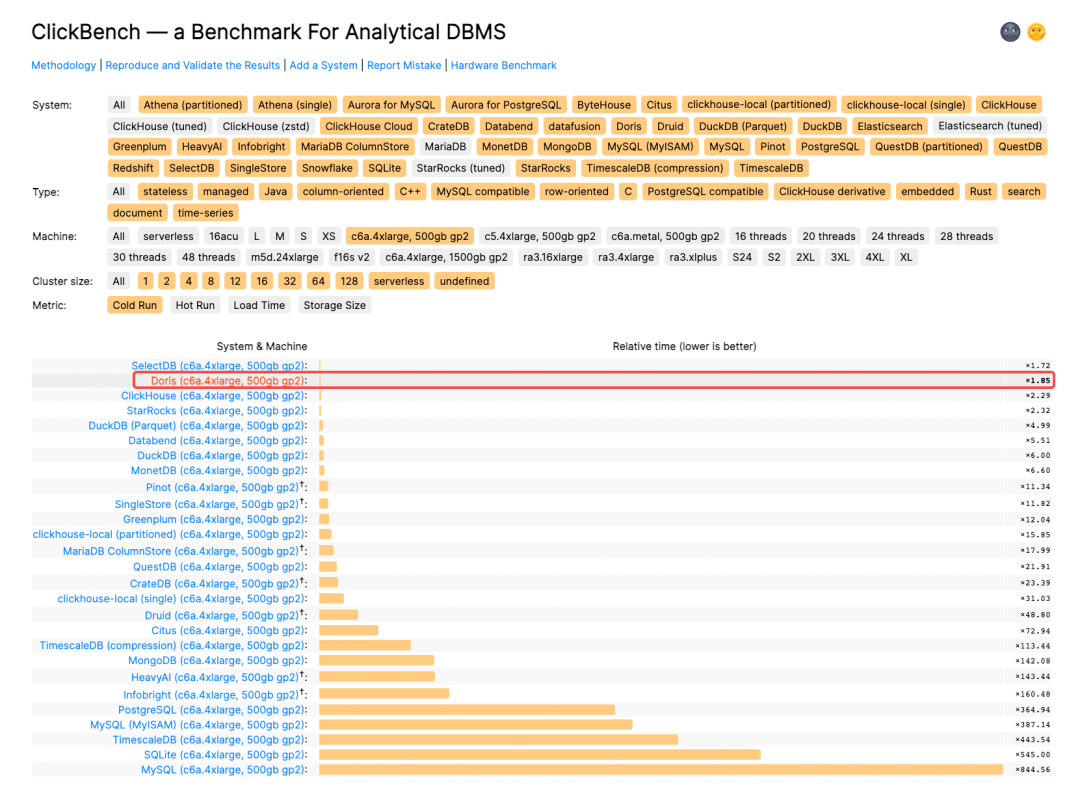
图1 Cold Run

图2 Hot Run

图3 Load Time
点击链接 :https://benchmark.clickhouse.com 前往查看
关于 SSB
Star Schema Benchmark(SSB) 是一个轻量级的数仓场景下的性能测试集。SSB 基于 TPC-H 提供了一个简化版的星型模型数据集,主要用于测试在星型模型下多表关联查询的性能表现。另外,业界内通常也会将 SSB 打平为宽表模型(以下简称:SSB-Flat),来测试查询引擎的性能。
在 SSB-Flat 宽表模型全部 13 个查询上,Apache Doris 1.2.0 均优于之前版本、未发生性能回退的情况,整体性能较 1.1.3 版本有近 4 倍的提升,较 0.15.0 版本有近 10 倍的提升、单个 SQL 性能最高提升近 13 倍。与此同时,在 SSB 星型模型下,Apache Doris 1.2.0 整体性能较 1.1.3 版本提升近 2 倍、较 0.15.0 版本提升近 31 倍,单个 SQL 最高提升近 60 倍,呈现巨幅的性能进化。

图4 SSB-Flat 宽表模型

图5 SSB 星型模型
(点击链接 https://doris.apache.org/blog... 前往查看)
关于 TPC-H
TPC-H 是一个决策支持基准(Decision Support Benchmark),它由一套面向业务的特别查询和并发数据修改组成,查询和填充数据库的数据具有广泛的行业相关性。这个基准测试演示了检查大量数据、执行高度复杂的查询并回答关键业务问题的决策支持系统。TPC-H报告的性能指标称为TPC-H每小时复合查询性能指标(QphH@Size),反映了系统处理查询能力的多个方面。这些方面包括执行查询时所选择的数据库大小,由单个流提交查询时的查询处理能力,以及由多个并发用户提交查询时的查询吞吐量。
在 TPC-H 标准测试数据集上的 22 个查询上,Apache Doris 1.2.0 版本整体性能相对 1.1.3 版本提升了将近 3 倍,相对于 0.15.0 版本提升了超 11 倍,其中单个 SQL 最高提升近 70倍!

图6 TPCH-100 性能测试对比
(点击链接 https://doris.apache.org/blog... 前往查看)
通过以上性能测试结果可以看出,毫无疑问 1.2 版本已成为自 Apache Doris 开源以来性能表现最佳的版本,这同样也使得 Apache Doris 成为全球 OLAP 数据库性能的新标杆。这一成绩的背后离不开所有社区开发者的付出和所有用户的信赖,正是因为有全体社区成员的努力才有了 Apache Doris 的飞速进步,在此也要向所有社区开发者和用户表示最衷心的感激。
诚然,性能不止是数据库追求的全部。在 1.2 新版本中,还有更多的最新特性等待揭晓,完整功能敬请期待后续发布的 Release Note,相信会给每一位期盼已久的用户以惊喜。最后,期待能有更多开发者与开源爱好者能够一同加入 Apache Doris 社区,共襄盛举,将国人开源的优秀项目推广到全球,成为现代数据分析技术的新基石。
# 互动时刻 #
Doris Summit 2022 已经正式起航,在 Summit 上将会同步 Apache Doris 最新的开发进展与 RoadMap。在此诚挚向全体社区公开征集演讲议题,如果您有好的idea、包括但不限于业务最佳实践、技术深度解析、行业趋势解读、数据生态方案等,欢迎您提交议题参与分享,与社区各领域专家深入探讨和交流。
议题征集链接:https://docs.qq.com/form/page...
— END —
最后,欢迎更多的开源技术爱好者加入 Apache Doris 社区,携手成长,共建社区生态。Apache Doris 社区当前已容纳了上万名开发者和使用者,承载了 30+ 交流社群,如果你也是 Apache Doris 的爱好者,扫码加入 Apache Doris 社区用户交流群,在这里你可以获得:
- 专业全职团队技术支持
- 直接和社区专家交流,获取免费且专业回复
- 认识不同行业的开发者,收获知识以及合作机会
- Apache Doris 最新版本优先体验权
- 获取一手干货和资讯以及活动优先参与权













