一、MySQL主从复制(异步复制,默认)
Mysql主从复制原理
Mysql的复制原理大致如下:
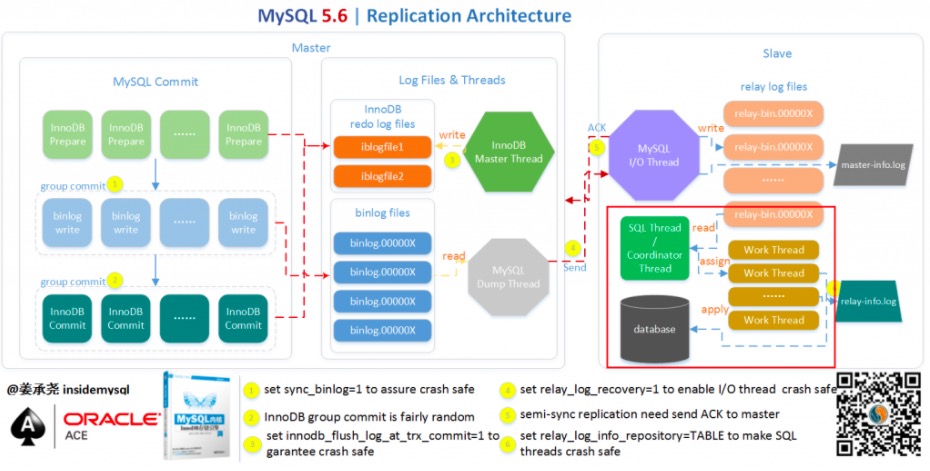
1.主库记录binlog日志
在每次准备提交事务完成数据更新前,主库将数据更新的事件记录到二进制日志binlog中。主库上的sync_binlog参数控制binlog日志刷新到磁盘。
2.从库IO线程将主库的binlog日志复制到其本地的中继日志relay log中
从库会启动一个IO线程,IO线程会跟主库建立连接,然后主库会启动一个特殊的二进制转储线程(binlog dump),二进制转储线程会读取主库上binlog中的事件,它不会一直对事件进行轮询,当它追赶上了主库就会进入睡眠状态,直到主库发送信号量通知其有新事件产生才会被唤醒。
3.从库的SQL线程进行重放
从库的SQL线程从中继日志relay log中读取事件并在从库执行,从而实现从库数据的更新。

需要注意的是:主库上并发的修改操作在从库上只能串行化执行,因为只有一个SQL线程来重放中继日志,这也是很多工作负载的性能瓶颈所在。虽然有一些针对你该问题的解决方案,但大多数用户仍然受制于单线程。在老版本的mysql中,IO线程是单线程的,但新版本IO线程也可以是多线程的,但无论怎样,SQL线程是单线程的。
二、半同步复制(Semisynchronous Replication)
1.主从延迟导致数据丢失
Mysql5.5之前的复制是异步的,主库和从库的数据有一定的延迟,这样就存在一个问题:当主库上写入一个事务并提交成功,而从库尚未收到主库推送的binlog日志,如果此时主库宕机造成主库上的事务binlog丢失,此时从库就可能损失这个事务,从而造成主从不一致。为了解决这个问题,Mysql5.5引入了半同步复制机制。
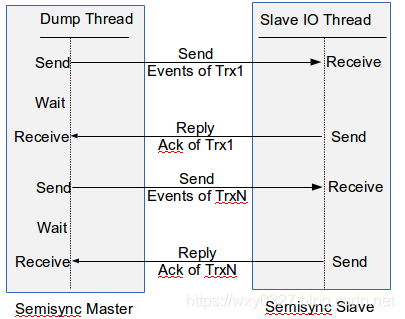
2.半同步复制
官方文档:17.3.8 Semisynchronous Replication
半同步复制是从Mysql5.5版本开始,以插件的形式支持的,默认情况下是关闭的,使用时需在配置中打开。
Mysql默认的复制是异步的,主库在将事件写入binlog后即成功返回客户端,但并不知道从库是否以及何时会获取和处理日志。而至于半同步复制,主库在提交后执行事务提交的线程将一直等待,直到至少有一个半同步从库确认已接收到所有事件,从库仅在将事件写入其中继日志(relay log)并刷新到磁盘后,才对接收到事务的事件进行确认。此时,主库收到确认后才会对客户端进行响应。半同步复制保证了事务成功提交后,至少有两份日志记录,一份在主库的binlog上,另一份在至少一个从库的中继日志relay log上,这样就进一步保证了数据的完整性。

图中步骤①②③中任何一个步骤中主库宕机,则事务并未提交成功,从库也没有收到事务对应的binlog日志,所以主从数据是一致的。
需要注意的是:
(1)主库和从库都要启用半同步复制才会进行半同步复制功能,否则主库会还原为默认的异步复制。
(2)当主库等待超时时,也会还原为默认的异步复制。当至少有一个从库赶上时,主库会恢复到半同步复制。
三、并行复制(多线程复制,multi-threaded slave)
1.主从延迟问题
由于主库上可以多客户端并发的写入,当主库的TPS较高时,由于从库的SQL线程是单线程的,导致从库处理速度可能会跟不上主库的处理速度,从而造成了延迟。
主库并发达到1000/s时,从库的延时会有几毫秒,几乎可以忽略。
主库并发达到2000/s时,从库的延时会有几十毫秒。
主库并发达到4000/s,6000/s,8000/s时,此时主库的压力很大,都快挂了。从库的延时会达到几秒。
上面的只是经验值,但是是在合理的范围内。(来源于中华石杉)
可以通过监控 show slave status 命令输出的Seconds_Behind_Master参数的值来检测主从延时:
- NULL:表示io_thread或是sql_thread有任何一个发生故障;
- 0:该值为零,表示主从复制良好;
- 正值:表示主从已经出现延时,数字越大表示从库延迟越严重。
2.并行复制
所谓并行复制,指的是从库开启多个SQL线程,并行读取relay log中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
Mysql5.6中的并行复制
MySQL 5.5版本不支持并行复制。MySQL 5.6版本开始支持并行复制,但是其并行只是基于schema的,也就是基于库的。当有多个库时多个库可以并行进行复制,而库与库之间互不干扰。但多数情况下,可能只有单schema,即只有单个库,那基于schema的复制就没什么用了。
其核心思想是:不同schema下的表并发提交时的数据不会相互影响,即slave节点可以用对relay log中不同的schema各分配一个类似SQL功能的线程,来重放relay log中主库已经提交的事务,保持数据与主库一致。
只需设置参数slave_parallel_workers即可开启并行复制,例如设置 slave_parallel_workers= 4,即有4个SQL Thread(coordinator线程)来进行并行复制。
Mysql5.7中的并行复制
而MySQL 5.7版本对并行复制进一步改进,已经支持“真正”的并行复制功能,是基于组提交的并行复制,官方称为enhanced multi-threaded slave(简称MTS),复制延迟问题已经得到了极大的改进。
其核心思想:一个组提交的事务都是可以并行回放(配合binary log group commit);slave机器的relay log中 last_committed相同的事务(sequence_num不同)可以并发执行。
通过设置参数slave_parallel_workers>0并且global.slave_parallel_type=‘LOGICAL_CLOCK’,即可支持一个schema下,slave_parallel_workers个的worker线程并发执行relay log中主库提交的事务。
3. ★踩坑案例(主从延迟问题解决方法)
其实这块东西我们经常会碰到,就比如说用了mysql主从架构之后,可能会发现,刚写入库的数据结果没查到,结果就完蛋了。。。。
所以实际上你要【考虑好应该在什么场景下来用这个mysql主从同步,建议是一般在读远远多于写,而且读的时候一般对数据时效性要求没那么高的时候,才用mysql主从同步】
所以这个时候,我们可以考虑的一个事情就是,【你可以用mysql的并行复制,但问题是那是库级别的并行,所以有时候作用不是很大】
所以通常来说,对于那种写了之后立马就要保证可以查到的场景,【采用强制读主库的方式】,这样就可以保证你肯定的可以读到数据。【其实用一些数据库中间件是没问题的。】
一般来说,如果主从延迟较为严重:
1、架构层面:分库,将一个主库拆分为多个。比如将1个库拆为4个主库,每个主库的写并发就500/s,此时主从延迟可以忽略不计。
2、开启mysql支持的并行复制,多个库并行复制。但如果说某个库的写入并发就是特别高,单库写并发达到了2000/s,并行复制还是没意义。28法则,很多时候比如说,就是少数的几个订单表,写入了2000/s,其他几十个表10/s。
3、代码层面:重写代码。写代码的同学,要慎重。当时我们其实短期是让那个同学重写了一下代码,插入数据之后直接就更新,不要查询。
4、直连主库。如果确实存在插入后立马要求就查询到,然后根据结果(比如某个状态)反过来执行一些操作,则可以对这个查询设置【直连主库】。但不推荐这种方法,这么搞导致读写分离的意义就丧失了。
四、多源复制(Multi-Source Replication)
MySQL从5.7版本开始支持多源复制的。MySQL 5.7之前只能实现一主一从、一主多从或者多主多从的复制。如果想实现多主一从的复制,只能使用 MariaDB,但是 MariaDB 又与官方的 MySQL 版本不兼容。MySQL 5.7 开始支持了多主一从的复制方式,也就是多源复制。所以,多源复制至少需要两个Master和一个Slave。

1.多源复制使用场景
- 数据分析部门会需要各个业务部门的部分数据做数据分析,这个时候就可以用到多源复制把各个主数据库的数据复制到统一的数据库中。
- 在从服务器进行数据汇总,如果我们的主服务器进行了分库分表的操作,为了实现后期的一些数据统计功能,往往需要把数据汇总在一起再统计。
- 在从服务器对所有主服务器的数据进行备份,在MySQL 5.7之前每一个主服务器都需要一个从服务器,这样很容易造成资源浪费,同时也加大了DBA的维护成本,但MySQL 5.7引入多源复制,可以把多个主服务器的数据同步到一个从服务器进行备份。
2.配置多源复制
配置多源复制时,可以将主库配置为使用基于GTID的复制或基于binlog位置的复制。
官方文档:
Section 16.1.3.4, “Setting Up Replication Using GTIDs”
Section 16.1.2.1, “Setting the Replication Master Configuration”
总结:
mysql默认的复制是异步的,主库写入了binlog后就会返回给客户端,而无论从库是否复制成功。由于主从延迟,当主库挂掉时会造成数据丢失,为了解决数据丢失问题,引入了半同步复制机制。同时为了解决复制的性能问题,可以开启多线程并行复制。(mysql5.5不支持并行复制,mysql5.6开始支持基于schema的并行复制,mysql5.7则对5.6并行复制进行改进增强)
mysql的一主一/多从、双主都是一个复制源,而mysql5.7多源复制则允许多个mssql同时对一个从库进行复制。