
【摘要】一般地,架构模式大致可以分成两类,单体架构(monolithic architecture)和分布式架构(distributed architecture)。
前言
谈到软件系统设计的方法论,在代码层面,有我们熟悉的23种设计模式(design pattern),对应到架构层面,则有所谓的架构模式(architecture pattern)。它们分别从微观和宏观的角度指导着我们设计出良好的软件系统,因此,作为一个软件工程师,我们不仅要熟悉设计模式,对常见的架构模式也要熟稔于心。正如看到一个设计模式的名字脑里就能浮现出大致的结构图,当我们看到一个架构模式的名字时,也要马上想到对应的架构图及其基本特点。比如,当谈到分层架构时,我们就应该想起它的架构图是怎样的、有哪些出色的架构特征(architecture characteristics)、系统是如何部署的、数据存储的策略是哪种、等等。
一般地,架构模式大致可以分成两类,单体架构(monolithic architecture)和分布式架构(distributed architecture)。本系列文章将会介绍以下8种常用的架构模式:
单体架构
分层架构(Layered architecture)
管道架构(Pipeline architecture)
微内核架构(Microkernel architecture)
分布式架构
基于服务的架构(Service-based architecture)
事件驱动架构(Event-driven architecture)
基于空间的架构(Space-based architecture)
面向服务的架构(Service-oriented architecture)
微服务架构(Microservices architecture)
软件设计中的谬误
在介绍架构模式前,我们先谈谈软件设计中的谬误(fallacy)。所谓谬误,就是在设计软件系统,特别是分布式系统时,我们先入为主地假设它们是正确,但实际上并非如此的一些观念。这些观念都是我们在设计软件时考虑不周的体现。
谬误1:网络是可靠的
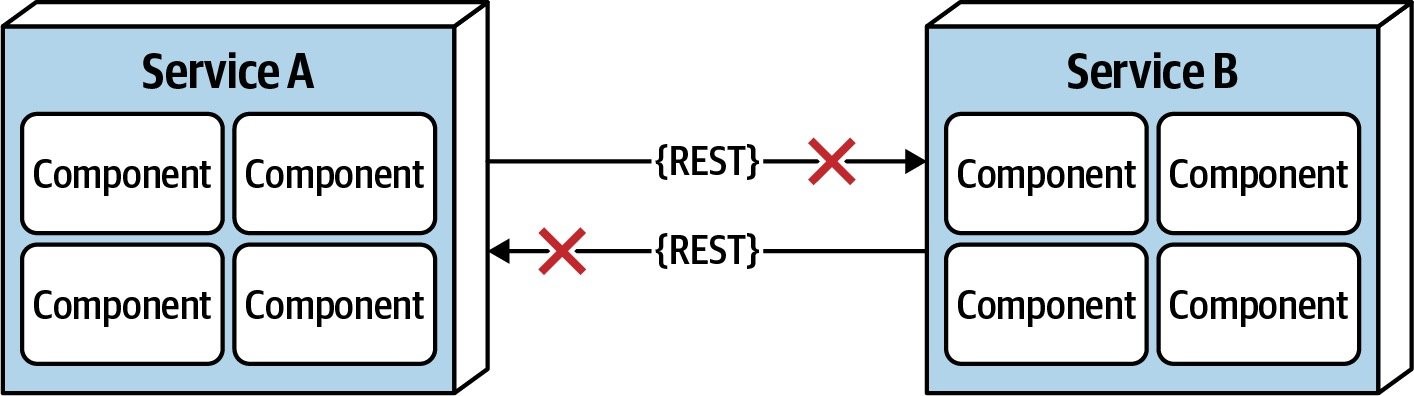
网络是不可靠的
很多软件工程师常常假设网络是可靠的,但实际并非如此。相比20年前,现在的网络会可靠很多,但是仍然具有很大的不确定性。如上图所述,Serivce B可能完全是正常运行的,但是因为网络的问题,Service A发出的请求无法到达Service B。一种更糟糕的场景是,Service B可以收到Service A的请求,并处理了相关的数据,但是网络问题导致了Service A无法收到Service B的响应,从而造成了数据不一致。网络的不可靠也是为什么系统中常常出现服务通信超时、服务熔断等的原因。
总而言之,如果假设网络是可靠的,那么我们设计出来的软件系统将会是不可靠的。
谬误2:时延是0

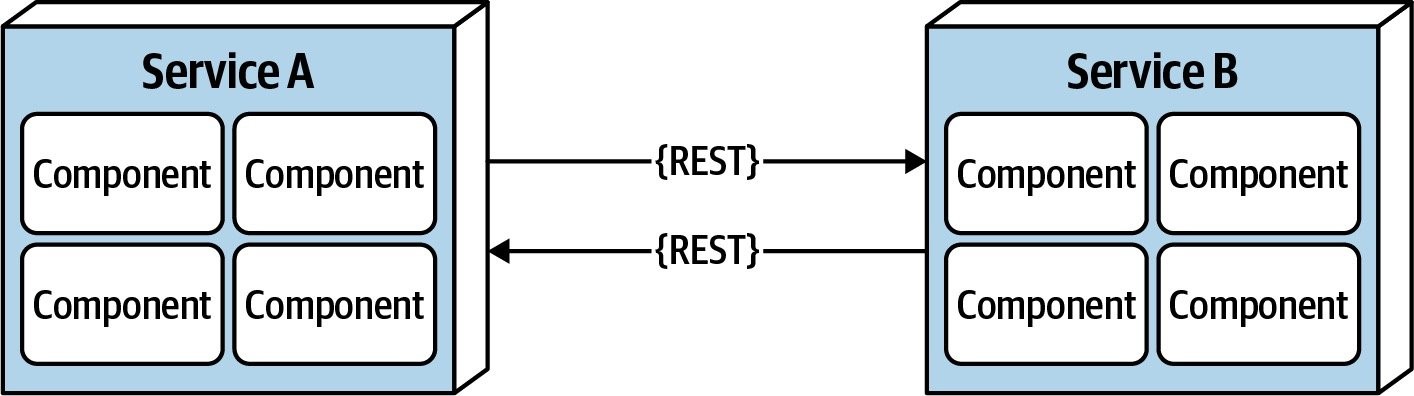
时延不为0
如上图所示,服务内组件间的函数/方法级别的调用,耗时是微秒,甚至是纳秒级别;但是服务间的远程调用(比如REST、消息队列、RPC),耗时会是毫秒级别,甚至在异常场景会达到了秒级!在设计系统,特别是分布式系统时,时延是一个无法被忽视的因素,我们必须清楚系统的平均时延,否则设计出来的方案可能根本不可行。比如,假设系统中服务间通信时延为100ms,如果一个请求的调用链涉及到10个服务,那么该请求的时延将会是1000ms!这么高的平均时延对于一般系统来说是完全无法接受的。
进行系统设计时,考虑平均时延还不够,更重要的是95th和99th百分点。一个系统的平均时延可能仅仅只有数十毫秒,但是95th百分点的时延却达到了数百毫秒,很多时候,这也恰恰成为了拖垮整系统性能的那块“短板”。
谬误3:带宽是无限的
带宽是有限的
在单体架构中,业务流程都在单服务内闭环,消耗的带宽很少甚至为0,因此带宽并不是主要关注点。一旦将系统拆分成分布式架构,一个业务流程可能涉及多个服务间的通信,带宽就成了必须考虑的因素。带宽的不足,会导致网络变慢,从而影响系统的时延(谬误2:时延是0)和可靠性(谬误1:网络是可靠的)。
如上图所示,假设在一个Web系统中,Service A负责处理前端请求,Service B负责管理用户信息(包括姓名、性别、年龄等45个属性)。Service A每处理一个请求都需要向Service B查询用户姓名(200 bytes),而在一次请求中,Service B却返回了用户的所有信息(500 kb)。如果系统每秒处理2000次请求,每次请求消耗500 kb带宽,那么每秒消耗的总带宽会是1 Gb!如果Service B仅仅返回必须的姓名,那么同等条件下,每秒消耗的总带宽仅仅是400 kb。
此类问题就是所谓的stampcoupling,解决方法也很多,比如在请求中添加属性选择,使用GraphQL替代REST。相比于这些技术手段,更重要的是确定服务间通信所需的最小数据集,并在进行系统设计时将其作为一个重点关注的因素。
谬误4:网络是安全的

网络是不安全的
VPN、防火墙等的广泛使用,使得很多工程师在设计系统时忽略了“网络是不安全的”这一重要原则。特别是从单体架构演进到分布式架构以后,系统被攻击的概率将会大大增加。因此,在分布式系统中,每个服务都必须是安全的endpoint,这样才能确保任何未知或恶意的请求都被拦截掉。当然,安全是有代价的,这也是像微服务架构这类细服务粒度的系统,一次业务请求中调用链过长后性能极速下降的重要原因。
谬误5:网络拓扑一成不变

网络拓扑是时常变化的
这里的网络拓扑指的是系统运行时所涉及到的网络设备,包括所有的路由器、防火墙、集线器、交换机等。很多工程师会假设网络拓扑是固定的,然而并非如此。
假设如下场景,为架构师的你在周一早上回到公司后,发现组内同事都在为系统中所有的服务间通信都在不断出现响应超时现象而抓狂,但奇怪的是周末并没有做服务变更。经过几个小时的攻关后,你发现周一凌晨2点时有过一次网络升级,而恰恰是这次“次要”的网络升级,推翻之前设计系统时的时延假设,从而触发了本次事故。
因此,软件工程师也需要与网络管理员时常联系,确保在每次网络升级前都明确网络拓扑的变更点,从而做出相应的调整。
谬误6:只有一个网络管理员

不只有一个网络管理员
网络管理员往往不止有一个,特别是在“云”时代,数据中心分散在多个地域,理所当然也存在着多个局域网。运行在“云”上的系统很有可能跨越多个数据中心,因此工程师们应当感知各个数据中心的网络管理员对网络的相关操作,提前做出应对措施,避免出现因网络拓扑变更(谬误5:网络拓扑一成不变)而导致的服务通信超时,甚至触发服务熔断。
谬误7:通信成本为0

通信成本不为0
这里的通信成本并非指网络时延,而是指每增加一次服务间调用所导致的钱的花销。很多工程师在设计系统时常常忽视掉通信成本,大家都在鼓吹分布式架构相对了单体架构的优越性,却忘记了它带来的服务器、防火墙、网关等硬件的数量增加,这些都是白花花的银子。
因此,在进行系统设计时,我们也应该将硬件资源和网络拓扑纳入考虑因素。
谬误8:网络是同质的

网络并非同质的
很多工程师都会假设网络是同质的,也就是所有的网络设备都来自同一硬件厂商,这当然也是一个谬误。实际上,一个大的通信网络中,硬件设备往往来自于不同的厂商,这得益于网络协议标准的统一。厂商间设备的协作测试毕竟不会太充分,在一些特殊场景下极有可能存在网络丢包,从而影响了网络的可靠性(谬误1:网络是可靠的)、时延(谬误2:时延是0)以及带宽(谬误3:带宽是无限的)。
一切从“大泥球”开始

“大泥球”架构
“大泥球”架构是著名的反模式架构,最初在1997年由Brian Foote 和 JosephYoder提出。在“大泥球”架构里,系统没有进行内部的模块划分,代码耦合严重,调用关系混乱,就像一个大的泥球。如上图所示,每一个点代表一个类,红线则表示类之间的耦合关系。这样的架构对需求变更极不友好,往往牵一发而动全身,而且在部署、可测试性、性能等方面也存在着很多问题。所有的架构师都在极力避免“大泥球”的出现,但很不幸的是,它仍然在实际项目中很常见,特别是项目伊始,代码质量和结构还没被严格管控起来前。
有反模式的出现,必然就有解决它的方法,这便是架构模式,从下一篇文章开始,我们将逐个介绍常见的8种架构模式。
总结
跟设计模式类似,架构模式是软件工程师们多年来在架构设计方面的经验总结。每种架构模式并没有绝对的优劣之分,我们不能说微服务架构就一定比单体分层架构优越,它们都有着各自的应用场景。分布式架构比单体架构有着更好的可扩展性、容错性,但也带来了更高的复杂性,比如分布式事务。因此,我们应该熟知各个架构模式的特点,这样才能在特定的业务场景使用合适的架构模式。
作者:元闰子












