
Part 1 摘要
MatrixOne是一款云原生数据库,不仅支持超大规模数据集上的高性能分析查询,同时具备高吞吐,低延迟的事务读写能力。本文介绍了MatrixOne数据库的存储引擎TAE(Transctional Analytical Engine)的架构。前文介绍了单机TAE的相关设计,本文将重点介绍云原生和存算分离相关的几个关键组件。
点击查看前文关于TAE(Transactional Analytical Engine)的那些事
↑↑↑点击查看前文
很多数据库在使用对象存储时,要么作为冷备使用,要么以牺牲延迟为代价在提交事务时同步写入到对象存储中。TAE有效的利用云存储资源,将新写入的数据先保存到日志服务的本地磁盘中,随后异步的将日志中的数据转存至对象存储中。这样TAE既保留了存算分离的可能性,又避免了过高的写入延迟。
比如说:
- TAE可以管理远大于本地存储容量的数据。本地内存和磁盘都可以作为缓存,只保存最新被访问到的数据;
- TAE可以以很小的代价,在一个新结点上装载出完整的数据副本。这对于服务的 HA 还有计算资源的隔离非常的重要。
Part 2 LogService
为了减少写入延迟,TAE先将最新的数据持久化到日志中,随后异步的转存到对象存储里。所以TAE是通过协同日志和对象存储,以保证提交事务的持久性。TAE抽象出了日志层,可以以很小的代价接入任何日志服务。默认接入的是我们自研的LogService日志服务。
日志服务的核心需求有以下几点:- 高吞吐
- 低延迟
- 高可靠
高可用
日志中存储的是最新提交事务的数据,当这些数据被异步转存到对象存储后,相关日志也会被删除。可以把日志看成一个在时间轴上的滑动窗口,TAE推动这个窗口不断的往前滑动,窗口以外的数据会被清除,并且TAE会确保落在窗口内的数据量不会非常大。因此没有必要为日志服务配置大容量的磁盘。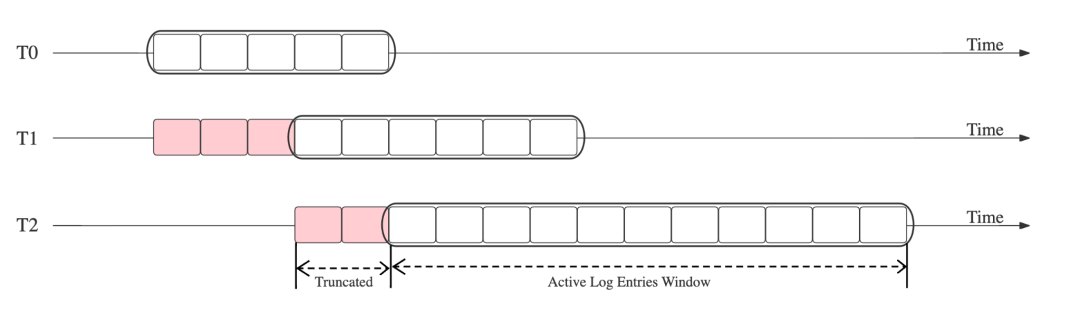
Part 3 DN(Data Node)
在写流程中,TAE会将提交事务写入日志,并且异步的转存至对象存储。这些都发生在DN(Data Node)结点。
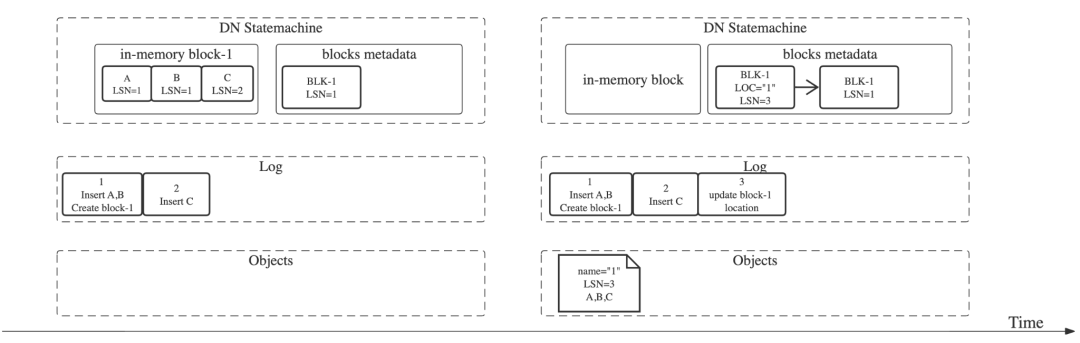
上图展示了DN在执行一些写操作后的状态——上面的是内存状态机,中间的是日志,最下面的是对象存储:- 第一个事务添加元数据Block-1, 并且插入A、B两行至Block-1。事务提交的日志是LSN=1;
- 第二个事务插入一行C至Block-1。事务提交日志是LSN=2;
第三个事务将Block-1持久化至对象存储上,修改Block-1元数据添加location=“1”, 产生该Block的第二个版本。事务提交日志是LSN=3。
DN状态机致力于将日志里的数据转存到对象存储上,但是转存顺序不完全依赖事务日志的单调性,如下图:
LSN[11-17]的已经转存,但是LSN[3-4,7-10]还在内存状态机内(原因已在单机TAE的文章中解释)。这只是一个临时状态,DN会根据特定的策略推动日志的窗口不断向前移动。
DN会在适当的时机选择一个事务作为快照候选点,并等待这个候选点之前的所有事务被转存后,以这个候选点的时间戳作为快照的时间戳保存成快照。当快照生成后,该事务之前所有的日志都可以被清理: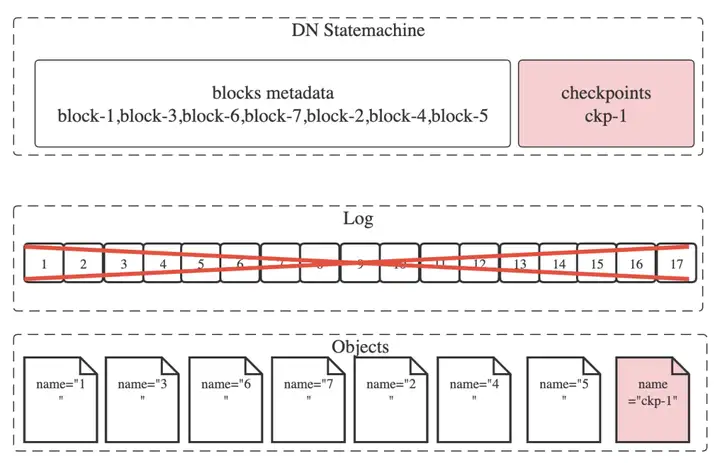
这里我们将快照后所有的日志称为LogTail。比如上图中“ckp-1” 没有生成前,LSN[1-17]都是LogTail。DN出现故障后,只需要从对象存储上读取最新的快照,并且从日志服务中读取LogTail,便可恢复出完整的状态机。
Part 4 CN(Compute Node)
分布式TAE不仅包括DN, 也包括负责协调所有查询负载的CN(Compute Node)。当集群加入一个新的CN, 它会从DN获取快照和LogTail信息,并且维护一个内存状态机。数据文件会按需从对象存储中拉取,并根据需要保存在缓存中。这种设计不需要在查询之前就拉取大量的数据文件,满足了高弹性CN的需求。
举例说明
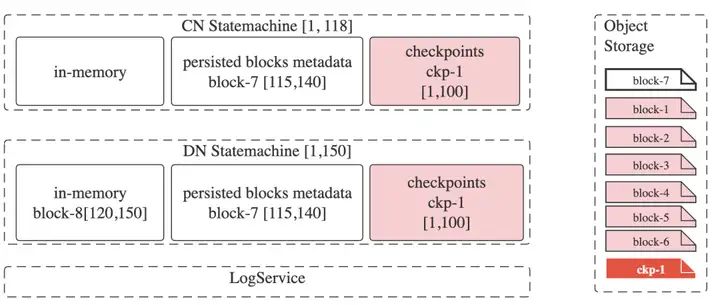
加入一个CN到集群,此时DN的状态可以按照事务时间戳描述为[1,150],表示拥有从时间戳1到150之间所有事务的数据。
DN的状态由以下三部分组成:- 快照 [0,100],该快照包含6个数据块 [“block-1”, “block-2”, “block-3”, “block-4”, “block-5”, “block-6”]
- 持久化的数据块 “block-7“ [115, 140]
- 内存数据块 “block-8” [120, 150]
此时新加入的CN状态可描述为 [0, 0]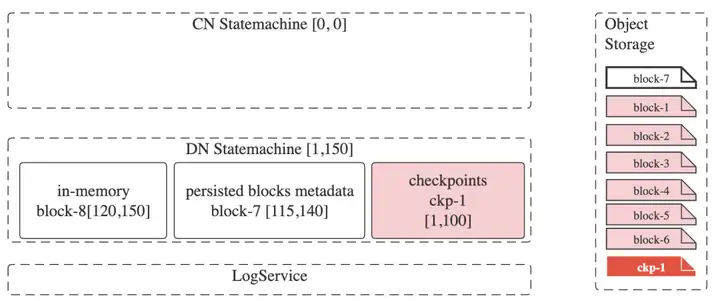
CN接收到查询请求,假设该请求的时间戳为118: - CN检查当前状态机的状态为[0, 0], 最大时间戳小于118;
- CN会向DN 发出一条读请求,请求0到118之间的LogTail;
- CN收到DN的响应,将LogTail应用到本地的状态机;
- 更新CN状态机的状态为 [1, 118];
- 开始查询。
CN接受到时间戳为130的查询请求: - CN检查当前状态机的状态为[1, 118], 最大时间戳小于130;
- CN会向DN发出一条读请求,请求118到130之间的LogTail;
- CN收到DN的响应,将LogTail应用到本地的状态机;
- 更新CN状态机的状态为[1, 130];
开始查询。

Part 5 协同工作
MatrixOne支持CN的动态扩容以及多个DN(动态扩容暂时没有支持)。
定义表结构时,可以指定分区键,将表数据分布在多个DN上。每个CN表数据包含了多个DN分区的数据,这有利于一些跨分区的查询。
纵观DN的职责,主要有以下三点:
1.提交事务
a.冲突检测
b.写日志
c.应用事务到状态机
2.为CN提供LogTail服务
3.转存最新的事务数据至对象存储中,并且推动日志窗口
用户的计算负载不会被调度到DN, 我们认为当前架构下DN的数量可以控制在有限个数量,甚至单个 DN就可以满足大多数的需求。通过扩容CN的数量,提高系统的性能。Part 6 冲突检测
事务被提交到DN前,会在CN的工作区内做一次基于事务起始时间戳的冲突检测,在被提交到DN后,只会与事务起始时间戳到当前最新时间戳内产生的增量数据做检测。
举例说明- CN处理事务Txn-[t1]的写请求时,会做一次基于时间戳t1的冲突检测
CN将Txn-[t1]提交给DN, DN会用Txn-[t1]的writeset和[t1,now]产生的writeset做一次冲突检测
增量冲突检测机制,可以提高DN处理事务的吞吐能力,不会随着表数据的增长而逐渐下降Part 7 大事务
大事务通常会占用大量的内存,并且很可能导致冲突检测不够高效。提交大事务和同步大事务的LogTail也容易使DN成为瓶颈。
这里通过三种方式支持大事务:- CN在提交事务前,将事务的数据建好相关索引,并写入到对象存储中,提交至DN的只有相关元数据;
- DN在提交事务时,利用相关的索引加速检测;
- DN在提交事务时,只更新元数据。
当前MatrixOne已经发布0.6版本,也是新架构下的第一个版本,还有很多不足。我们会在之后0.7和0.8的版本重点攻克性能和稳定性相关的问题。本文没有深入探讨一些技术细节,后续将会一一分享









