
一年一度的中国数据库技术大会DTCC,迎来了第10届,从传统商业数据库各种开源数据库,从大数据到AI,从技术到管理,业界有的,大会上就有涉及的相关主题,议题相当丰富,《议程奉上 | DTCC2019 中国数据库技术大会最全议程总览》。
可以说,自己随着大会,慢慢成长,从开始一点儿都听不懂,到现在能听懂一点儿,虽然和顶级相差甚远,但和自己比,还是能看见提高,有些内容,还是值得思考,值得在工作中有所借鉴。
这次会议的一个主题,就是国产数据库达梦新产品发布会,去年单位和达梦共同举办过一次数据库竞赛,让自己对达梦有了更直观的认识。
关于达梦的一些测试参考:
本次大会,达梦带来了新产品,《达梦重磅发布新产品DM8,开启数据库发展新方向》,嘉宾也是重量级,中国工程院院士倪光南,

中国工程院院士方滨兴,

两位院士,从自身经历,以及达梦的特点,阐述了自己观点,对国产数据库的发展,指明了道路。
达梦带来了4项新的架构级新技术,都是对关键业务、超大规模事务处理、在线分析处理、事务-分析混合处理4个方向的思考。达梦数据共享集群(DM DSC)、透明分布式数据库、数据库弹性计算、行列融合技术2.0,这四种架构共通共存,它们是达梦架构持续演进的自然产出,包含了所珍视的技术创新的连续性。
作为达梦的客户,中航信使用达梦作为某核心交易系统的数据库。该交易系统,对数据库高性能、高安全、高可用、高可靠等方面有严格要求。彭总的演讲,回顾了系统建设的过程,针对达梦数据库进行了多次仿真业务测试,在正常业务的10倍压力下,达梦完全满足业务需求。达梦,也是唯一一家进入民航客票系统的国产数据库公司。
各个分会场的演讲主题,涵盖了各个方向,有几场,印象还是很深的。
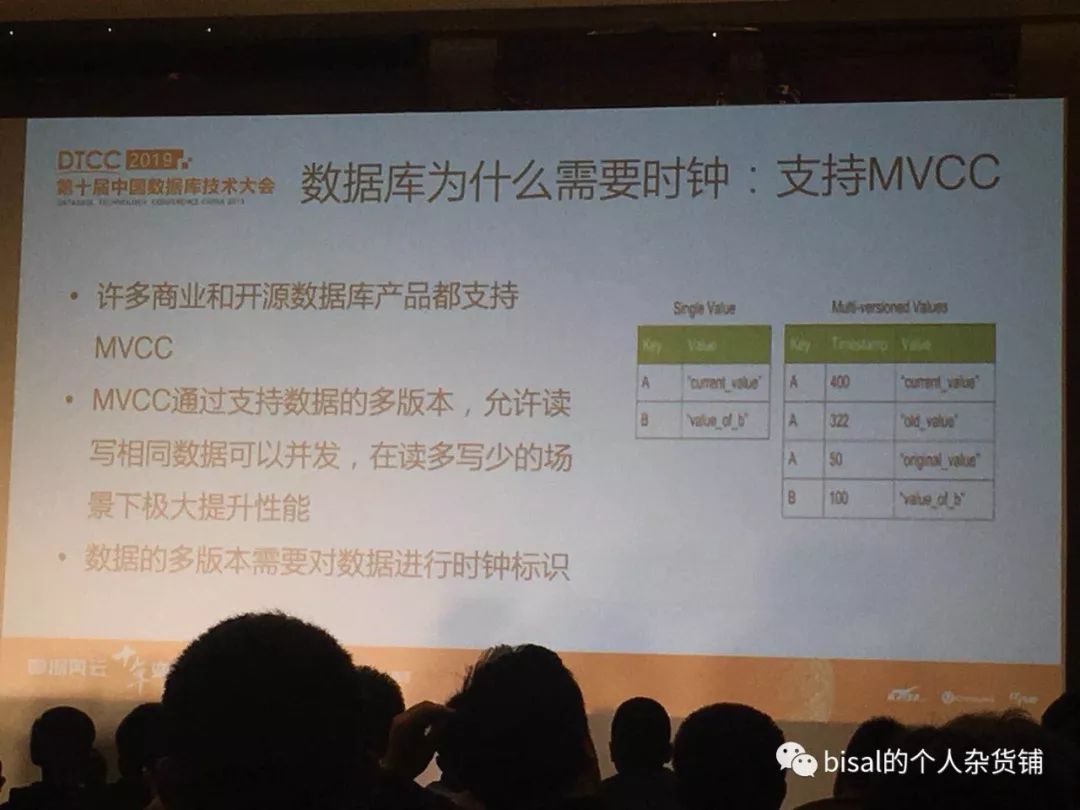
来自阿里的圭多,登博,这次介绍了数据库时钟,作为关系型数据库最重要的一个功能,就是提供事务,保证ACID,其中决定事务原子性(A)和隔离性(I)的标识,就是数据库对事务顺序的标识,可能会用到日志LSN、事务ID、时间戳等,从另一个角度,时钟可以让数据库支持MVCC,即多版本,无论是Oracle,还是PG,都有各自对多版本的支持。对技术来说,学和用,可能不是特别难,但要了解技术的原理,运行机制,甚至找出设计的缺陷,没积累,没思考,没实践,可能只是纸上谈兵了,像时钟,可能是数据库领域中一个很小的知识点,但若能研究了解到极致,对数据的掌握,可能就会上一个层次,这是作为技术人,需要沉下心来,积累掌握,
老A的演讲,介绍了他做数据库累积的经验,以及排查问题的方向,并讲解了从8i开始引入的等待模型,其实包括从10g开始引入的时间模型,这两个维度的统计数据,对于Oracle中问题定位起到了至关重要的作用。俗话说,磨刀不误砍柴工,方向正确,才能事半功倍,同时还免费赠送了他整理的上百页PPT,相当干货,另外,推荐了三本Oracle优化的书籍,这三本我都读过,目前正在读梁老师的《收获,不止SQL优化》。
P.S. 关于Oralce的图书推荐,曾经写过我看的,仅供参考,

lastwinner大师则继续从SQL审核方向,介绍了当前IT系统建设碰见的问题、挑战,以及最佳实践,SQL审核,一方面是技术,另一方面有管理和流程,我们正在研发自己的智能审核平台,在这方面,确实有些方向,值得借鉴和发展,

来自民生的徐春阳则从源码层面介绍了MySQL解析器工作原理,真是从源码层,一点点得到的计算结果,对MySQL不熟,但执行计划选择依赖的成本值计算,和Oracle如出一辙,尽管MySQL能通过源码找出具体的计算过程,而Oracle只能通过10053了解有限的信息,但这种刨根问底的态度,值得我们学习,

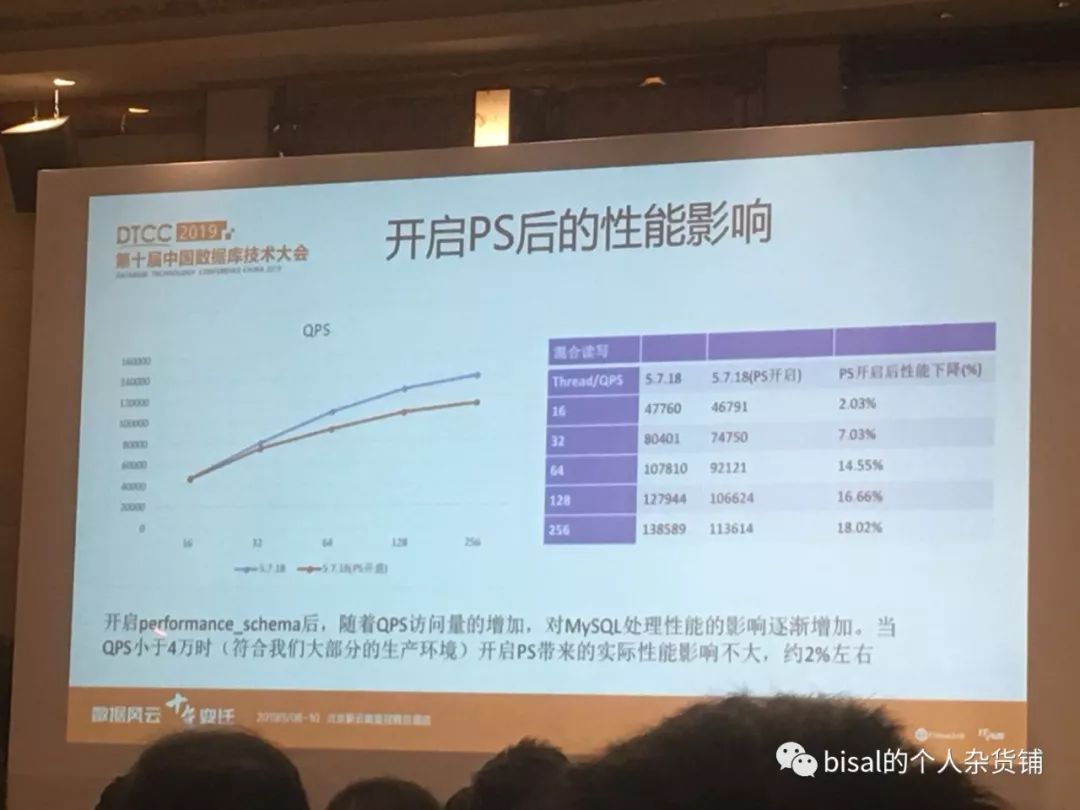
携程的王栋,介绍了他们对MySQL中SQL全量语句的采集审核系统,利用Performance Schema,通过采集、中转、加载、实时计算、离线计算等模块,实现对SQL审核支持,
由于会议期间牵扯到系统上线,所以中间空缺了,少听了些演讲,很是可惜,但是大会期间,还是碰见了不少老朋友,铁庵老师,Alan老师,Owen老师,睿哥,全文兄等等,聊聊技术,聊聊工作。
通过这些演讲,还是能找到自己工作方向上的一些问题,取长补短。现在各大组织,都会有各种不同的技术大会,根据自己的需求,需要进行取舍,带着问题听,或者对演讲的主题有过实践,或者演讲方向是自己感兴趣、工作上会涉及的,可能效果会更好,否则很可能就是听个热闹,听完就完了。能在工作当中,思考和实践,这才能让技术大会的价值,得到充分发挥,有朝一日,我们才能成为讲台上的焦点,实现自我提升。
本文分享自微信公众号 - bisal的个人杂货铺(gh_e8769c7350b1)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。









