背景
前段时间我们想实现 Pulsar 消息的追踪流程,追踪实现的效果图如下:
实现其实比较简单,其中最重要的就是如何存储消息。
消息的读取我们是通过 Pulsar 自带的 BrokerInterceptor 实现的,对这个感兴趣的朋友后面会单独做一个分享。
根据这里的显示内容我们大概需要存储这些信息:
- 客户端地址
- 消息发布时间
- 分发消费者、订阅者名称
- ACK 消费者、订阅者名称
- 消息 ID
最终捋了下:
都以两个 consumer 计算:
一条消息占用内存:140+ 535*2 + 536*2 =2282byte
存储三天:TPS * 86400 * 3=TPS*259200 条
总存储:2282*TPS*259200≈ 百GB
根据我们的 TPS 计算,三天的大概会使用到 上百 G 的存储,这样首先就排除了 Redis 这种内存型数据库。
同样的换成 MySQL 存储也不划算,因为其实这些数据并不算那么重要。
做了几个技术选型都不太满意,不是资源开销太大就是没有相关的运维经验。
后面在领导的提醒下,我们使用的 VictoriaMetrics 开源了一个 VictoriaLogs,虽然当时的版本还是 0.1.0,使用过他们家 Metrics 的应该都会比较信任他们的技术能力,所以就调研了一下。
具体的信息可以查看官方文档:
https://docs.victoriametrics.com/VictoriaLogs/

简单来说就是它也是一个日志存储数据库,并且有着极低的资源占有率,相对于 ElasticSearch 来说内存、磁盘、CPU 都是几十倍的下降率。

通过官方的压测对比图会发现确实在各方面对 ES 都是碾压。
官方宣传的第一反应是不能全信,于是我自己压测了一下,果然 CPU 内存 磁盘的占用都是极低的。
同时也发现运维部署确实简单,直接一个 helm install 就搞定,就是一个二进制文件,不会依赖第二个组件。
按照刚才同样的数据存储三天,只需要不到 6G 的磁盘空间,我们生产环境已经平稳运行一段时间了。
因为我们是批量写入数据的,所以在最高峰 20K 的 TPS 下 CPU 使用不到 0.1 核,内存使用最高 120M,这点确实是对 ES 碾压了。

磁盘占用也是非常少。
这些有点得归功于它有些的压缩、编解码算法,以及 Golang 带来的相对于 Java 的极低资源占用。
还存在的问题
如果一切都这么完美的话那 VictoriaLogs 确实也太变态了, 自然他也有一些不太完美的地方。
分词功能有限
首先第一个是分词功能有限,只能做简单的搜索,无法做到类似于 ES 的各种分词,插件当然也别想了。
不支持集群
当前版本不支持集群部署,也就是无法横向扩展了;不过幸好他的的单机性能已经非常强了。
这也是目前阶段部署简单的原因。
过期时间无法混用
VictoriaLogs 支持为数据配置过期时间自动删除,有点类似于 Redis,它会在后台启动一个协程定期判断数据是否过期,但只能对所有数据统一设置。
比如我想在 VictoriaLogs 中存放两种不同类型的数据,同时他们的过期删除时间也不相同;比如一个是三天删除,一个是三月后删除。
这样的需求目前是无法实现的,只能部署两个 VictoriaLogs.
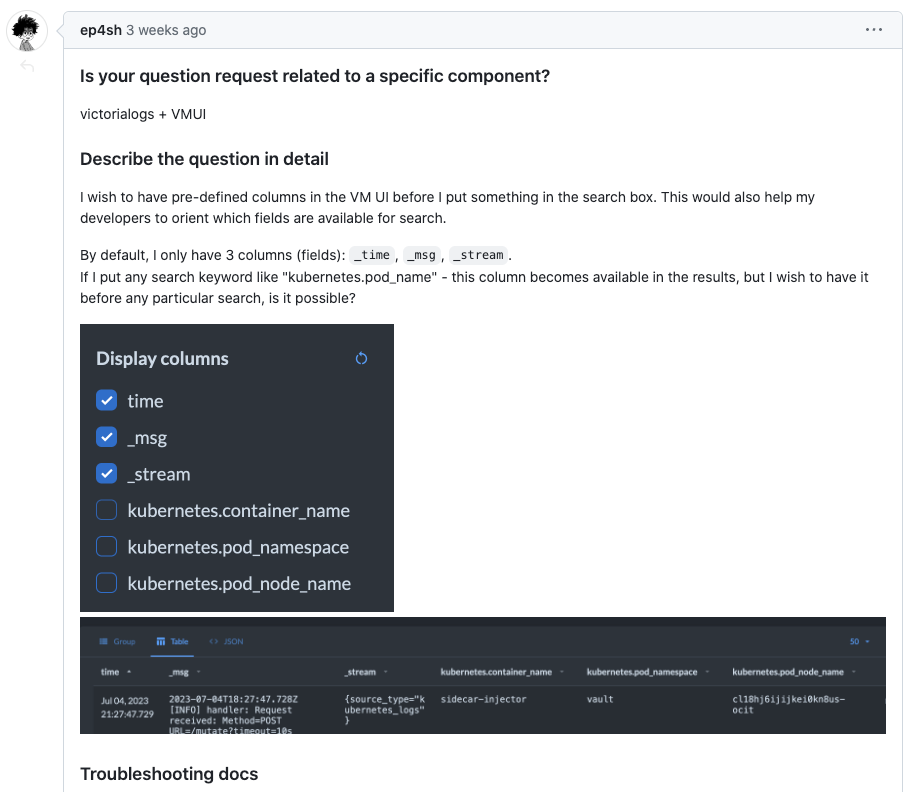
默认无法查询所有字段
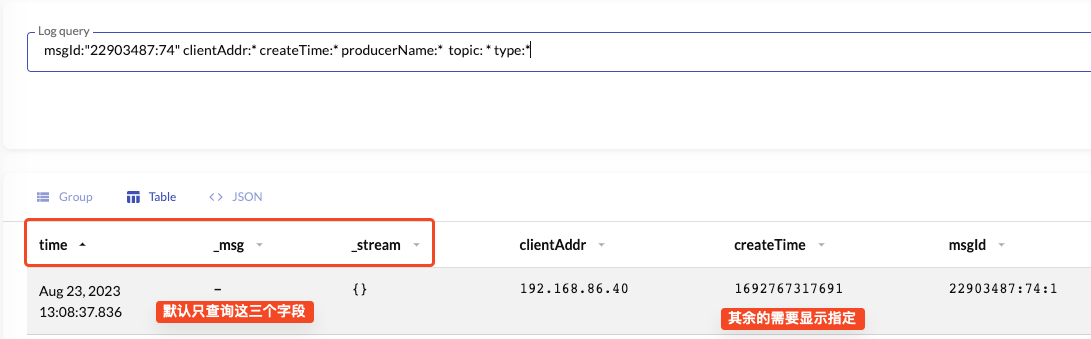
由于 VictoriaLogs 可以存储非结构化数据,默认情况下只能查询内置的三个字段,我们自定义的字段目前没法自动查询,需要我们手动指定。
这个倒不是致命问题,只是使用起来稍微麻烦一些;社区也有一些反馈,相信不久就会优化该功能。
- https://github.com/VictoriaMetrics/VictoriaMetrics/issues/4780
- https://github.com/VictoriaMetrics/VictoriaMetrics/issues/4513
没有官方 SDK
这也是个有了更好的一个功能,目前只能根据 REST API 自己编写。
总结
当前我们只用来存储 Pulsar 链路追踪数据,目前看来非常稳定,各方面资源占用极少;所以后续我们会陆续讲一些日志类型的数据迁移过来,比如审计日志啥的。
之后再逐步完善功能后,甚至可以将所有应用存放在 ElasticSeach 中的日志也迁移过来,这样确实能省下不少资源。
总得来说 VictoriaLogs 资源占用极少,如果只是拿来存储日志相关的数据,没有很强的分词需求那它将非常合适。
截止到目前最新版也才 0.3.0 还有很大的进步空间,有类似需求的可以持续关注。