
简介:Docker 解决了单个容器的镜像化问题,而 sealer 通过把整个集群打包,实现了分布式软件的 Build Share Run。
作者 | fanux.中弈
什么是集群镜像
顾名思义,和操作系统 .iso 镜像或 Docker 镜像类似,集群镜像是用一定的技术手段把整个集群的所有文件以一定格式打成的一个资源包。

对比单机和集群会发现一些的有趣现象:
- 单机有计算、存储、网络等驱动;集群有 CNI/CSI/CRI 实现像是集群的驱动。
- 单机有 ubuntu centos 操作系统;集群中可以把 Kubernetes 看成云操作系统。
- 单机上可以运行 docker 容器或虚拟机;相当于一个运行的实例,集群上也有运行着 K8s 的实例。
- 单机上有虚拟机镜像,docker 镜像;随着云计算技术的发展,集群上也会抽象出类似的镜像技术。
以基于 Kubernetes 的集群镜像为例,里面包含了除操作系统以外的所有文件:
- docker 依赖的二进制与 systemd 配置、dockerd 配置,以及一个私有的容器镜像仓库。
- Kubernetes 核心组件二进制、容器镜像、kubelet system 配置等。
- 应用需要用到的 yaml 配置或 helm chart,以及应用的容器镜像。
- 其它脚本、配置与二进制工具等应用运行需要的所有依赖。
同样,集群镜像运行时肯定不是起一个容器或者装在一台机器上,而是这个镜像可以直接安装到多台服务器上或者直接对接到公有云的基础设施上。
sealer 介绍
sealer是阿里巴巴开源的集群镜像的一个实现方式,项目地址:_https://github.com/alibaba/sealer_
Docker 解决了单个容器的镜像化问题,而 sealer 通过把整个集群打包,实现了分布式软件的 Build Share Run!!!
试想我们要去交付一个 SaaS 应用,它依赖了 MySQL/ES/Redis 这些数据库和中间件,所有东西都在 Kubernetes 上进行编排,如果没有集群镜像时,要做如下操作:
- 找个工具去安装 K8s 集群
- helm install mysql es redis... 如果是离线环境可能还需要导入容器镜像
- kubectl apply yoursaas
看似好像也没那么复杂,但其实从整个项目交付的角度来说,以上操作是面向过程极易出错的。
现在如果提供另外一个方式,只需一条命令就可解决上面的问题,你会不会用?
sealer run your-saas-application-with-mysql-redis-es:latest
可以看到,只需要 run 一个集群镜像,整个集群就被交付了,细节复杂的操作都被屏蔽掉了,而且任何应用都可以使用相同的方式运行。这个集群镜像是怎么来的呢?

如上图所示:我们只需要定义一个类似 Dockerfile 的文件,将其称之为 Kubefile, 然后执行 build 命令即可:
sealer build -t your-saas-application-with-mysql-redis-es:latest .
从单机和集群两个纬度进行对比,就可以一目了然:
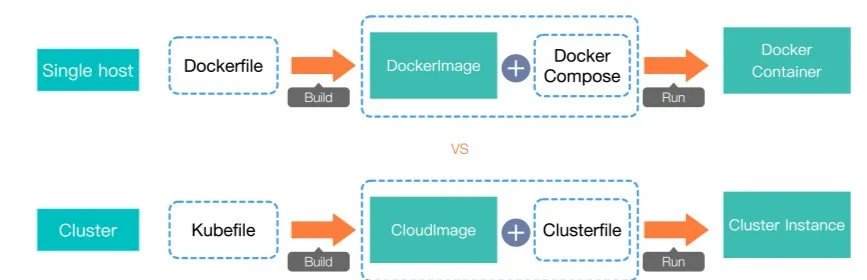
- docker 通过 Dockerfile 构建一个 docker 镜像,使用 compose 就可以运行容器。
- sealer 通过 Kubefile 构建一个 CloudImage,使用 Clusterfile 启动整个集群。
快速体验
下面我们一起制作和运行一个 Kubernetes dashboard 的集群镜像,来体验一个完整的流程。
编写 Kubefile:
# 基础镜像,已经被制作好了里面包含所有的kubernetes启动相关的依赖
FROM registry.cn-qingdao.aliyuncs.com/sealer-io/cloudrootfs:v1.16.9-alpha.7
# 下载官方的dashboard yaml编排文件,已经下载了可以使用COPY指令
RUN wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml
# 指定运行方式,可以使用kubectl helm kustomiz等
CMD kubectl apply -f recommended.yamlbuild dashboard 集群镜像:
sealer build -t kubernetes-with-dashobard:latest .
运行集群镜像:
# 下面命令会在服务器上安装k8s集群并apply dashboard, passwd指定服务器ssh密码,也可以使用密钥
sealer run kubernetes-with-dashobard:latest \
--master 192.168.0.2,192.168.0.3,192.168.0.4 \
--node 192.168.0.5,192.168.0.6 \
--passwd xxx
# 检查pod
kubectl get pod -A |grep dashboard把制作好的镜像推送到镜像仓库,兼容 docker registry:
sealer tag kubernetes-with-dashobard:latest docker.io/fanux/dashobard:latest
sealer push docker.io/fanux/dashobard:latest这样就可以把制作好的镜像交付出去或者提供给别人复用。
使用场景
sealer 具体能帮我们做哪些事呢?下面列举几个主要场景:
安装 Kubernetes 与集群生命周期管理(升级/备份/恢复/伸缩)
这是个最简单的场景,不管你是需要在单机上安装个开发测试环境,还是在生产环境中安装一个高可用集群;不管是裸机还是对接公有云,或者各种体系结构操作系统,都可以使用 sealer 进行安装,这里只安装 Kubernetes 的话就选择个基础镜像即可。
与其它的安装工具对比,sealer 优势在于:
- 简单到令人发指:sealer run 一条命令结束。
- 速度快到令人窒息:3min 装完 6 节点,可能你使用别的工具时还没下载完 sealer 就已经装完了,不仅如此,后续我们还有黑科技优化到 2min 甚至 1min 以内。
- 兼容性与稳定性:兼容各种操作系统,支持 x86 arm 等体系结构。
- 一致性设计:会让集群保持 Clusterfile 中的定义状态,以升级为例,只需要改一下 Clusterfile 中的版本号即可实现升级。
速度快是因为首先是 golang 实现,意味着我们可以对众多很细致的地方做并发的处理,这相比 ansible 就有了更多优势;而且还可以做更细致的错误处理,然后在镜像分发上抛弃以前 load 的方式;后续在文件分发上也会做优化,达到安装性能上的极致。
兼容性上,docker kubelet 采用了二进制+systemd 安装核心组件全容器化,这样不用再去依赖 yum/apt 这类感知操作系统的安装工具。ARM 和 x86 采用不同的镜像支持与 sealer 本身解耦开,对公有云的适配也抽离单独模块进行实现,这里我们没去对接 terraform,原因还是为了性能。在我们的场景下,terraform 启动基础设施将近 3min,而我们通过退避重试把基础设施启动优化到了 30s 以内,除此之外,在集群镜像场景下,不需要这么复杂的基础设施管理能力,我们不想让 sealer 变重也不想依赖一个命令行工具。
一致性的设计理念是 sealer 中值得一提的,集群镜像与 Clusterfile 决定了集群是什么样子,相同的镜像与 Clusterfile 就能 run 出个一样的集群。变更要么变更 Clusterfile,如增加节点、改变节点规格或者换镜像,换镜像时,由于集群镜像也是分层结构,所以 hash 值不变的 layer 不会发生变更,而 hash 发生变化会帮助重新 apply 该层。
云原生生态软件的打包/安装等,如 prometheus mysql 集群
sealer run prometheus:latest 就可以创建一个带有 prometheus 的集群,或者在一个已有的集群中安装 prometheus。
那么问题来了:它和 helm 啥区别?
- sealer 不关心编排,更注重打包,上面例子 prometheus 可以用 helm 编排,sealer 会把 chart 和 chart 里需要的所有容器镜像打包起来,这是在 build 的过程中通过黑科技做到的,因为 build 过程会像 docker build 一样起临时的 Kubernetes 集群,然后我们就知道集群依赖了哪些容器镜像,最后把这些容器镜像打包。
- 和 Kubernetes 一起打包,拿了一个 chart 它未必能安装成功,比如使用了废弃的 api 版本,但是做成镜像把 Kubnernetes 也包在一起了,只要 build 没问题,run 就没问题,这点和 docker 把操作系统 rootfs 打包在一起有异曲同工之妙。
- 集成性,集群镜像更关注整个分布式应用集群整体打包,如把 prometheus ELK mysql 集群做成一个镜像服务与业务。
所以 sealer 与helm是协作关系,分工明确。
后续可以在 sealer 的官方镜像仓库中找到这些通用的集群镜像,直接使用即可。
SaaS 软件整体打包/交付 专有云离线交付
从分布式应用的视角看,通常从上往下,少则几个多则上百的组件,现有整体交付方式大多都是面向过程的,中间需要很多进行干预的事,sealer 就可以把这些东西统统打包在一起进行一键交付。
可能你会问:我们做个 tar.gz 再加个 ansible 脚本不也能一键化吗?答案是肯定的。就和 docker 镜像出现之前,大家也通过 tar.gz 交付一样,你会发现标准和技术的出现解决了人与人之间的协作问题, 有了集群镜像就可以直接复用别人的成果,也能制作好东西供别人使用。
专有云场景就非常适合使用 sealer,很多客户机房都是离线的,而集群镜像会把所有依赖打到镜像中,只要镜像制作得好,那么所有局点都能以相同的方式进行一键交付,获得极佳的一致性体验。
在公有云上实践上述场景
sealer 自带对接公有云属性,很多情况下对接公有云会有更好的使用体验,比如安装集群时,只需要指定服务器数量和规格而不用关心 IP,伸缩直接修改 Clusterfile 中定义的数字即可。
技术原理简介
写时复制
集群镜像的存储也是通过写时复制的方式实现的。这样做有两个好处:我们可以把同一集群中不同的分布式软件打在不同层,以实现复用;还可以实现直接把集群镜像 push 到 docker 镜像仓库中。
容器镜像缓存
build 的过程中 sealer 是如何知道待构建的集群镜像里有哪些容器镜像,以及怎么把容器镜像存储下来呢?其中有一些难点问题:
- 如何知道分布式软件中有哪些容器镜像?因为我们需要把这些镜像缓存下来,不管是扫描用户的 yaml 文件还是用 helm template 之后扫描都是不完美的。首先不能确定用户的编排方式是什么,其次有些软件不把镜像地址写在编排文件中,而是通过自己的程序去拉起,无法保证 build 成功运行就一定没问题。
- 容器镜像是需要被存储到私有仓库中打包在集群镜像里,那容器镜像仓库地址势必和编排文件中写的不一样,特别是怎么保证用户 alwayPull 的时候还是能够在私有仓库中下载到镜像?
对待第一个问题,sealer 解决方式是:sealer build 的过程中和 Docker build 一样,会拉起一个临时的 Kubernetes 集群,并执行用户在 Kubefile 中定义的 apply 指令。

如上图所示,这样就可以保证用户依赖的所有镜像都被打包进去,无论用户使用什么样的编排方式。
第二个问题,我们打包容器镜像到私有镜像仓库中,怎样使用这个私有镜像也是个难题,假设私有镜像仓库名为 localhost:5000,肯定会和编排文件中写的不一致,对此我们有两种方式解决:
- 第一种是 hack 和 docker,做了一个只要私有镜像仓库中有就直接从私有镜像中拉取,没有才去公网拉取镜像的能力。
- 第二种方案是无侵入 docke r的 proxy,把 docker 请求全部打给代理,让代理去决定如果私有仓库有就从私有仓库拉取。同时我们还增强了 registry 的能力让 registry 可以 cache 多个远程仓库的能力。
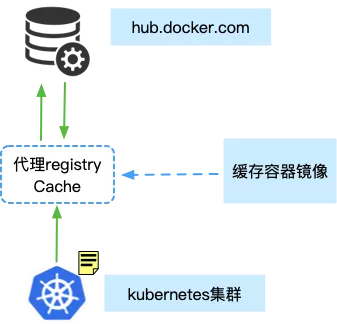
sealer 的这种方案完美解决了离线场景镜像打包的问题。
负载均衡
sealer 的集群高可用使用了轻量级的负载均衡 lvscare。相比其它负载均衡,lvscare 非常小仅有几百行代码,而且 lvscare 只做 ipvs 规则的守护,本身不做负载非常稳定,直接在 node 上监听 apiserver,如果跪了就移除对应的规则,重新起来之后会自动加回,相当于是一个专用的负载均衡器,在 sealos 项目中也用了两年多,有广泛的实践。
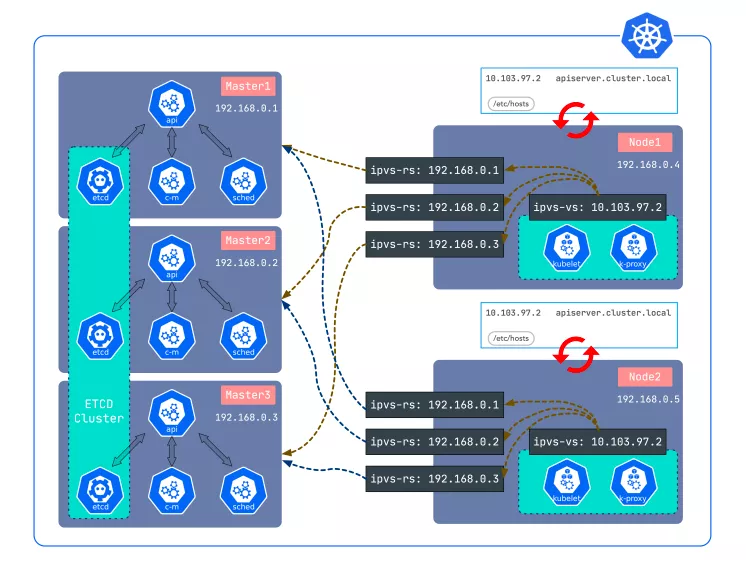
运行时
运行时就是支撑应用运行的环境,像 base on Kuberentes 的运行时 sealer 就可以透明地支持非常简单,以 istio 为例,用户只需要:
FROM kubernetes:v1.18.3
RUN curl -L https://istio.io/downloadIstio | sh -就可以 build 出一个 istio 的运行时供自己应用使用。
对于不是 base on Kuberentes 的运行时,如 k0s k3s,可以扩展 sealer.Runtime 中的接口,这样以后就可以:
FROM k3s:v1.18.3
RUN curl -L https://istio.io/downloadIstio | sh -更牛的扩展比如扩展 ACK 的 runtime:
FROM aliyum.com/ACK:v1.16.9
RUN curl -L https://istio.io/downloadIstio | sh -这种镜像会直接帮助用户应用运行到 ACK 上。以上有些能力在 roadmap 中。
基础设施
现在很多用户都希望在云端运行自己的集群镜像,sealer 自带对接公有云能力,sealer 自己实现的基础设施管理器,得益于我们更精细的退避重试机制,30s 即可完成基础设施构建(阿里云 6 节点)性能是同类工具中的佼佼者,且 API 调用次数大大降低,配置兼容 Clusterfile。
总结
sealer 未来的一些愿景与价值体现:
- sealer 可以以极其简单的方式让用户自定义集群,解决分布式软件制作者与使用者的协作问题。
- 极其简单友好的 User Interface,能屏蔽和兼容各种底层技术细节,到处运行。
- 生态建设,官方仓库里将会涵盖常用的分布式软件。
最后我们总结下:
- 如果你要整体交付你的分布式 SaaS,请用 sealer。
- 如果你要集成多个分布式服务在一起,如数据库消息队列或者微服务运行时,请用 sealer。
- 如果你要安装一个分布式应用如 mysql 主备集群,请用 sealer。
- 如果你需要安装/管理一个 Kubernetes 高可用集群,请用 sealer。
- 如果你要初始化多个数据中心,保持多个数据中心状态强一致,请用 sealer。
- 如果你需要在公有云上实现上述场景,请用 sealer。
sealer 将会在近期宣布开源,有兴趣的可以关注:_https://github.com/alibaba/sealer_
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。














