1、基本概念
在python中用双下划线开头的方式将属性隐藏起来(设置成私有的)
#其实这仅仅这是一种变形操作
#类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式:
class A:
__N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N
def __init__(self):
self.__X=10 #变形为self._A__X
def __foo(self): #变形为_A__foo
print('from A')
def bar(self):
self.__foo() #只有在类内部才可以通过__foo的形式访问到.
#A._A__N是可以访问到的,即这种操作并不是严格意义上的限制外部访问,仅仅只是一种语法意义上的变形
这种自动变形的特点:
- 类中定义的__x只能在内部使用,如self.__x,引用的就是变形的结果。
- 这种变形其实正是针对外部的变形,在外部是无法通过__x这个名字访问到的。
- 在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:_子类名__x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。
这种变形需要注意的问题是:
1、这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如a._A__N
2、变形的过程只在类的定义是发生一次,在定义后的赋值操作,不会变形
3、在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的
class A: __x = 100 # 类的私有数据属性 y = 200 def __init__(self, name): self.__name = name # 对象的私有属性 def __foo(self): # 类的私有方法 print('run foo')print(A.y)print(A._A__x)print(A._A__foo)print(A.__dict__)
正常情况下:#-------------------根基属性的查找顺序----------------
#正常情况
>>> class A:
... def fa(self):
... print('from A')
... def test(self):
... self.fa()
...
>>> class B(A):
... def fa(self):
... print('from B')
...
>>> b=B()
>>> b.test()
from B
#------------------封装的情况下-----------------------------class A:
def __fa(self): #在定义时就变形为_A__fa
print('from A')
def test(self):
self.__fa() # 只会与自己所在的类为准,即调用_A__fa
class B(A):
def __fa(self):
print('from B')
b = B()
b.test()结果:from A
2、封装不是单纯意义的隐蔽
2.1、封装数据属性(明确区分内外,控制外部队隐藏的属性操作)
将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口,然后我们可以在接口附加上对该数据操作的限制,以此完成对数据属性操作的严格控制。
class Teacher:
def __init__(self,name,age):
self.__name=name
self.__age=age
def tell_info(self):
print('姓名:%s,年龄:%s' %(self.__name,self.__age))
def set_info(self,name,age):
if not isinstance(name,str):
raise TypeError('姓名必须是字符串类型')
if not isinstance(age,int):
raise TypeError('年龄必须是整型')
self.__name=name
self.__age=age
t=Teacher('egon',18)
t.tell_info() # 通过接口访问 self
t.set_info('egon',19)
t.tell_info()
2.2、封装方法:目的是隔离复杂度
class ATM:
def __card(self):
print('插卡')
def __auth(self):
print('用户认证')
def __input(self):
print('输入取款金额')
def __print_bill(self):
print('打印账单')
def __take_money(self):
print('取款')
def withdraw(self):
self.__card()
self.__auth()
self.__input()
self.__print_bill()
self.__take_money()
a = ATM()
a.withdraw()
输出结果:
插卡
用户认证
输入取款金额
打印账单
取款
其他例子:
- 你的身体没有一处不体现着封装的概念:你的身体把膀胱尿道等等这些尿的功能隐藏了起来,然后为你提供一个尿的接口就可以了(接口就是你的。。。,),你总不能把膀胱挂在身体外面,上厕所的时候就跟别人炫耀:hi,man,你瞅我的膀胱,看看我是怎么尿的。
- 电视机本身是一个黑盒子,隐藏了所有细节,但是一定会对外提供了一堆按钮,这些按钮也正是接口的概念,所以说,封装并不是单纯意义的隐藏!!!
- 快门就是傻瓜相机为傻瓜们提供的方法,该方法将内部复杂的照相功能都隐藏起来了
提示:在编程语言里,对外提供的接口(接口可理解为了一个入口),可以是函数,称为接口函数,这与接口的概念还不一样,接口代表一组接口函数的集合体。
3、封装的可扩展性高
class Room:
def __init__(self,name,owner,height,weight,length):
self.name = name
self.owner = owner
self.__weight = weight #宽
self.__lenght = length #长
self.__height = height #高
def tell_area(self):
return self.__weight*self.__lenght
r = Room('卫生间','alex',10,10,5)
print(r.tell_area())# 使用者只需要调用r.tell_area(),不需要管里面变的属性
结果:50如果变为:
def tell_area(self):
return self.__weight*self.__lenght*self.__height
#对于仍然在使用tell_area接口的人来说,根本无需改动自己的代码,就可以用上新功能
4、特性(property,本质是一个函数)
class People:
def __init__(self,name,weight,height):
self.name = name
self.weight = weight
self.height = height
@property # 装饰器
def bim(self):
return self.weight/(self.height**2)
p1 = People('ehon',60,1.70)
print(p1.bim) #此时的bim相当于一个方法
4.1、为什么要用property
将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,
这种特性的使用方式遵循了统一访问的原则
除此之外,看下
ps:面向对象的封装有三种方式: 【public】 这种其实就是不封装,是对外公开的 【protected】 这种封装方式对外不公开,但对朋友(friend)或者子类(形象的说法是“儿子”,但我不知道为什么大家 不说“女儿”,就像“parent”本来是“父母”的意思,但中文都是叫“父类”)公开 【private】 这种封装对谁都不公开
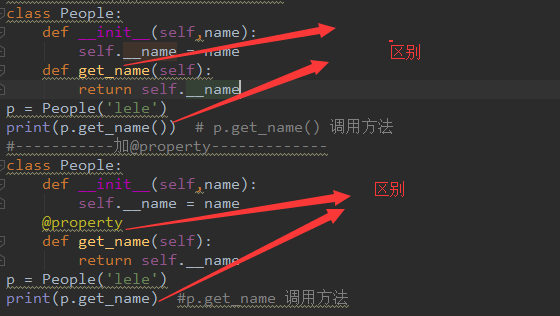
1、property是一种特殊的属性,访问它时会执行一段功能(函数)然后返回值
2、将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则(使用的原因)
3、一旦给函数加上一个装饰器@property,调用函数的时候不用加括号就可以直接调用函数了
class Student:
@property
def fun(self):
print("1111111")
if __name__ == '__main__':
student = Student()
student.fun