
问题场景
假设有三台缓存服务器节点分别为C1、C2、C3,对于一个key,又客户端来决定存放到哪台节点,简单的办法就是 hash(key) % N,其中N是节点的总数。一旦节点扩容或者宕机后,N发生变化,那之前缓存的数据都将失效
如果简单的使用hash(key) % N 算法会出现以下问题
(1)当缓存节点数量发生变化时,会引起缓存的雪崩(同一时间大量缓存失效,引起整体系统压力过大)
(2)当缓存节点数量发生变化时,几乎所有缓存的位置或者说散列地址都发生改变
针对上述问题场景,如果希望达到节点扩容或宕机缓存失效的数目降低最低,我们可以通过一致性哈希环来解决90%的失效问题
普通的Hash表
了解环之前我们先了解下Hash的由来,Hash,一般翻译做散列 或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系 f,使得每个关键字key 对应一个存储位置f(key)。查找时根据这个确定的对应关系找到给定值 key 的映射 f(key) ,若查找集合中存在这个记录,则必定在 f(key) 的位置上。
我们把这种对应关系 f 称为散列函数,又称为 哈希(Hash)函数,采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或者哈希表(Hash table)
一致性哈希算法
Hash环【经典实现】
服务节点映射到环
问题场景中是对服务器节点的数量进行取模,而一致性哈希算法是对2^32取模,假定一个Hash函数,其值空间为(0到2^32-1) 无整型数字 ,把这些数字组成一个环
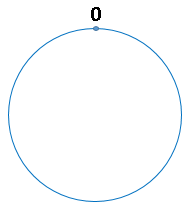
圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1,把这个由2的32次方个点组成的圆环称为hash环
那么一致性哈希算法和上图中的圆环有什么关系呢?
以上问题场景中的服务器节点IP为例,使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模,可以使用如下公式示意。
第一个节点计算: hash(192.168.0.1) % 2^32
通过上述公式算出的结果一定是一个0到2^32-1之间的一个整数,假设这个整数我们定义为A,我们就用这个整数A代表节点C1,既然这个整数肯定处于0到2^32-1之间,那么,上图中的hash环上必定有一个点与这个整数对应,那么A就可以映射到这个环上,用下图示意
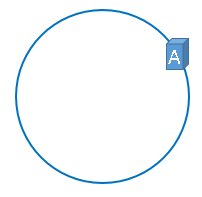
同理,我们依次计算出剩余两个节点的值
第二个节点计算: hash(192.168.0.2) % 2^32 = B
第二个节点计算: hash(192.168.0.3) % 2^32 = C
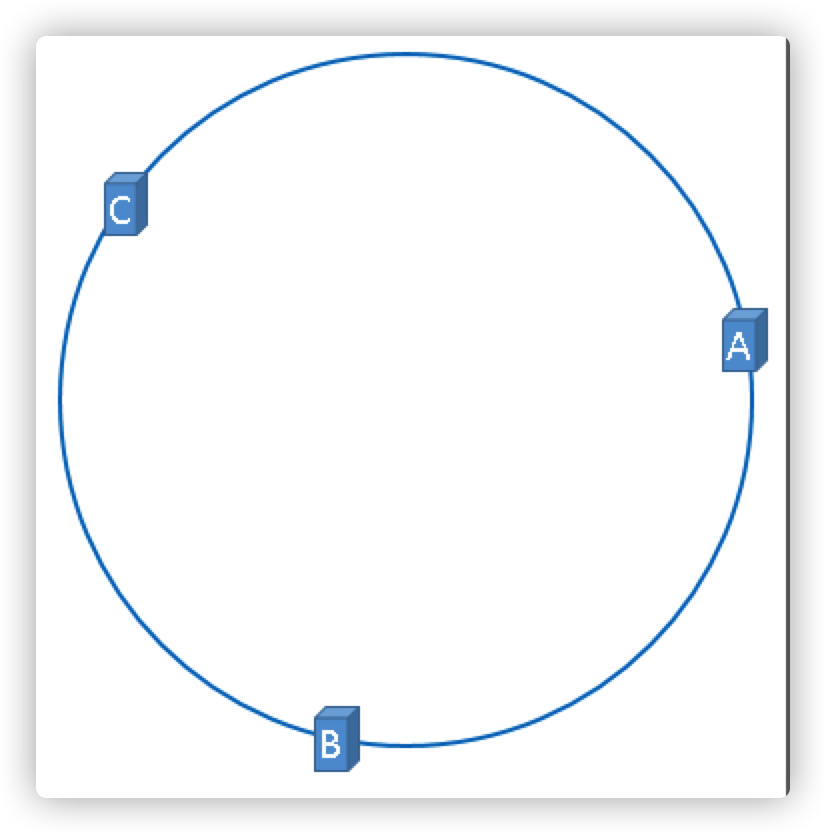
目前我们已经缓存节点和Hash环对应上了,那对于缓存的数据也一样使用同样的方法依次映射到hash环上
缓存数据映射到环
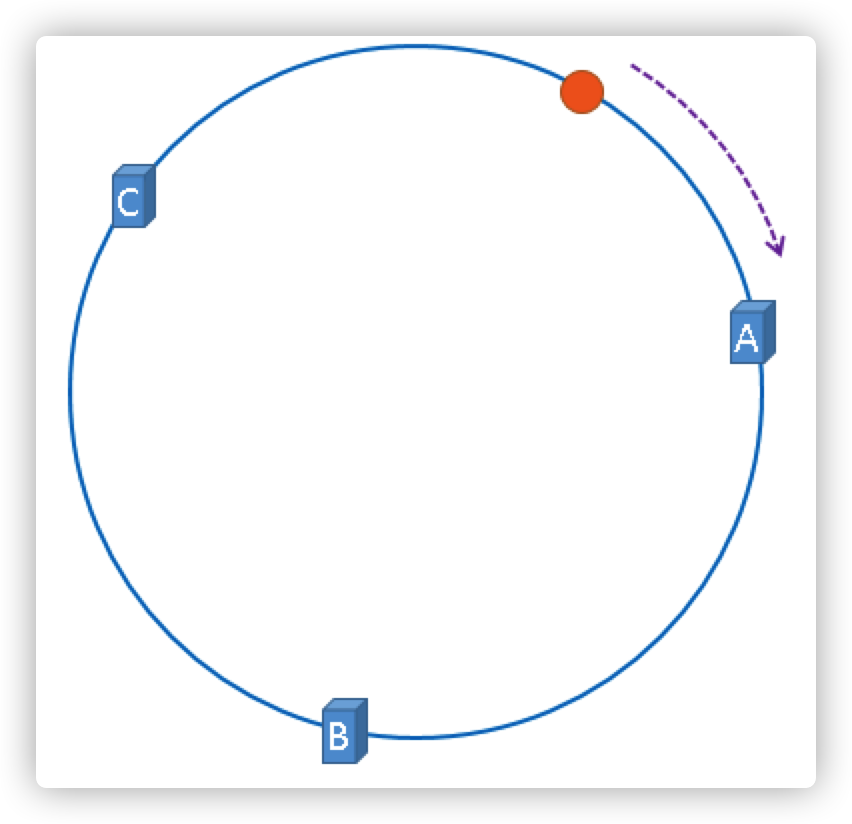
假设我们缓存的是内容是用户的会话连接ID,通过 hash(connectionId) % 2^32 得到一个整数,用橘黄色圆形表示图片
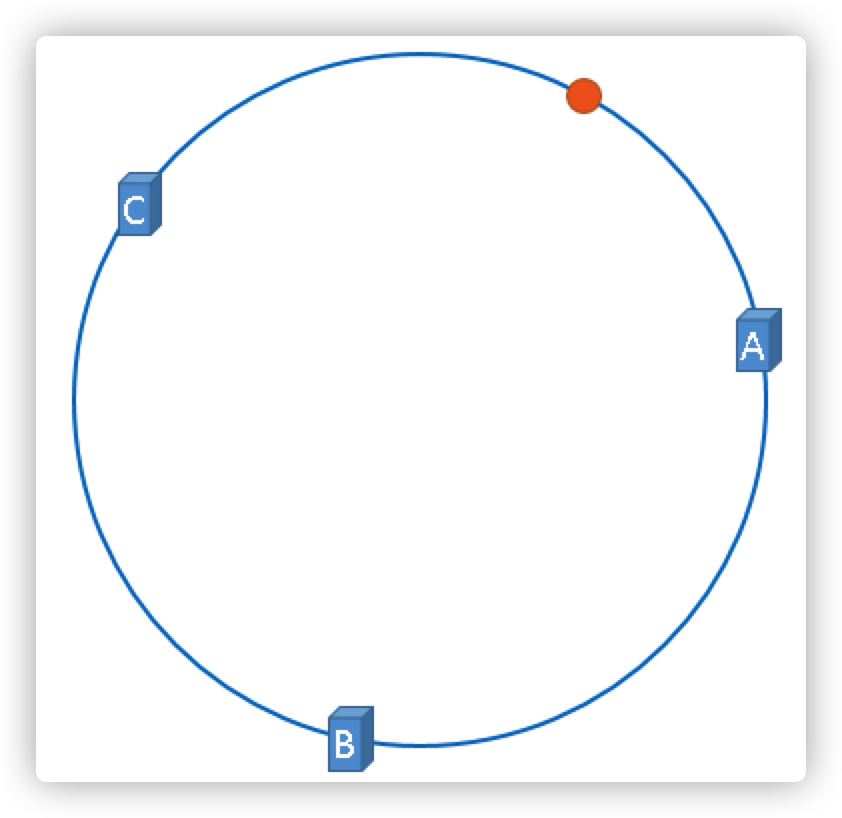
那么上图中的这个橘黄色的圆点到底应该被缓存到哪一个节点上呢?
按照一致性哈希的约定,沿顺时针方向遇到的第一个服务器就是A服务器,所以,上图中的橘黄色的圆点被缓存到服务器A上,如下图所示
如果是多个用户的会话连接ID呢?
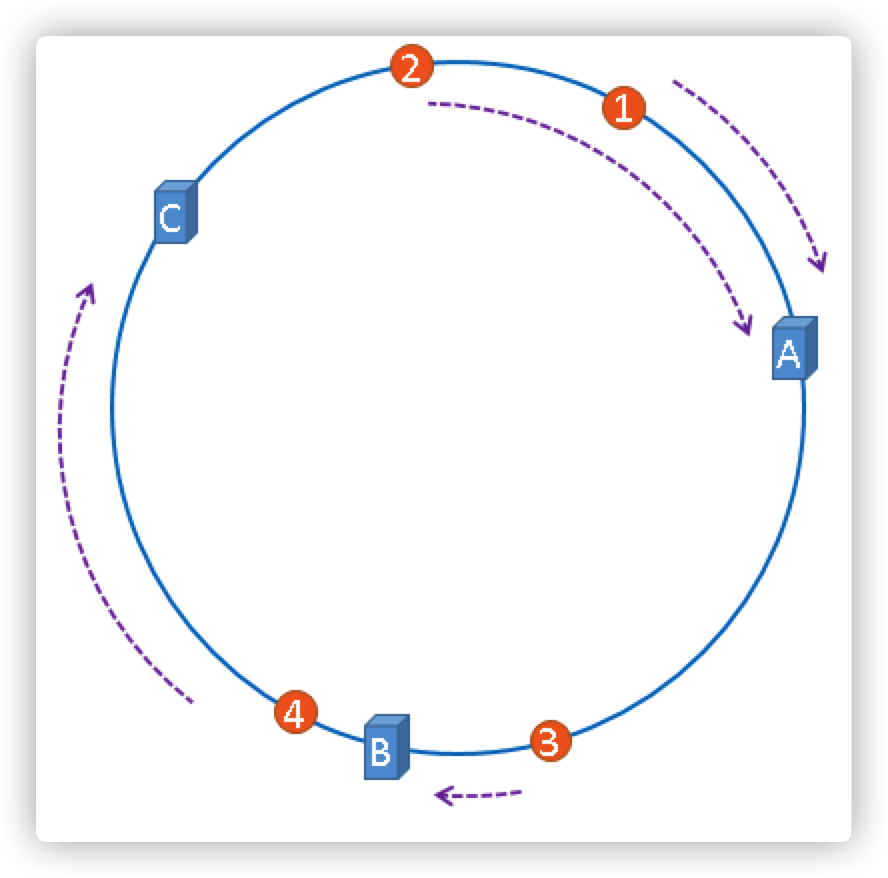
一致性哈希算法就是通过这种方法,判断一个对象应该落到哪台服务器上的,将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存于的服务器,由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,被缓存的对象必定会被缓存到固定的服务器上,那么,当下次想要访问这个缓存对象时,只要再次使用相同的算法进行计算,即可算出这个缓存对象被缓存在哪个服务器上。
把上述节点映射和值映射的过程归纳总结成以下两点
普通的hash函数,只经过了1次hash,即把key hash到对应的机器编号,而hash环有两次hash过程:
(1)把所有节点特定的值(IP、设备号或其他特定标识)hash到这个环上
(2)把key也hash到这个环上。然后在这个环上进行匹配,看这个key落在哪个节点范围
优点/缺点
优点:节点的扩容和宕机不会到导致全局重新映射,而只需要做增量的重新映射
缺点:hash环偏斜
上文中理想的hash环效果如下图
实际的节点映射有可能会被映射为下图
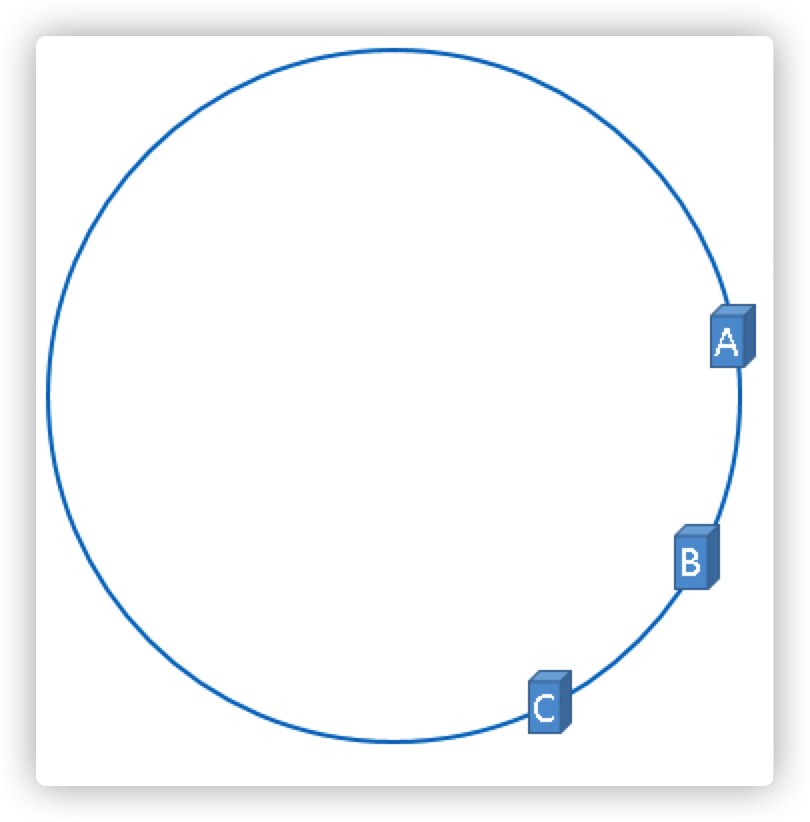
那被缓存的对象数据就大部分集中缓存在某一台服务器上,如下图
如果出现上图中的情况,A、B、C三台服务器并没有被合理的平均利用,缓存分步不均匀,上图的这种情况被称之为hash环偏斜
虚拟节点
在真正的物理服务器节点不变的情况下,如何凭空补足不均衡的节点?只能将现有的物理节点通过虚拟的方法复制出来,而这些被复制出来的节点就称为虚拟节点。加入了虚拟节点的hash环如下图
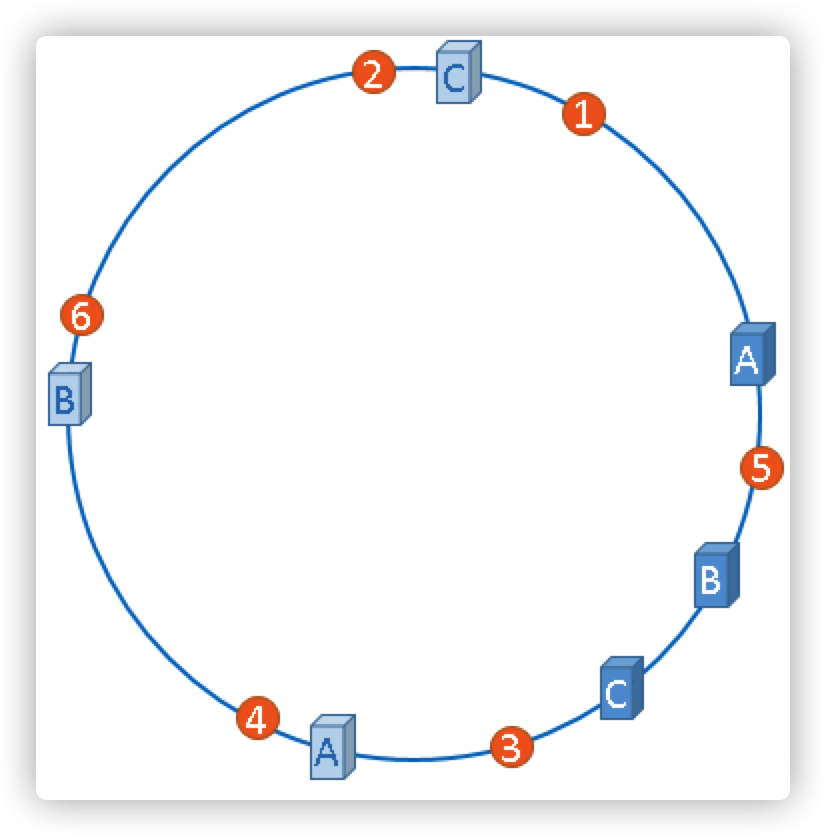
如果你还不放心,可以虚拟出更多的虚拟节点,以便减小hash环偏斜所带来的影响,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大。
是不是越多虚拟节点越好?到点一个物理节点复制多少虚拟节点合适呢?
我们拿一致性哈希算法的实现来举例,其中较为有名的一种实现叫Ketama算法,该算法最初是由Last.fm的程序员实现的并得到了广泛的应用,一些开源框架譬如spymemcached,twemproxy等都内置了该算法的实现
Ketama算法一般采用一个节点对应40个虚拟节点。 原因是,节点越多、映射的分布越均匀, 采用虚拟节点可以减少真实节点之间的负载差异。
关于一致性哈希算法的映射结果仍然不是很均匀
With 100 replicas (“vnodes”) per server, the standard deviation of load is about 10%. Increasing the number of replicas to 1000 points per server reduces the standard deviation to ~3.2%.
当有100个虚拟节点时,哈希环法的映射结果的分布的标准差大约有 10%10%。 当虚拟节点增加到1000个时,这个标准差降到 3.2%3.2% 左右
虚拟节点是一个绝妙的设计,不仅提高了映射结果的均匀性, 而且为实现加权映射提供了方式。但是,虚拟节点增加了内存消耗和查找时间**, 以常用的ketama为例, 每个节点都对应40个影子节点, 内存的消耗从 O(n)O(n) 变为 O(40n)O(40n) , 查找时间从 O(logn)O(logn) 变为 O(log(40n))O(log(40n)) 。
Hash环下的热扩容和容灾
对于增删节点的情况,哈希环法做到了增量式的重新映射, 不再需要全量数据迁移的工作。 但仍然有部分数据出现了变更前后映射不一致, 技术运营上仍然存在如下问题:
- 扩容:当增加节点时,新节点需要对齐下一节点的数据后才可以正常服务。
- 缩容:当删除节点时,需要先把数据备份到下一节点才可以停服移除。
- 故障:节点突然故障不得不移除时,面临数据丢失风险。
如果我们要实现动态扩容和缩容,即所谓的热扩容,不停止服务对系统进行增删节点, 可以这样做:
- 数据备份(双写): 数据写入到某个节点时,同时写一个备份(replica)到顺时针的邻居节点。
- 请求中继(代理): 新节点刚加入后,数据没有同步完成时,对读取不到的数据,可以把请求中继(replay)到顺时针方向的邻居节点。
下面的图7.1中演示了这两种规则:
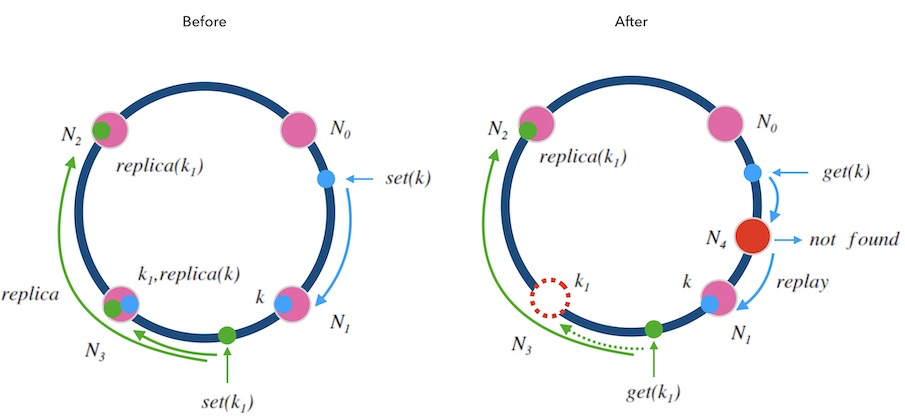
- 移除节点的情况: 每一个节点在执行写请求时,都会写一个备份到顺时针的邻居节点。 这样,当 N3N3 节点因故障需要踢除时,新的请求会交接给它的邻居节点 N2, N2 上有 k1 的备份数据,可以正常读到。
新增节点的情况: 对于新增节点的情况稍微复杂点, 当新增节点 N4 时, N4 需要从邻居节点 N1 上同步数据, 在同步仍未完成时,可能遇到的请求查不到数据, 此时可以先把请求中继给 N1 处理, 待两个节点数据对齐后,再结束中继机制。
就像细胞分裂一样, N4 刚加入时可以直接算作时 N3 的一部分, N3 算作一个大节点, 当数据对齐后, N4 再从 N3 中分裂出来,正式成为新节点。
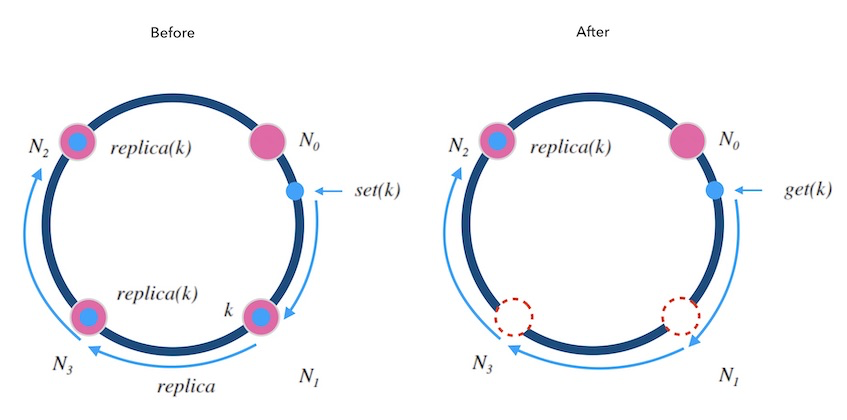
另外, 可以备份不止一份。 下面图7.2中演示了备份两次情况, 每个写请求都将备份同步到顺时针方向的最近的两个节点上。 这样就可以容忍相邻的两节点损失的情况, 进一步提高了系统的可用性
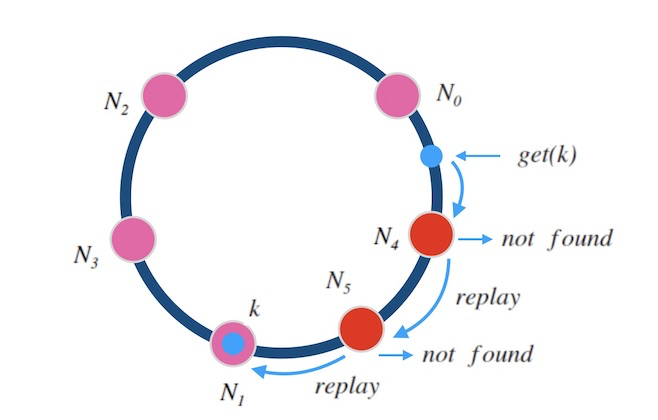
同样的,中继也可以不止一次。 下面图7.3中演示了中继两次的情况, 如果一个节点上查不到数据,就中继给下一个节点,最多两次中继, 这样就可以满足同时添加”两个正好在环上相邻的”节点的情况了。
跳跃一致性哈希法
跳跃一致性哈希 ( Jump Consistent Hash ) 是 Google 于2014年发布的一个极简的、快速的一致性哈希算法
Maglev一致性哈希法
Maglev哈希算法来自 Google , 在其2016年发布的一篇论文中:https://writings.sh/post/cons..., 介绍了自2008年起服役的网络负载均衡器Maglev, 文中包括Maglev负载均衡器中所使用的一致性哈希算法,即Maglev一致性哈希 (Maglev Consistent Hashing)。
环的应用场景
定时任务调度
我们以xxl-job任务调度框架中的调度部分的源码来分析下环的应用场景,其中任务定时触发的JobScheduleHelperCron这个阶段流程图如下:
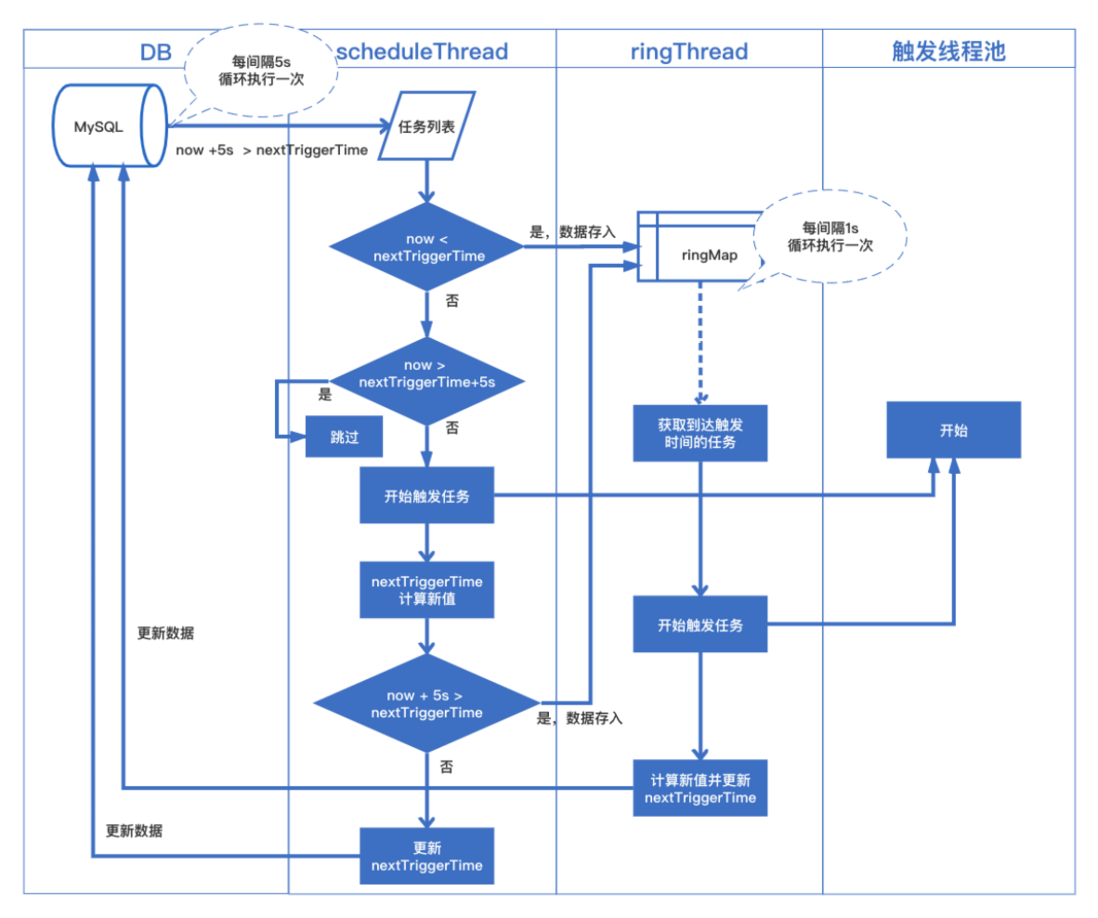
其中最重要的是部分源代码如下
public void start() {
// schedule thread
scheduleThread = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis() % 1000);
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
logger.info(">>>>>>>>> init xxl-job admin scheduler success.");
// pre-read count: treadpool-size * trigger-qps (each trigger cost 50ms, qps = 1000/50 = 20)
int preReadCount = (XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax() + XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax()) * 20;
while (!scheduleThreadToStop) {
// Scan Job
long start = System.currentTimeMillis();
Connection conn = null;
Boolean connAutoCommit = null;
PreparedStatement preparedStatement = null;
boolean preReadSuc = true;
try {
conn = XxlJobAdminConfig.getAdminConfig().getDataSource().getConnection();
connAutoCommit = conn.getAutoCommit();
conn.setAutoCommit(false);
preparedStatement = conn.prepareStatement("select * from xxl_job_lock where lock_name = 'schedule_lock' for update");
preparedStatement.execute();
// tx start
// 1、pre read
long nowTime = System.currentTimeMillis();
List<XxlJobInfo> scheduleList = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount);
if (scheduleList != null && scheduleList.size() > 0) {
// 2、push time-ring
for (XxlJobInfo jobInfo : scheduleList) {
// time-ring jump
if (nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS) {
// 2.1、trigger-expire > 5s:pass && make next-trigger-time
logger.warn(">>>>>>>>>>> xxl-job, schedule misfire, jobId = " + jobInfo.getId());
// 1、misfire match
MisfireStrategyEnum misfireStrategyEnum = MisfireStrategyEnum.match(jobInfo.getMisfireStrategy(), MisfireStrategyEnum.DO_NOTHING);
if (MisfireStrategyEnum.FIRE_ONCE_NOW == misfireStrategyEnum) {
// FIRE_ONCE_NOW 》 trigger
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.MISFIRE, -1, null, null, null);
logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId());
}
// 2、fresh next
refreshNextValidTime(jobInfo, new Date());
} else if (nowTime > jobInfo.getTriggerNextTime()) {
// 2.2、trigger-expire < 5s:direct-trigger && make next-trigger-time
// 1、trigger
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);
logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId());
// 2、fresh next
refreshNextValidTime(jobInfo, new Date());
// next-trigger-time in 5s, pre-read again
if (jobInfo.getTriggerStatus() == 1 && nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()) {
// 1、make ring second
int ringSecond = (int) ((jobInfo.getTriggerNextTime() / 1000) % 60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
} else {
// 2.3、trigger-pre-read:time-ring trigger && make next-trigger-time
// 1、make ring second
int ringSecond = (int) ((jobInfo.getTriggerNextTime() / 1000) % 60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
}
// 3、update trigger info
for (XxlJobInfo jobInfo : scheduleList) {
XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleUpdate(jobInfo);
}
} else {
preReadSuc = false;
}
// tx stop
} catch (Exception e) {
if (!scheduleThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread error:{}", e);
}
} finally {
// commit
if (conn != null) {
try {
conn.commit();
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
try {
conn.setAutoCommit(connAutoCommit);
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
try {
conn.close();
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
// close PreparedStatement
if (null != preparedStatement) {
try {
preparedStatement.close();
} catch (SQLException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
}
long cost = System.currentTimeMillis() - start;
// Wait seconds, align second
if (cost < 1000) { // scan-overtime, not wait
try {
// pre-read period: success > scan each second; fail > skip this period;
TimeUnit.MILLISECONDS.sleep((preReadSuc ? 1000 : PRE_READ_MS) - System.currentTimeMillis() % 1000);
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread stop");
}
});
scheduleThread.setDaemon(true);
scheduleThread.setName("xxl-job, admin JobScheduleHelper#scheduleThread");
scheduleThread.start();
// ring thread
ringThread = new Thread(new Runnable() {
@Override
public void run() {
while (!ringThreadToStop) {
// align second
try {
TimeUnit.MILLISECONDS.sleep(1000 - System.currentTimeMillis() % 1000);
} catch (InterruptedException e) {
if (!ringThreadToStop) {
logger.error(e.getMessage(), e);
}
}
try {
// second data
List<Integer> ringItemData = new ArrayList<>();
int nowSecond = Calendar.getInstance().get(Calendar.SECOND); // 避免处理耗时太长,跨过刻度,向前校验一个刻度;
for (int i = 0; i < 2; i++) {
List<Integer> tmpData = ringData.remove((nowSecond + 60 - i) % 60);
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
// ring trigger
logger.debug(">>>>>>>>>>> xxl-job, time-ring beat : " + nowSecond + " = " + Arrays.asList(ringItemData));
if (ringItemData.size() > 0) {
// do trigger
for (int jobId : ringItemData) {
// do trigger
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
}
// clear
ringItemData.clear();
}
} catch (Exception e) {
if (!ringThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread error:{}", e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread stop");
}
});
ringThread.setDaemon(true);
ringThread.setName("xxl-job, admin JobScheduleHelper#ringThread");
ringThread.start();
}
一个把任务丢到时间环场景代码如下
// 1、make ring second //计算当前任务触发时间 取模,定位到具体某个秒
int ringSecond = (int) ((jobInfo.getTriggerNextTime() / 1000) % 60);
// 2、push time ring //放到时间环中
pushTimeRing(ringSecond, jobInfo.getId());
private void pushTimeRing(int ringSecond, int jobId) {
// push async ring
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList<Integer>();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
logger.debug(">>>>>>>>>>> xxl-job, schedule push time-ring : " + ringSecond + " = " + Arrays.asList(ringItemData));
}循环从时间环中取出任务执行的代码如下
try {
// second data
List<Integer> ringItemData = new ArrayList<>();
int nowSecond = Calendar.getInstance().get(Calendar.SECOND); // 避免处理耗时太长,跨过刻度,向前校验一个刻度;
for (int i = 0; i < 2; i++) {
List<Integer> tmpData = ringData.remove((nowSecond + 60 - i) % 60);
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
// ring trigger
logger.debug(">>>>>>>>>>> xxl-job, time-ring beat : " + nowSecond + " = " + Arrays.asList(ringItemData));
if (ringItemData.size() > 0) {
// do trigger
for (int jobId : ringItemData) {
// do trigger
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
}
// clear
ringItemData.clear();
}
} catch (Exception e) {
if (!ringThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread error:{}", e);
}
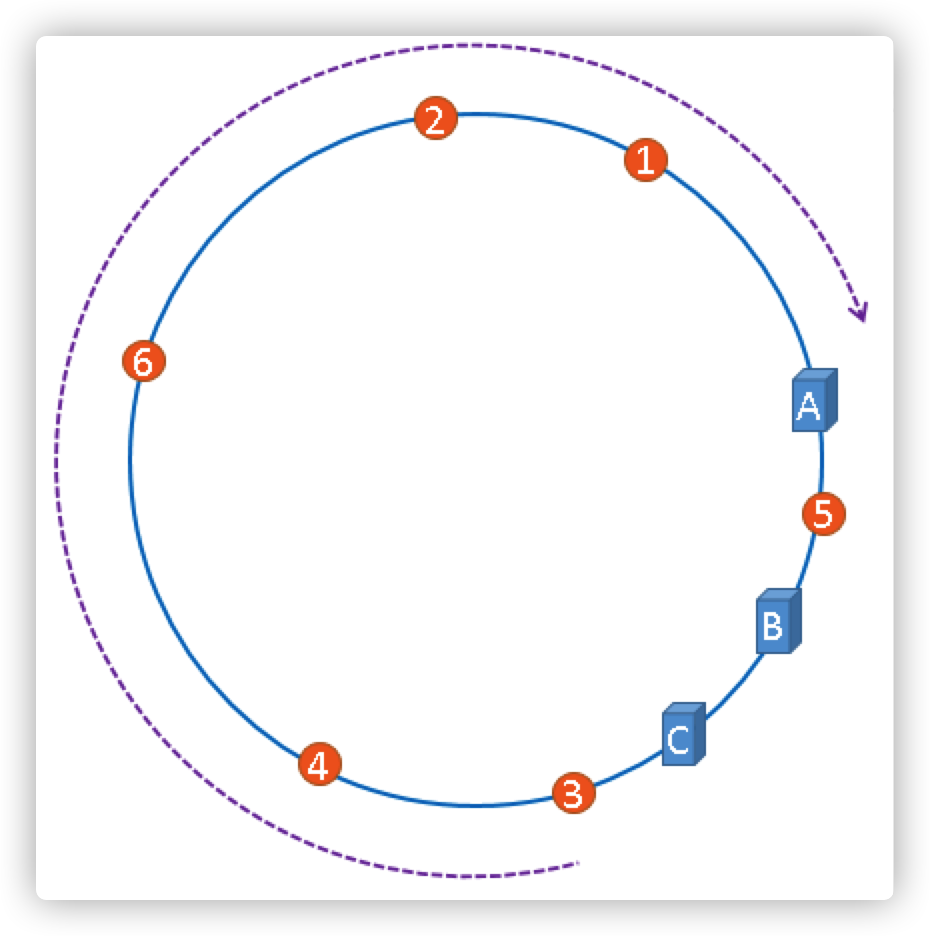
}时间环如下图所示
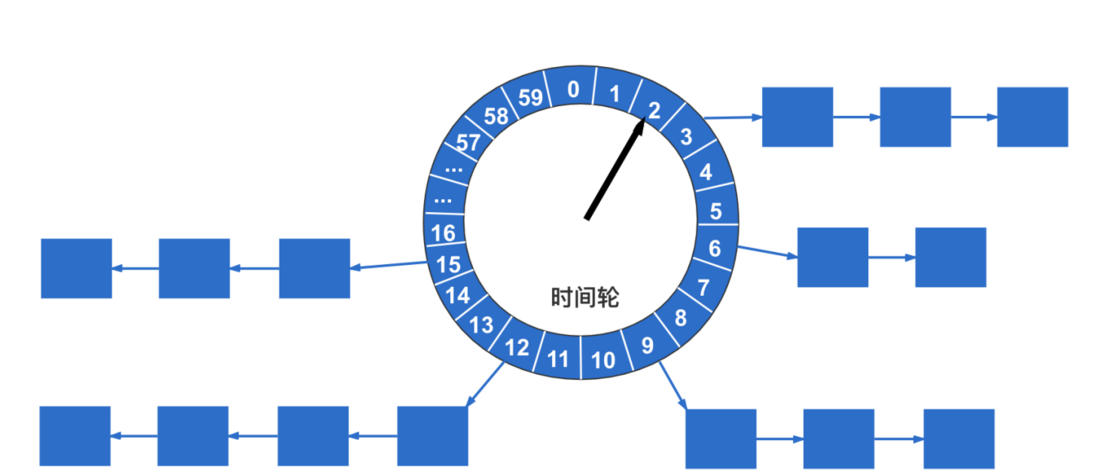
通过ringThread无限循环执行这个时间环上的任务,实现任务的定时触发






