
baiyan
全部视频:https://segmentfault.com/a/11...
为什么需要ziplist
乍一看标题,我们可能还不知道ziplist是何许人也。但是如果我说list、hash、zset这几种数据结构,大家就很熟悉了。而ziplist就是这几种数据结构的底层实现之一:
- list:3.2.x之前为(ziplist + linkedlist)之后为quicklist
- hash:数据量小的时候使用ziplist,量大时使用hashtable(dict)
- zset:数据量小的时候使用ziplist,量大时使用skiplist + hashtable
我们可以看到,ziplist总是在一种列表、哈希、有序集合这几种结构在存储的数据量小的时会使用。随着数据量的增长,会转换到相对应较复杂的类型。我们可以猜测,ziplist是一种轻巧、简单、且占用内存小的数据结构。它能够解决在redis数据量小时的存储问题。
ziplist的结构
在redis的设计思想中,大多数情况下,都是以时间换空间。由于redis基于内存,且内存资源是相当宝贵的,所以节省空间的“性价比”相对于节省时间,显然更高一些。在学习数据结构与算法的过程中,我们常常将数组和链表放在一起比较。由于数组使用一块连续的内存,而链表分为指针域和数据域,数组在空间利用率上明显要高于链表。参考以上设计思想,如果让我们自己去设计ziplist的结构,我们如何思考呢?
- 需要一块连续的内存空间去存储真正的数据
- 需要一些额外的信息字段去记录它的长度、结束标志、还有数据的总量等辅助信息
在ziplist中,是按照如下结构进行存储的,是否符合你的预期呢?
每个字段的含义如下:
- zlbytes:4个字节。记录压缩列表总共占用的字节数,在对压缩列表进行内存重分配时使用
- zltail:4个字节。可通过这个字段快速定位到链表末尾
- zllen:2个字节。记录总共有多少个entry
- entry:具体数据的内容就存在这里
- zlend:1个字节。为十六进制值0xFF,标记一个压缩列表的末尾
具体的数据存放在entry中。在ziplist中,可以存储两种数据:
- 字符串(字节数组)
- 整数
举一个例子,一个zset在数据量少的情况下,会将元素名和分值按从小到大的顺序在ziplist的entry中连续存储:
那么问题来了,我们在读取数据的时候,我们怎么知道是应该按照读取字符串还是整数类型的方式去读取呢?我们需要知道当前entry存储数据的类型,即一个encoding字段,用来标识当前entry数据的类型。
除此之外,我们在查找一个元素的时候,需要对其进行遍历,在ziplist中是如何遍历的呢?回想我们在数组中的遍历方式:
普通数组的遍历是根据数组里存储的数据类型来找到下一个元素的,例如int类型的数组(也是指针)访问下一个元素时每次只需要加上相应类型的指针偏移量即可(如果用下标法表示数组,p[0]到p[1]就等效于p+1*sizeof(int)这个过程;如果用指针法,可以用p+1来表示,它也等效于p+1*sizeof(int))
那么在ziplist中,我们不知道数据类型,也不知道这个数据的长度,该如何将遍历用的指针往后挪呢?这就需要一个字段去完成这个任务,这里就是previous_entry_length,它记录前一个entry的长度,可以利用它完成压缩列表的遍历
最后,就是最重要的字段,即存储真正数据的字段content
以我们上图的例子,继续我们画出entry的结构: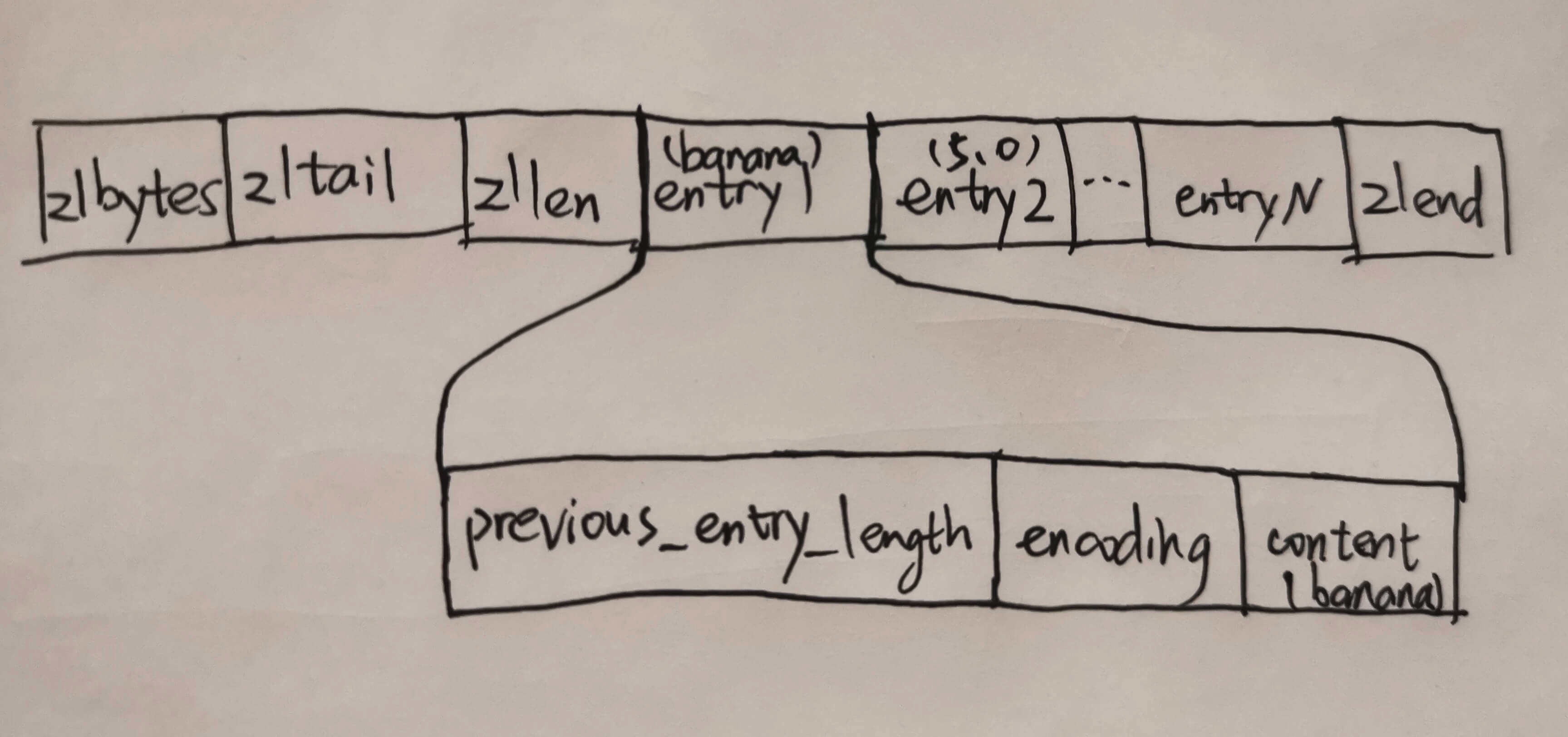
- previous_entry_length:记录了压缩列表中前一个entry的长度。占用1或5字节
- encoding:表示当前entry存储数据的类型与数据的长度。占用1、2或5字节
- content:真正存储数据的地方
ziplist的遍历
遍历是查找操作的基础,学习任意一种数据结构,遍历都是关键。
正向遍历
正向遍历ziplist:首先指针p在第一个entry的起始位置,即previous_entry_length字段的位置。由于previous_entry_length可能占用1个字节、也可能占用5个字节,所以我们需要知道如何区分这个字段占用了1还是5字节。表示方法如下:
- 如果前一个entry的长度小于254字节时,previous_entry_length用1字节表示
- 如果前一个entry的长度大于等于254字节时,previous_entry_length用5字节表示。注意此时第一个字节是固定的标志0xFE(254),后面4个字节用来表示前一个entry的长度
- 这样一来,我们就能够知道:由于我们当前的指针为unsigned char *类型(见源码),指针运算p+1就等于往后偏移1个字节(即8位)。所以只需要读取当前指针的第一个字节的内容,即p[0]的值是否在二进制的00000000 ~ 11111110(即0~254)之间。如果在这个区间内,就说明previous_entry_length只占用1个字节,使用p+1就能够得到encoding的首地址了;如果p[0]的值为11111111(255),说明previous_entry_length占用了5个字节,使用p+5也能够得到encoding的首地址。
- 现在我们的指针来到了encoding字段起始地址的位置。那么,encoding字段是如何存储数据类型和长度的呢?为了节省encoding字段所占用的内存空间,将所有字符数组(字符串)类型以及整数类型按照如下编码方式区分:

- 观察上图encoding的编码方式,我们发现,只需要读取当前指针位置往后偏移两位的内容,就能够得到encoding字段的长度。(00、11占用1字节;01占用2字节;10占用5字节)。那么我们相应的p+1、p+2、p+5即可将指针偏移到content的位置。
- 由于我们在encoding字段中知道content字段的数据类型的长度(如int16等)再将指针往后偏移之前encoding字段中存储的的相应数据类型长度,就可以偏移到content字段的末尾了。后面如果有多个同样的entry结构,也同理,这样就成功实现了ziplist的正序遍历。
反向遍历
由于previous_entry_length字段的存在,我们首先取出外部zltail字段,也就是指向ziplist结构末尾的指针,然后一次又一次地将指针减去entry中previous_entry_length字段的值,就能够将指针偏移到ziplist的头部,原理很简单,相信大家都能够理解,不再赘述。所以我们能够发现,ziplist更适合从后往前遍历。
redis编码转换的根本原因
- 其实ziplist就是借鉴了数组的思想,skiplist借鉴了链表的思想。不管是正向还是反向遍历,还是在ziplist的插入或者删除中需要将后面的元素往后挪或者往前挪,所有操作的复杂度均为O(n)。比起zset的另一种实现dict+skiplist中查询O(1)的时间复杂度,还有插入以及删除的O(logn)复杂度,ziplist在效率方面并没有优势。但是我们之前讲过,redis的设计思想一般都是以时间换空间,所以,相比skiplist需要维护大量的指针、在多层上面重复的数据(skiplist占用的空间为2n,详情请看上一篇笔记),ziplist在空间复杂度上优势尽显。
- 但是我们不得不说,ziplist在时间复杂度上面的劣势依然存在,所以我们不能把劣势无限放大开来,而是要扬长避短。所以,redis开发者也反复权衡,考虑到了这一点。就拿zset来说,只有符合如下两个条件,才会使用ziplist编码,否则使用skiplist进行编码:
- zset中的对象保存的元素数量不超过128个
- zset中保存的所有元素成员的长度小于64字节
- 这样一来,由于ziplist只处理少量、且规模很小的数据,这使得时间复杂度O(n)在ziplist处理少量数据的时候,这个n是非常小的。所以,这样就能够将其时间复杂度的影响降到了最低,将其空间复杂度的优势发挥到最大,这就是为什么需要进行编码转换的根本原因。
至于ziplist的关键之处就讲完了。至于其增删改查的具体源码,有兴趣的读者可以去ziplist.c中深入查看,笔者在这篇文章里再复制粘贴一次意义也不大。学习的过程中,我阅读了大量的资料,但是内容质量参差不齐。这里我想说,我们在学习一种新知识的时候,不仅仅要知道它是什么样子,也要知道它为什么是这样的、为什么这么做而不采用其它的替代方案?它的比较优势在哪里?而不要简单的堆砌概念。在学习的同时,如果没有经过自己的思考,收效甚微。











