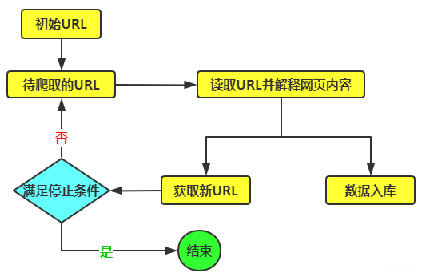
字体反爬案例
爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用 python 爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码。这种一般是网站设置了字体反爬。
1. 准备url
网址: https://www.iesdouyin.com/sha...
2. 获取数据 分析字体加密方式
任务:爬取个人信息展示页中的关注、粉丝人数和点赞数据,页面内容如图 下 所示。

在编写代码之前,我们需要确定目标数据的元素定位。定位时,我们在 HTML 中发现了一些奇怪的符号,HTML 代码如下:

页面中重要的数据都是一些奇怪的字符,本应该显示数字的地方在 HTML 中显示的是""。
要注意的是,Chrome 开发者工具的元素面板中显示的内容不一定是相应正文的原文,要想知道 "" 符号是什么,还需要到网页源代码中确认。对应的网页源代码如下:
</span><span class="follower block"> <span class="num"> <i class="icon iconfont follow-num">  </i> <i class="icon iconfont follow-num">  </i> <i class="icon iconfont follow-num">  </i> <i class="icon iconfont follow-num">  </i>. <i class="icon iconfont follow-num">  </i>w </span> <span class="text">粉丝</span> </span>抖音将这些数字的数据都做了字体进行映射,用了他们自己的字体,那我们可以看看开发者工具的 network 查看他所用的字体,一般都是 wolf 或者 ttf 结尾的,可以看到:

我们多刷新几次,发现一直访问的是这个字体文件:
https://s3.pstatp.com/ies/res..._falcon/static/font/iconfont_9eb9a50.woff
我们先把这个文件下载下来,font creator软件打开,看到这个图片我们就明白了字体与数字的关系

这个时候,需要大家安装pip install fontTools,使用fontTool打开ttf文件转化成xml文件
采用以下代码
from fontTools.ttLib import TTFontfont_1 = TTFont('douyin.ttf')font_1.saveXML('font_1.xml')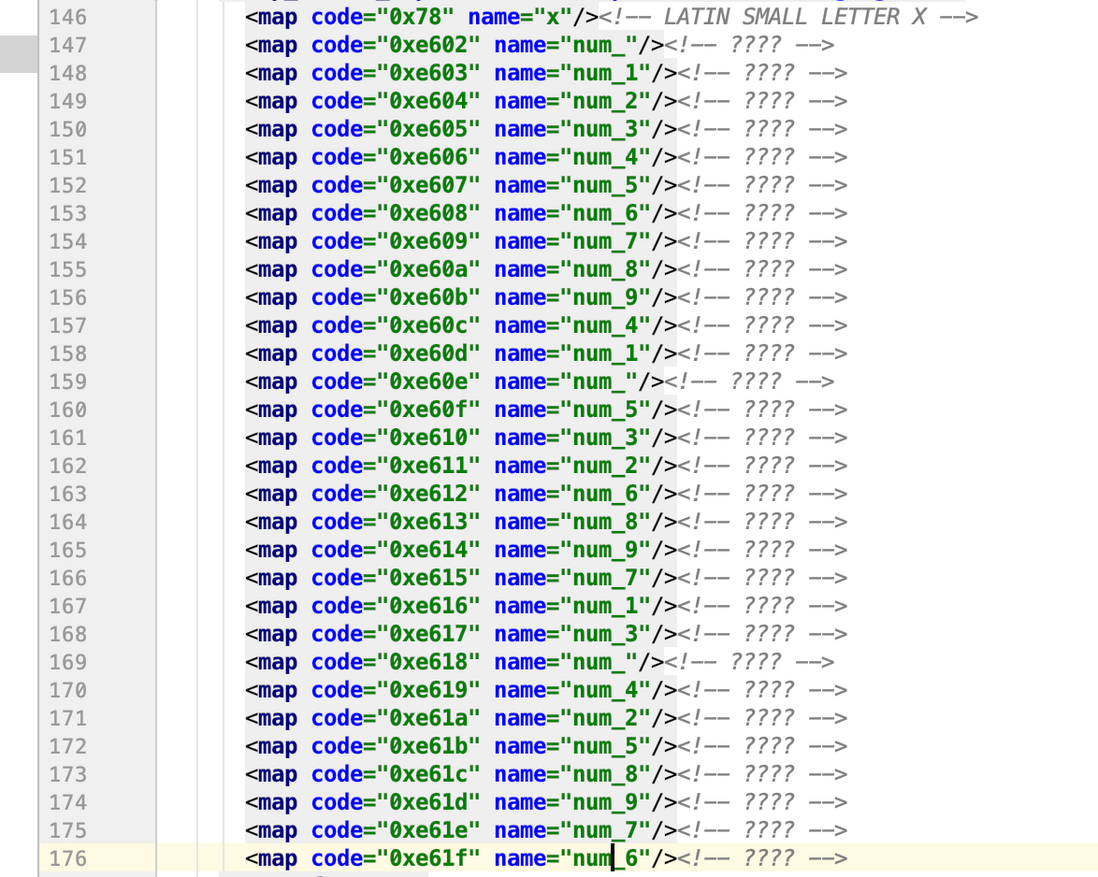
这个就是我们需要找的映射,配合上面在 字体和数字的对应,一起用,这个就破解了。
3. 代码实现字体映射关系
关系映射表
regex_list = [
{'name': ['0xe602', '0xe60e', '0xe618'], 'value': '1'},
{'name': ['0xe603', '0xe60d', '0xe616'], 'value': '0'},
{'name': ['0xe604', '0xe611', '0xe61a'], 'value': '3'},
{'name': ['0xe605', '0xe610', '0xe617'], 'value': '2'},
{'name': ['0xe606', '0xe60c', '0xe619'], 'value': '4'},
{'name': ['0xe607', '0xe60f', '0xe61b'], 'value': '5'},
{'name': ['0xe608', '0xe612', '0xe61f'], 'value': '6'},
{'name': ['0xe609', '0xe615', '0xe61e'], 'value': '9'},
{'name': ['0xe60a', '0xe613', '0xe61c'], 'value': '7'},
{'name': ['0xe60b', '0xe614', '0xe61d'], 'value': '8'} ]4. 完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
import requests
from lxml import etree
start_url = ' https://www.iesdouyin.com/share/user/88445518961'
def get_real_num(content):
content = content.replace(' &#', '0').replace('; ', '')
regex_list = [
{'name': ['0xe602', '0xe60e', '0xe618'], 'value': '1'},
{'name': ['0xe603', '0xe60d', '0xe616'], 'value': '0'},
{'name': ['0xe604', '0xe611', '0xe61a'], 'value': '3'},
{'name': ['0xe605', '0xe610', '0xe617'], 'value': '2'},
{'name': ['0xe606', '0xe60c', '0xe619'], 'value': '4'},
{'name': ['0xe607', '0xe60f', '0xe61b'], 'value': '5'},
{'name': ['0xe608', '0xe612', '0xe61f'], 'value': '6'},
{'name': ['0xe609', '0xe615', '0xe61e'], 'value': '9'},
{'name': ['0xe60a', '0xe613', '0xe61c'], 'value': '7'},
{'name': ['0xe60b', '0xe614', '0xe61d'], 'value': '8'}
]
for i1 in regex_list:
for font_code in i1['name']:
content = re.sub(font_code, str(i1['value']), content)
html = etree.HTML(content)
douyin_info = {}
# 获取抖音ID
douyin_id = ''.join(html.xpath("//div[@class='personal-card']/div[@class='info1']/p[@class='shortid']/text()"))
douyin_id = douyin_id.replace('抖音ID:', '').replace(' ', '')
i_id = ''.join(html.xpath("//div[@class='personal-card']/div[@class='info1']/p[@class='shortid']/i/text()"))
douyin_info['douyin_id'] = str(douyin_id) + str(i_id)
# 关注
douyin_info['follow_count'] = ''.join(html.xpath(
"//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i/text()"))
# 粉丝
fans_value = ''.join(html.xpath(
"//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text()"))
unit = html.xpath(
"//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['fans'] = str(float(fans_value) / 10) + 'w'
fans_count = douyin_info['fans'][:-1]
fans_count = float(fans_count)
fans_count = fans_count * 10000
douyin_info['fans_count'] = fans_count
else:
douyin_info['fans'] = fans_value
douyin_info['fans_count'] = fans_value
# 点赞
like = ''.join(html.xpath(
"//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']//i[@class='icon iconfont follow-num']/text()"))
unit = html.xpath(
"//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['like'] = str(float(like) / 10) + 'w'
like_count = douyin_info['like'][:-1]
like_count = float(like_count)
like_count = like_count * 10000
douyin_info['like_count'] = like_count
else:
douyin_info['like'] = like
douyin_info['like_count'] = like
# 作品
worko_count = ''.join(html.xpath("//div[@class='video-tab']/div/div[1]//i/text()"))
douyin_info['work_count'] = worko_count
return douyin_info
def get_html():
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
response = requests.get(url=start_url, headers=header, verify=False)
return response.text
def run():
content = get_html()
info = get_real_num(content)
print(info)
if __name__ == '__main__':
run()
5. 结果