
在 JuiceFS 开源一周年之际,我们迎来了首个里程碑版本 JuiceFS v1.0.0 Beta1,并将开源许可从 AGPL v3 修改为 Apache License 2.0。
JuiceFS v1.0.0 Beta1 是一个在生产环境中充分验证迭代的产物,在延续 JuiceFS 一贯开放、安全、稳定、可靠的品质之上,进一步提供一系列紧贴用户需求的全新功能。
亮点一:回收站
数据误删这样的情况总是在你我身边一次又一次上演,周期性备份尚且无法根治,我们需要的是让删除操作可以有回旋的余地。
今天,JuiceFS 正式解锁这项对于数据保护来说非常重要的功能——回收站。
从 JuiceFS v1.0.0 Beta1 开始,文件系统默认开启回收站,任何对文件的删除都会先被移动到回收站,可以随时找回误删的文件。
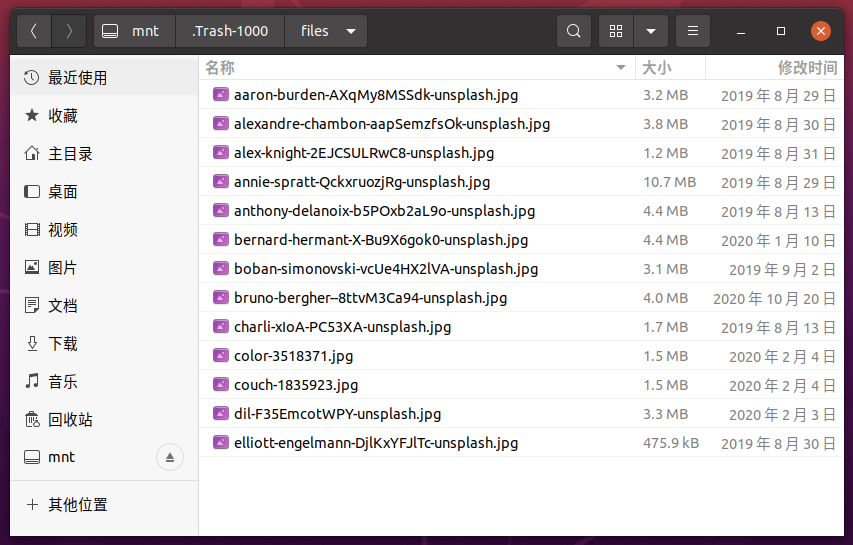
如果你的 JuiceFS 文件系统经常产生删除操作,回收站可能会占据很多的空间(默认保留最近 1 天的删除数据),你可以调整设置让 JuiceFS 定期清理回收站中的文件。
对于新创建的文件系统,可以在 format 命令中指定 --trash-days 选项,比如 --trash-days 3 代表回收站自动清理存放超过 3 天的文件。
对于已经在用的文件系统,可以通过新增的 config 命令调整回收站清理规则,例如:
$ juicefs config "postgres://user:$PG_PASSWD@127.0.0.1:5432/jfs1" --trash-days 3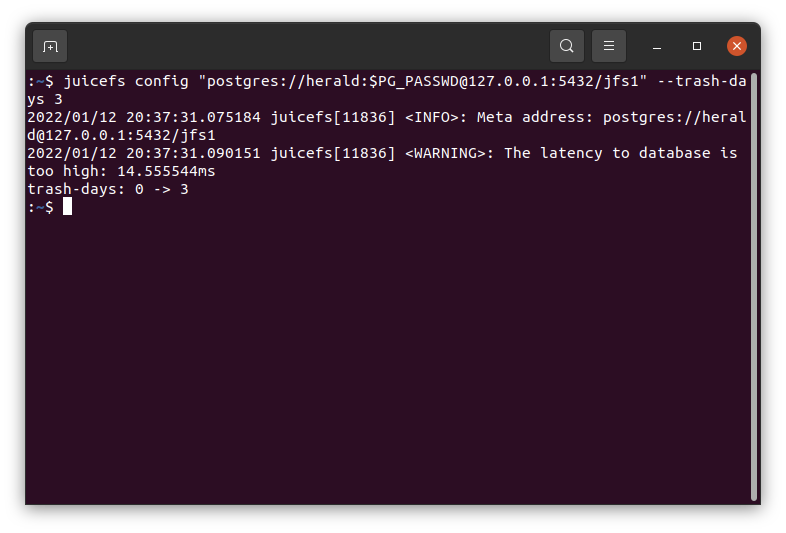
关于回收站的详细介绍,请查看 JuiceFS 官方文档。
亮点二:元数据自动备份
对于数据和元数据分离存储的分布式文件系统,元数据的安全和完整直接决定了整个存储系统的安全和完整。
于我们而言,数据安全绝不是目标,而是始终尽心捍卫的底线。
早在 JuiceFS v0.15.2 我们就增加了备份和恢复元数据的 dump 和 load 命令,让用户可以根据实际需要定期备份元数据,从而在基础的数据库备份层面之上又增加了一重对元数据的安全保障。
今天,我们又增加了一重保障——元数据自动备份。
从 JuiceFS v1.0.0 Beta1 开始,不论文件系统通过 mount 命令挂载,还是通过 JuiceFS S3 网关及 Hadoop Java SDK 访问,每小时都会自动备份元数据并拷贝到对象存储。

备份文件存储在对象存储的 meta 目录中,它是一个独立于数据存储的目录,在挂载点中不可见,也不会与数据存储之间产生影响,用对象存储的文件浏览器即可查看和管理。
默认情况下,JuiceFS 客户端每小时备份一次元数据,自动备份的频率可以在挂载文件系统时通过 mount 命令的 --backup-meta 选项进行调整,比如 --backup-meta 8h 设置每八个小时执行一次自动备份。
虽然自动备份元数据成为了默认动作,但在多主机共享挂载同一个文件系统时也不会发生备份冲突,因为 JuiceFS 维护了一个全局的时间戳,确保同一时刻只有一个客户端执行备份操作。当客户端之间设置了不同的备份周期,那么就会以周期最短的设置为准进行备份。
另外,JuiceFS 会按照以下规则定期清理备份:
- 保留 2 天以内全部的备份;
- 超过 2 天不足 2 周的,保留每天中的 1 个备份;
- 超过 2 周不足 2 月的,保留每周中的 1 个备份;
- 超过 2 个月的,保留每个月中的 1 个备份。
亮点三:新增 config 命令调整文件系统配置
由于元信息全部存储在数据库中,在过去,JuiceFS 文件系统一旦创建,若需要调整文件系统的配置要使用 format 命令进行修改,还需要带上之前格式化文件系统时的那些参数。再就是直接操作数据库,在相应的数据表中小心翼翼的修改,操作不当还有可能损坏数据库。毫无疑问,过去的几种修改方式既麻烦,又存在一定风险。
为了解决这个问题,JuiceFS v1.0.0 Beta1 新增加了 config 命令,让你可以通过客户端就能修改文件系统的基本信息。

本次更新的 config 命令支持修改文件系统的容量配额、inodes 配额、对象存储及密钥、回收站清理规则。
亮点四:新增 destroy 命令销毁文件系统
在之前,如果决定停用一个 JuiceFS 文件系统,需要分别操作对象存储和数据库清理数据,如果数据量特别大时会十分耗费精力。
为此,JuiceFS v1.0.0 Beta1 特别新增了 destroy 命令,只需一条命令即可完成文件系统的销毁。

如上图,销毁操作除了要指定元数据存储的 URL 之外,还需要指定文件系统的 UUID,这可以在一定程度上避免误操作。
注意:销毁文件系统是一项高风险操作,请务必谨慎使用!
更多功能
除了上述几项功能之外,JuiceFS v1.0.0 Beta1 还增加了以下新功能:
- 新增
--max-deletes选项,控制并行删除文件的线程数; - 新增
--consul选项,将监控指标 API 注册到 Consul 中; - 新增
--keep-etag选项,保留上传到 S3 网关的对象的 ETag; - 新增
--check-all和--check-new选项,允许通过sync命令同步数据时校验数据的完整性; - sync 命令支持同步匿名访问的对象存储的数据
有关 JuiceFS 新版的更多内容,欢迎了解详情。













