
01 kafka入门
1.1 什么是kafka
1.2 kafka中的基本概念
1.2.1 消息和批次
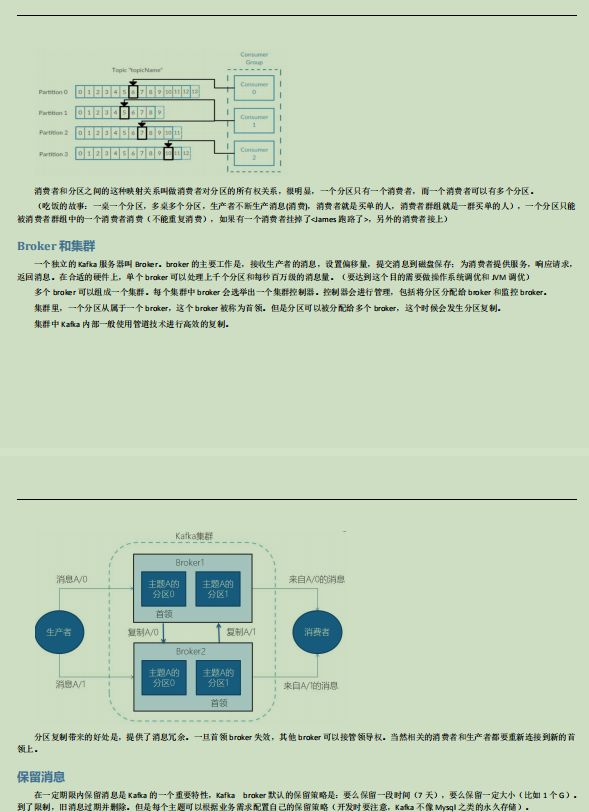
1.2.2 主题和分区
1.2.3 生产者和消费者、偏移量、消费者群组
1.2.4 Broker和集群
1.2.5 保留消息

02 为什么选择kafka
2.1 优点
2.2 常见场景
2.2.1 活动跟踪
2.2.2 传递消息
2.2.3 收集指标和日志
2.2.4 提交日志
2.2.5 流处理

03 kafka的安装、管理和配置
3.1 安装
3.1.1 预备环境
3.1.2 下载和安装kafka
3.1.3 运行
3.1.4 kafka基本的操作和管理
3.2 Broker配置
3.3 硬件配置对kafka性能的影响
3.3.1 磁盘吞吐量/磁盘容量
3.3.2 内存
3.3.3 网络
3.3.4 CPU
3.3.5 总结


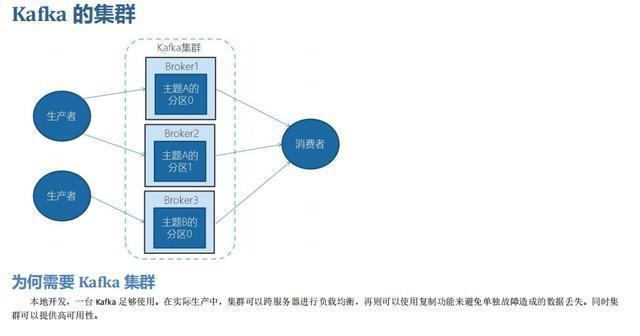
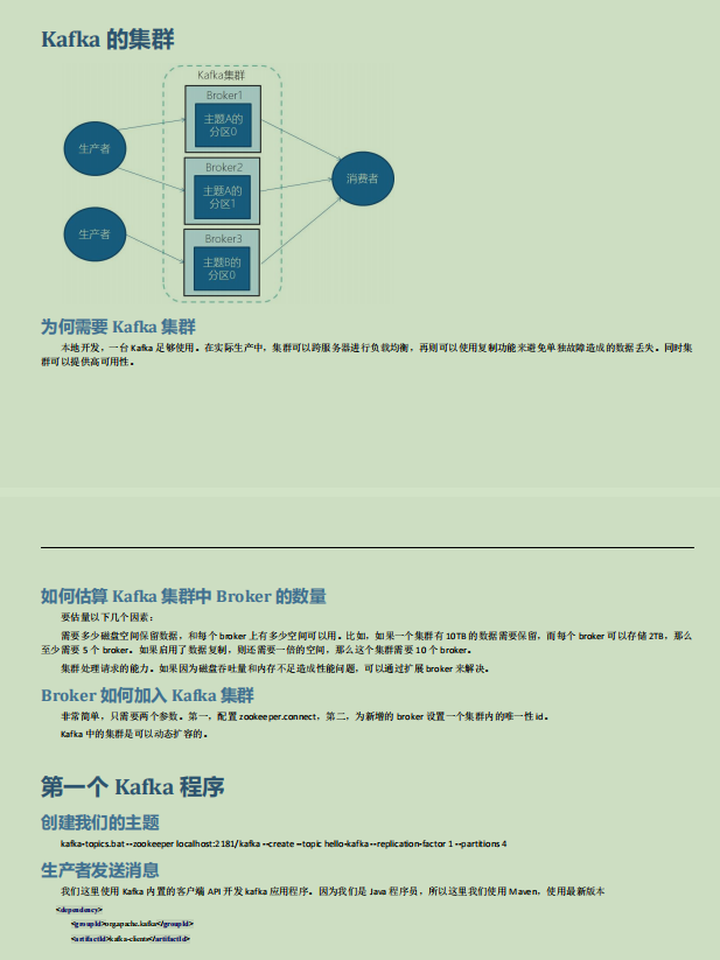
04 kafka的集群
4.1 为何需要kafka集群
4.2 如何估算kafka集群中Broker的数量
4.3 Broker如何加入kafka集群
05 第一个kafka程序
5.1 创建我们的主题
5.2 生产者发送消息
5.2.1 必选属性(bootstrap.servers、key.serializer、value.serializer)
5.3 消费者接受消息
5.3.1 必选参数(group.id)
5.4 演示示例
06 kafka的生产者
6.1 生产者发送消息的基本流程
6.2 使用kafka生产者
6.2.1 三种发送方式(发送并忘记、同步发送、异步发送)
6.2.2 多线程下的生产者
6.2.3 更多发送配置(acks、buffer.mempry、max.block.ms、retries、batch.size、linger.ms、compression.type、client.id、、、顺序保证)
6.3 序列化
6.3.1 自定义序列化需要考虑的问题
6.4 分区
6.4.1 自定义分区器

07 kafka的消费者
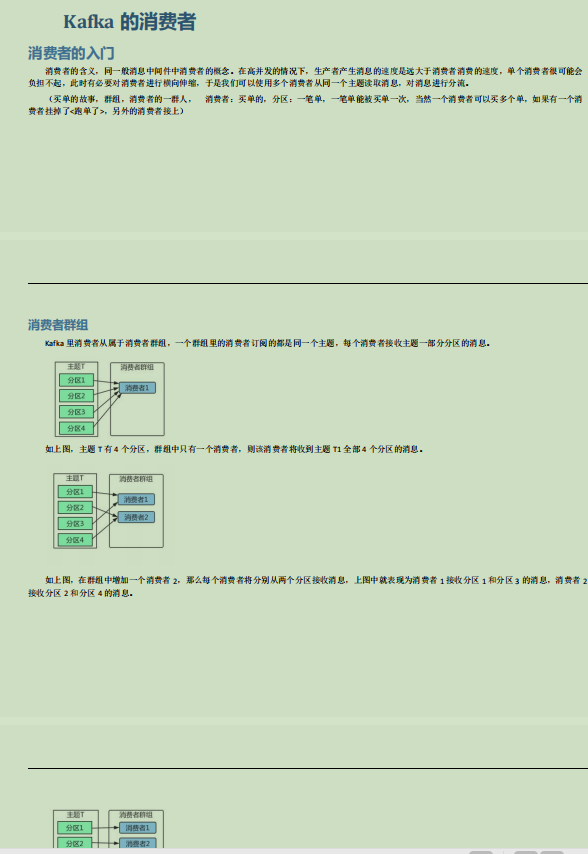
7.1 消费者的入门
7.1.1 消费者群组
7.1.2 消费者配置
7.2 消费者中的基础概念
7.2.1 消费者群组
7.2.2 订阅
7.2.3 轮询
7.2.4 提交和偏移量
7.3 消费者中的核心概念
7.4 kafka中的消费安全
7.5 消费者提交偏移量导致的问题
7.5.1 自动提交
7.5.2 手动提交(同步)
7.5.3 异步提交
7.5.4 同步和异步组合
7.5.5 特定提交
7.6 分区再均衡
7.7 优雅1退出
7.8 反序列化
7.9 独立消费者

08 深入理解kafka
8.1 集群的成员关系
8.2 什么是控制器
8.3 复制-kafka的核心
8.3.1 replication-factor
8.3.2 副本类型
8.3.3 工作机制
8.4 处理请求的内部机制
8.4.1 生产请求
8.4.2 获取请求
8.4.3 ISR
8.5 物理存储机制
8.5.1 分区分配
8.5.2 文件管理
8.5.3 文件格式
8.5.4 索引
8.5.5 超时数据的清理机制


09 可靠的数据传递
9.1 kafka提供的可靠性保证和架构上的权衡
9.2 复制
9.3 Broker配置对可靠性的影响
9.3.1 复制系数
9.3.2 不完全的首领选举
9.3.3 最少同步副本
9.4 可靠系统里的生产者
9.4.1 发送确认
9.4.2 配置生产者的重试参数
9.4.3 额外的错误处理
9.5 可靠系统里的消费者
9.5.1 消费者的可靠性配置
9.5.2 显式提交偏移量

10 kafka和Spring的整合
10.1 与Spring集成
10.1.1 pom文件
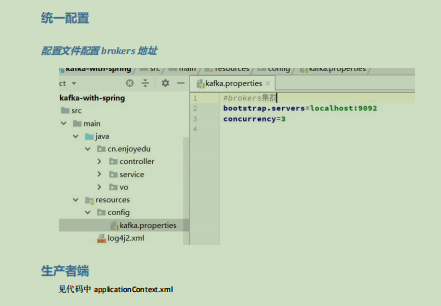
10.1.2 统一配置
10.1.3 生产者端
10.1.4 消费者端
11 SpringBoot和kafka的整合

12 kafka实战之削峰填谷
13 数据管道和流式处理(了解即可)
13.1 数据管道基本概念
13.2 流式处理基本概念

最后
在面试前我整理归纳了一些面试学习资料,文中结合我的朋友同学面试美团滴滴这类大厂的资料及案例
感兴趣的朋友可以点击Java学习免费获取。
 由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
大家看完有什么不懂的可以在下方留言讨论也可以关注。
觉得文章对你有帮助的话记得关注我点个赞支持一下!












