
作者: Kafka&Tablestore
本文章主要介绍消息队列使用过程中所遇到的消息丢失、重复消费等痛点问题的排查办法,以及消息队列 Kafka「检索组件」的场景实践,并对其关键技术进行解读。旨在帮助大家对消息队列 Kafka「检索组件」的特点和使用方式更加熟悉,以更有效地解决消息排查过程中所遇到的问题。
场景痛点介绍
在消息队列的使用过程中,由于其分布式特性难免会遇到消息丢失、消息重传等问题。
- 例如在日志聚合场景中,通常是多个异构数据源生产数据到 Kafka 中以提供给下游的 Spark 等计算引擎消费。而当某些日志缺失时,由于消息数据的发送方式、数据结构等种类繁杂,导致难以直接从客户端的日志来排查。
- 再例如消息转发的过程中,消费端可能会重复消费到同样的数据,这就需要根据内容从消息队列中检索数据以判断消息是否重复生产,而消息队列通常只能按照分区和消费位点遍历扫描,并不能灵活的实现消息检索。
业内现有的消息队列产品都没有较好的工具和方式来实现对消息内容的检索,这将使得排查难度和投入成本大大增加。
Kafka 消息检索组件
检索组件介绍
消息队列 Kafka 「检索组件」是一个全托管、高弹性、交互式的检索组件,具备万亿级消息内容检索的秒级响应能力,旨在解决业内消息产品不支持检索消息内容的难题。消息队列 Kafka 「检索组件」是通过 Kafka Connector 将 Topic 中的消息数据转存到表格存储(Tablestore)中,基于表格存储的多元索引功能提供消息检索能力。能够支持通过消息的分区、位点、发送的时间范围等一个或多个条件组合检索,还支持根据消息 Key、Value 全文检索消息。
案例实践
案例背景
假设某运维团队需要监控线上集群的运行情况,采集进程级别的日志导入到 Kafka 中,下游使用 Flink 消费,实时计算各进程资源消耗情况。当在 Flink 中发现某个进程的某个时间段的日志数据丢失时,需要使用消息队列 Kafka 「检索组件」,基于消息 Value 和时间范围检索消息数据,判断日志是否已经成功推送到了消息队列 Kafka 中。
例如采集的日志数据为 JSON 结构,某一条日志数据格式为:
key = 276
value = {"PID":"276","COMMAND":"Google Chrom","CPU_USE":"7.2","TIME":"00:01:44","MEM":"8836K","STATE":"sleeping","UID":"0","IP":"164.29.0.1"}开通消息检索
- 首先需要登录到阿里云消息队列 Kafka 控制台中,选择对应的 topic,开通消息检索服务。
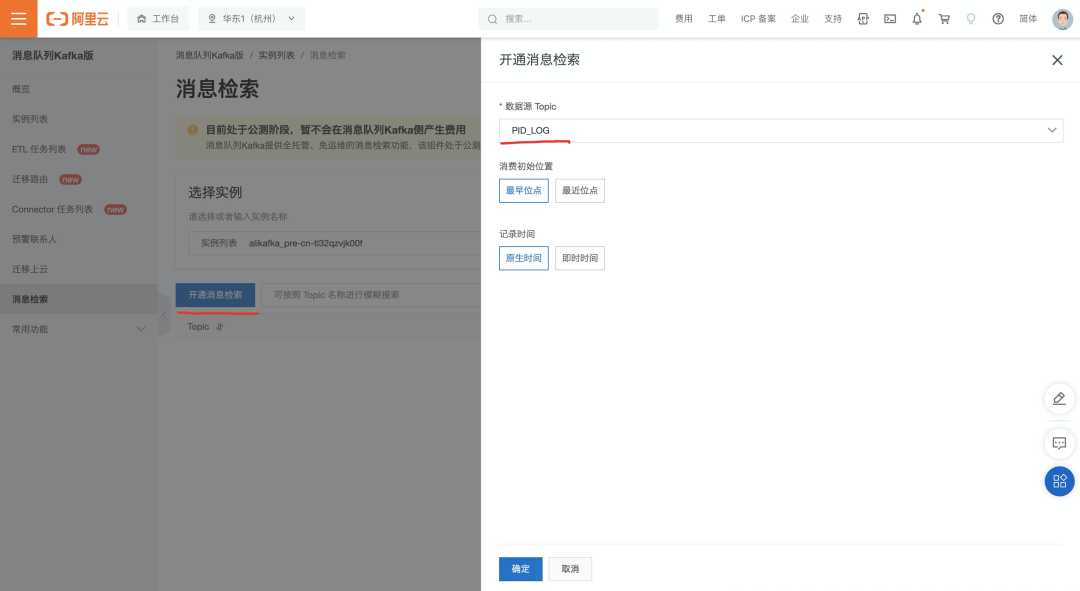
- 消息检索服务开通后,将自动创建一个 Tablestore 实例,之后将消息数据转存到 Tablestore,并创建索引提供消息检索能力。每一个 topic 对应了 Tablestore 中的一张数据表。可以在消息队列 Kafka 控制台上查看每个 topic 的消息检索组件详情。

消息检索实践
- 消息检索服务开通后,就可以使用消息中的多个搜索项检索消息,实现上述案例。例如指定一个时间范围,并且检索消息 Value 中包含 PID = 276 的消息。
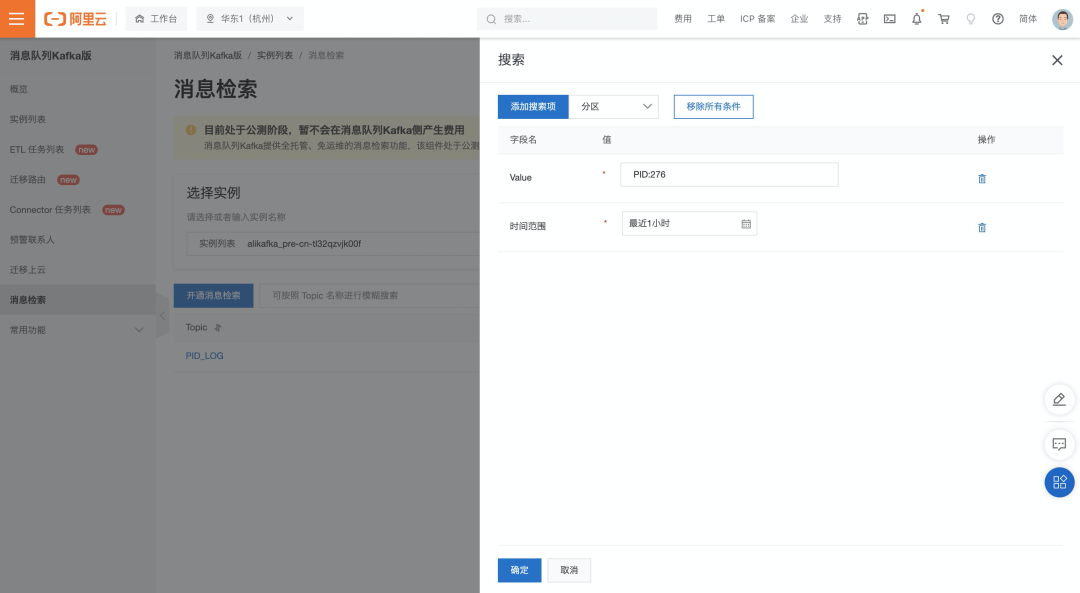
- 返回结果示例

能力扩展
表格存储 Tablestore 介绍
表格存储 Tablestore 是基于底层飞天平台构建的结构化数据存储,能够提供千亿级规模数据存储、毫秒级数据检索的服务能力。消息队列 Kafka 转存消息到 Tablestore 后,支持通过 Tablestore 原生的数据访问方式来检索消息,Tablestore 支持更复杂的检索逻辑,同时支持通过 SQL 语法检索消息。下面列举两种消息检索方式:
多元索引搜索
- 登录到表格存储 Tablestore 控制台中,进入 Kafka 消息数据转存对应的 Tablestore 实例和数据表中,在索引管理页面选择多元索引搜索消息。
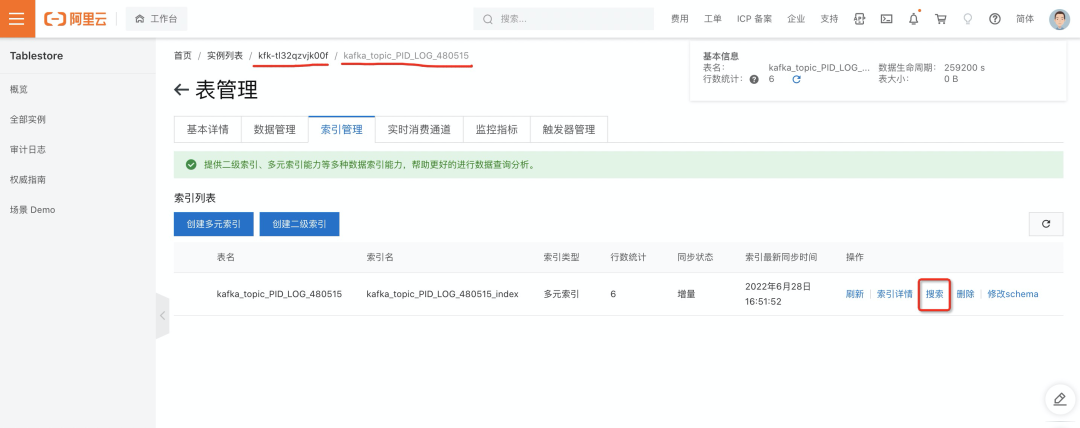
- 例如需要检索消息 Value 中包含 PID=276 或者 PID=277 的消息。

- 返回结果

SQL 检索消息
- 表格存储 Tablestore 支持基于 SQL 语法来检索消息,首先需要在消息转存的数据表上创建一张 SQL 映射表。
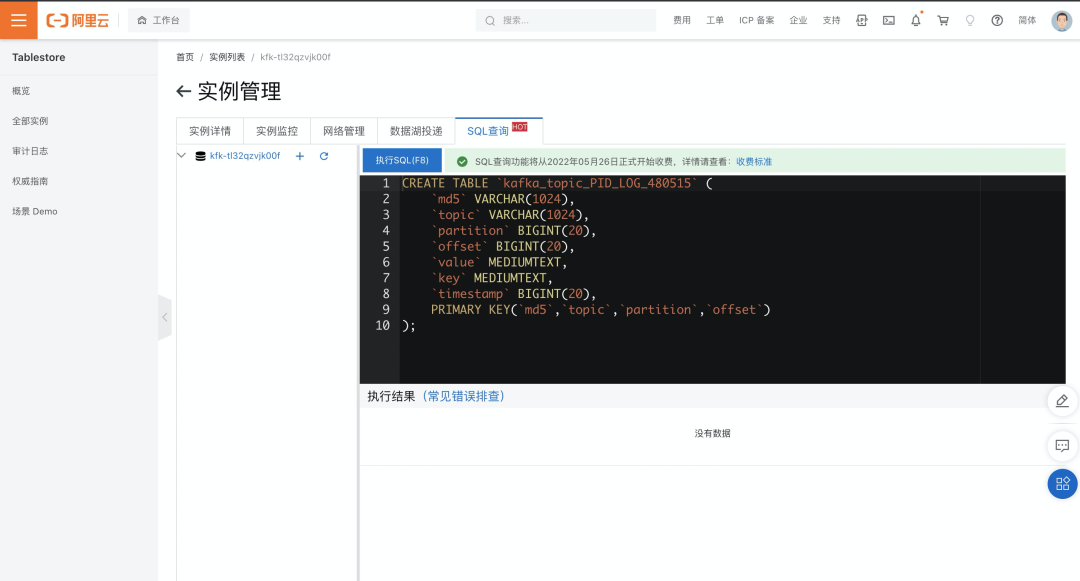
- 基于 Tablestore SQL 检索 PID=276 的消息。

总结
阿里云消息队列 Kafka 「检索组件」是消息队列领域率先支持交互式消息内容检索的组件,基于数据转存表格存储 Tablestore 提供消息检索服务能力,支持根据 Key、Value、分区等任意个条件自由组合检索消息,同时支持 Key、Value 全文检索消息,具备免开发、免运维、高弹性的特点。同时也可以直接通过表格存储 Tablestore 索引或者 SQL 来检索消息,极大地提高了日常排查消息存在或正确性的速度。
对于本文中 Tablestore 的多元索引和 SQL 查询使用的部分有任何问题,欢迎加入技术交流群,群内提供免费的在线专家服务。欢迎扫码加入或搜索群号 23307953。

点击此处,欢迎开通试用消息队列 Kafka「检索组件」~








