
Forecasting is ubiquitous
如何利用预测来构建更好的产品和服务
定量预测方法可分为:基于模型(model-based)或因果关系,统计方法(statistical methods)和机器学习方法(machine learning approaches)
Forecasting at Uber: An Introduction | September 6, 2018 | By Franziska Bell, Slawek Smyl
近年来,机器学习,深度学习和概率编程在精准预测方面显示出巨大潜力。除普通的统计算法外,Uber 还使用这三种技术构建预测解决方案。下面将讨论 Uber 预测系统使用的关键组件,流行方法,回溯测试和预测区间。
预测无处不在。除了战略预测之外(例如预测收入,生产和支出),产业界还需要能够针对短期战术行为作出准确预测(例如订货数量和招聘需求),以跟上企业的成长步伐。Uber 常见的预测场景包括:
市场预测(Marketplace forecasting):作为 Uber 平台的一个关键要素,市场预测能够基于精准时间和空间的方式预测用户供需,以便引导驾驶员在高峰出现之前到达高需求区域,从而增加运输次数和收入。时空预测(Spatio-temporal forecasts)仍然是一个开放的研究领域。
硬件容量规划(Hardware capacity planning):硬件供应不足可能导致服务中断、损害用户信任度,但是过度配置又会增加运营成本。预测可以帮助找到最佳点:不太多也不太少。
市场营销(Marketing):了解不同媒体渠道的边际效果至关重要,需要兼顾趋势、季节性和其他动态因素(例如竞争或定价),同时,利用先进的预测方法构建更可靠的估价,并使大规模地制定基于数据驱动的营销决策成为可能。
Challenge
Uber 平台在真实的物理世界运行,现实中的参与者的行为和兴趣各不相同,运行模式本身存在物理约束和不可预测性。物理约束,如地理距离和道路吞吐量,预测行为需要从时间域(temporal domain)转移到时空域(spatio-temporal domain)。尽管 Uber 是一家相对年轻的公司(已有8年历史),确保预测模型与高速成长的运营速度和规模保持同步至关重要。
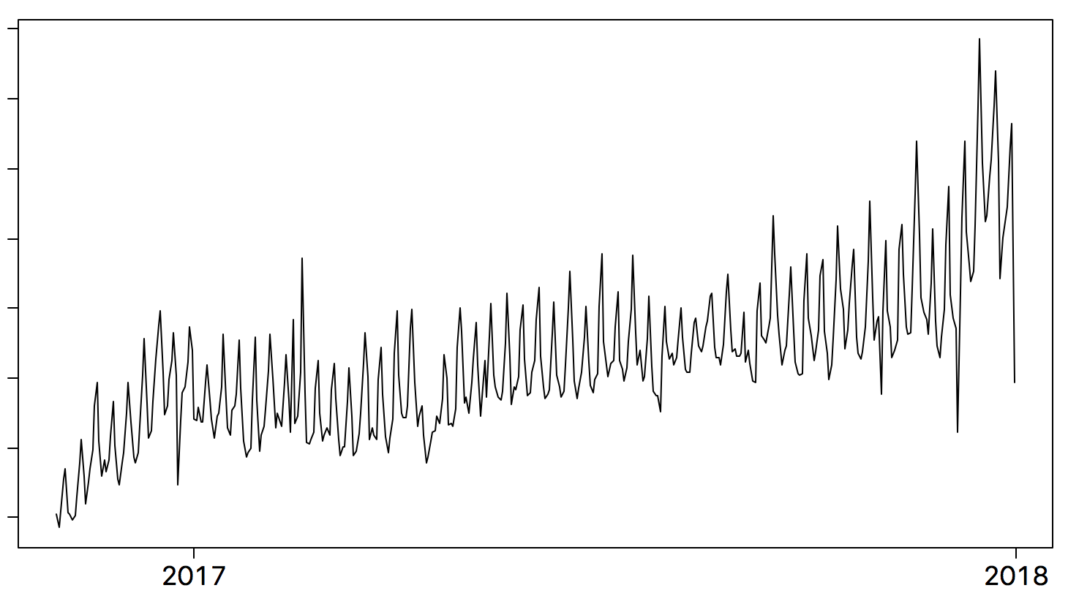
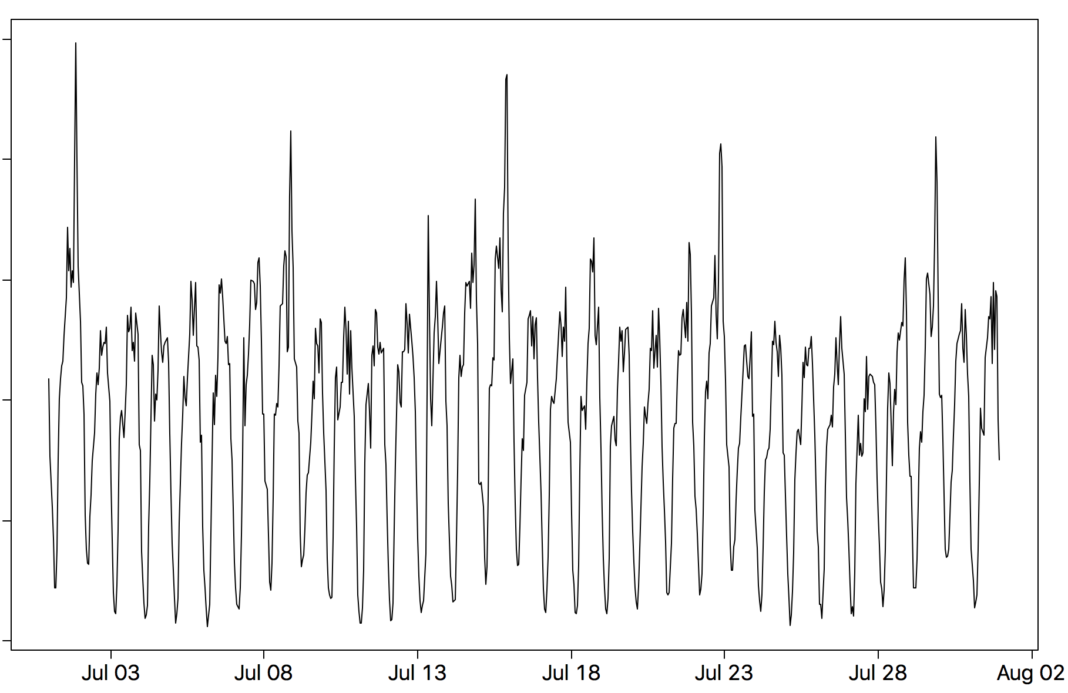
下面的图2 提供了一个超过14个月的城市旅行数据示例。你可以注意到很多变化,同时可以看到一个增长的趋势和季节性周期(例如,12 月通常有更多的高峰日期,因为整个月份散布着很多主要假期)。如果我们将图形放大(图3)并切换到2017年7月的每小时数据,您会注意到每日和每周(7* 24)的季节性。你可能会注意到周末往往比平时更加繁忙。
预测方法需要能够针对上述复杂模式进行建模。
Prominent forecasting approaches
除定性方法外,定量预测方法可分为以下几类:基于模型(model-based)或因果关系,统计方法(statistical methods)和机器学习方法(machine learning approaches)。
当问题的基础机制或物理原理是已知时,基于模型的预测方法效果最好,因此基于模型的方法应用于许多科学和工程环境中。基于模型也是计量经济学中的常用方法,模型遵循的理论基础不尽相同。
当基础机制未知或过于复杂时,例如股票市场,或者不完全已知,例如零售,通常应用简单的统计模型。属于这一类的流行经典方法包括 ARIMA(Autoregressive Integrated Moving Average,自回归求和移动平均模式),指数平滑方法,如 Holt-Winters ,以及Theta方法,它使用较少,但表现非常好。Theta 方法赢得了 M3 预测竞赛(M3 Forecasting Competition),我们也发现它在 Uber的时间序列上运行良好(此外,它的计算成本也很廉价)。
近年来,机器学习方法,包括分位数回归森林算法(quantile regression forests ,QRF),著名的随机森林算法的表兄弟,已成为预测工具包的一部分。如果有足够的数据,特别是外源性回归量,递归神经网络算法(Recurrent neural networks ,RNN)也被证明是非常有用的。通常,这些机器学习算法是黑盒模型,并且在不需要可解释性时使用。流行经典和机器学习预测方法概要:
Classical & Statistical
Machine Learning
Autoregressive integrated moving average (ARIMA) Exponential smoothing methods (e.g. Holt-Winters) Theta
Recurrent neural networks (RNN) Quantile regression forest (QRF) Gradient boosting trees (GBM) Support vector regression (SVR) Gaussian Process regression (GP)
有趣的是,M4 预测竞赛(M4 Forecasting Competition)的获奖作品是一个混合模型 ES-RNN,Exponential Smoothing-Recurrent Neural Networks,其中包括手工编码平滑公式(灵感来自众所周知的 Holt-Winters 方法)和一堆扩展的长短期记忆单元( long short-term memory units ,LSTM,一种时间递归神经网络)。
实际上,经典预测方法和机器学习方法彼此之间并没有区别,不过是通过模型是否更简单、可解释或更复杂和灵活来区分。在实践中,经典统计算法往往更快更容易使用。
在 Uber 为特定场景用例选择的预测方法实际一个包含许多参数的函数,包括可用的历史数据量、外生变量(例如,天气,音乐会等)是否发挥重要作用,以及业务需求(例如,模型是否需要可解释?)。然而,最重要的是,我们无法确定哪种方法会产生最佳性能,因此有必要比较多种方法的模型性能。
Comparing forecasting methods
对于时间序列而言排序很重要,因此必须按时间顺序进行测试。实验者不能在中间切出一块,并在此部分之前和之后训练数据。相反,需要训练一组比测试数据更早的数据。
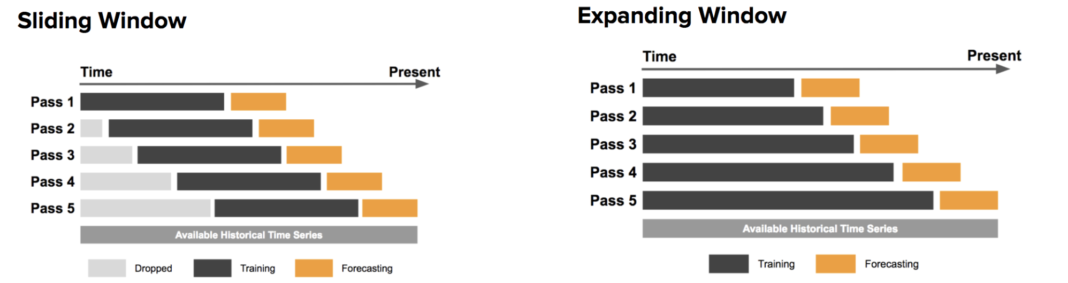
考虑到这一点,上面图4 中概述了两种主要方法:滑动窗口方法(the sliding window approach)和扩展窗口方法(the expanding window approach)。在滑动窗口方法中,使用固定大小的窗口(此处以黑色显示)进行训练。随后,针对橙色显示的数据测试该方法。
另一方面,扩展窗口方法使用越来越多的训练数据,同时保持测试窗口大小固定。如果要处理的数据量有限,后一种方法特别有效。将这两种方法结合起来也是可能的,而且通常最理想:从扩展窗口方法开始,当窗口变得足够大时,切换到滑动窗口方法。
在这个领域已经提出了许多评估指标,包括绝对误差( absolute errors )和百分比误差(percentage errors),这些指标有一些缺点。一种特别有用的方法是将模型性能与天真预测法(naive forecast)进行比较。在非季节性的情况下,天真预测法假设最后一个值等于下一个值。对于周期性时间序列,预测估计值等于先前的季节值(例如,对于具有每周周期性的每小时时间序列,天真预测法假设下一个值是一周前的当前小时的值)。
为了更容易地选择正确的预测方法,Uber 预测平台团队构建了一个名为 Omphalos 的回溯测试框架,该框架支持并行并且语言可扩展,以支持快速迭代和预测方法比较。
The importance of uncertainty estimation
确定给定用例的最佳预测方法只是等式的一半。我们还需要估计预测区间。预测区间是预测值的上限和下限,预期实际值在某些(通常是高的)概率之间,例如, 0.9。图5 显示预测区间的工作原理:
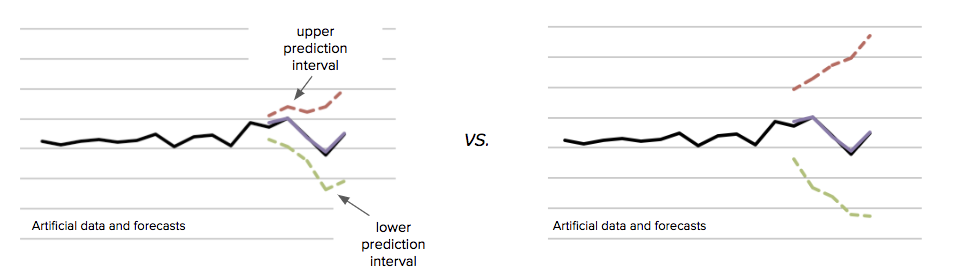
在图5中,紫色的点表示预测完全相同。但是,左图中的预测区间比右图中的预测区间窄得多。预测区间的差异导致两种截然不同的预测结果,特别是考虑容量规划的背景下:第二次预测需要更高的容量储备以允许需求大幅增加的可能性。
预测区间与预测点本身一样重要,应始终包含在预测中。预测区间通常取决于我们拥有多少数据,此数据中有多少变化,我们预测的偏差以及使用的预测方法。
Next
在后续的文章中将深入研究技术细节。本系列的下一篇文章将专门用于讨论数据预处理。
扩展阅读:《The Machine Learning Master》

- Machine Learning(一):基于 TensorFlow 实现宠物血统智能识别
- Machine Learning(二):宠物智能识别之 Using OpenCV with Node.js
- Machine Learning:机器学习项目
- Machine Learning:机器学习算法
- Machine Learning:如何选择机器学习算法
- Machine Learning:神经网络基础
- Machine Learning:机器学习书单
- Machine Learning:人工智能媒体报道集
- Machine Learning:机器学习技术与知识产权法
- Machine Learning:经济学家谈人工智能
- 数据可视化(三)基于 Graphviz 实现程序化绘图
- Uber 业务预测系统实践
更多精彩内容扫码关注:RiboseYim's Blog 











