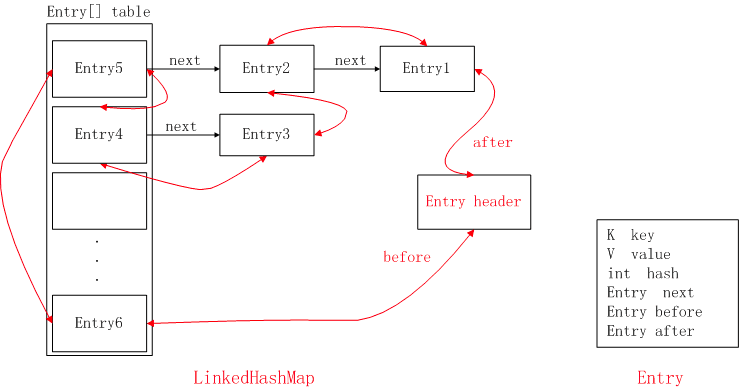
最近在看Vue的源码,不得不说的是,Vue的源码十分优雅简洁,下面就来分享下Vue的缓存利用的算法LRU算法。
LRU算法
LRU是Least recently used的简写,主要原理是根据历史访问记录来淘汰数据,说白了就是这个算法认为如果数据被访问过,那么将来被访问的几率也高。其存储结构是一个双链表,最近被访问到的放在双链表的尾部,头部放的就是最早被访问到数据。关于算法的具体流程,可以来看下这个,这个可视化过程,模拟了lru算法进行调度的过程。
缺页数
lru在笔试题中也会经常出现,经常会考到的那就是缺页数,例如页面访问序列为:2,3,2,1,5,2,4,5,3,2,5,2, 分配给某个进程3页内存,求其缺页次数。
缺页数可以理解为,内存不满的次数,转到lru来看就是链表中有空节点的次数。下面来走一下整个流程(左为head右为tail):
2 // 第一次缺页
2 -> 3 // 第二次缺页
3 -> 2 // 第三次缺页
3 -> 2 -> 1
2 -> 1 // 第四次缺页
2 -> 1 -> 5
1 -> 5 -> 2
5 -> 2 // 第五次缺页
5 -> 2 -> 4
2 -> 4 -> 5
4 -> 5 // 第六次缺页
4 -> 5 -> 3
5 -> 3 // 第七次缺页
5 -> 3 -> 2
3 -> 2 -> 5
3 -> 5 -> 2
所以总共有着7次缺页,上面的这个流程也是算法的具体执行流程,可以看出的是当有新的节点进入时,首先会检测内存是否已满,如果满了的话,就先将头给移除,再在尾部添加上这个新节点;假若该节点在链表中存在,那么直接将这个节点拿到头部。下面来看下Vue对这个算法的实现:
vue中的lru
源码时src/cache.js,先来看看其构造函数:
// limit是最大容量
function Cache (limit) {
this.size = 0;
this.limit = limit;
this.head = this.tail = undefined;
this._keymap = Object.create(null);
}尤大利用集合_keymap来存储已有的节点,在判断是否存在时,直接读取属性就行,不用在遍历一遍链表,这样降低了在查找过程中的时间复杂度。head代表着头节点,tail代表着尾节点,链表中的节点是这样的:
node {
value: 键值,
key: 键名,
older: 指向前一个节点,head的older指向undefined,
newer: 指向下一个节点,tail的newer指向undefined
}来看get方法:
Cache.prototype.get = function (key, returnEntry) {
var entry = this._keymap[key];
// 本身没有,则不用调度,直接将新的节点插入到尾部即可
if (entry === undefined) return;
// 访问的就是尾部节点,则不需要调度
if (entry === this.tail) {
return returnEntry ? entry : entry.value;
}
// 访问的不是尾部节点,需要将被访问节点拿到头部
if (entry.newer) {
if (entry === this.head) {
this.head = entry.newer;
}
entry.newer.older = entry.older;
}
if (entry.older) {
entry.older.newer = entry.newer;
}
entry.newer = undefined;
entry.older = this.tail;
if (this.tail) {
this.tail.newer = entry;
}
this.tail = entry;
return returnEntry ? entry : entry.value;
};get是为了得到链表中是否含有这个节点,假如有这个节点,那么还要对这个节点进行调度,也就是将节点拿到尾部。
// 将链表的头给去除
Cache.prototype.shift = function () {
var entry = this.head;
if (entry) {
this.head = this.head.newer;
this.head.older = undefined;
entry.newer = entry.older = undefined;
this._keymap[entry.key] = undefined;
this.size--;
}
return entry;
};
p.put = function (key, value) {
var removed;
var entry = this.get(key, true);
// 插入的情况,插入到尾部
if (!entry) {
// 如果集合已经满了,移除一个,并将其return
if (this.size === this.limit) {
removed = this.shift();
}
entry = {
key: key
};
this._keymap[key] = entry;
if (this.tail) {
this.tail.newer = entry;
entry.older = this.tail;
} else { // 链表中插入第一个节点时,头节点就是尾几点
this.head = entry;
}
this.tail = entry; // 节点会添加或者拿到尾部
this.size++;
}
// 更新节点的value,假若本身链表中有,get方法中已经调度好,只要更新值就好
entry.value = value;
return removed;
};至此,vue的cache代码已经全部解析完,其具体的作用由于源码刚刚开始读吗,目前还不清楚,不过应该在解析指令等方面有着重大的作用。
最后希望大家关注下算法演示