一、前言
假设当前Flink应用已实现EOS(即 Exactly-Once Semantics)语义,现在需要增加Flink处理数据持久化到MySQL,前提条件不能打破Flink EOS的生态。官方提供的flink-connector-jdbc并没有提供事务和checkpoint的相关操作,自定义sink需要考虑和CheckPoint复杂的配合。参考Flink EOS如何防止外部系统乱入,可自定义实现TwoPhaseCommitSinkFunction类,完成MySQL外部系统组件的完美嵌入。
本次模拟Flink消费Kafka数据并写入MySQL,通过自定义MySQL Sink验证Flink 2PC以及EOS的准确性。相应的系统及组件版本如下,Flink的部署方式为Standalone。
| 组件/系统 | 版本 |
|---|---|
| centOS | 7.5 |
| Flink | 1.12.2 |
| MySQL | 5.7 |
| Kafka | 2.3.1 |
| Zookeeper | 3.4.5 |
| Hadoop | 2.6.0 |
二、验证
思路及猜测结果:
kafka发送:一共发送20条数据,每条数据末尾数字自增,方便观察效果。每条发送间隔为10秒,一共耗时200s。
flink处理:checkpoint时间价格为60s,重启延迟为10s,处理第10条数据的时候模拟发生bug,处理完第19条数据的时候,手动取消job,利用checkpoint恢复job。
猜测1:发生bug时,处理过的数据但未做checkpoint不能持久化到MySQL,只有做了checkpoint的数据才能持久化到MySQL。即checkpioint的提交和MySQL事务的最终提交是保持一致的。
猜测2:job重启会进行事务回滚,重新执行写入事务操作。
猜测3:job失败,利用checkpoint恢复job能保证数据恰好处理一次的精确语义。
验证猜测1:

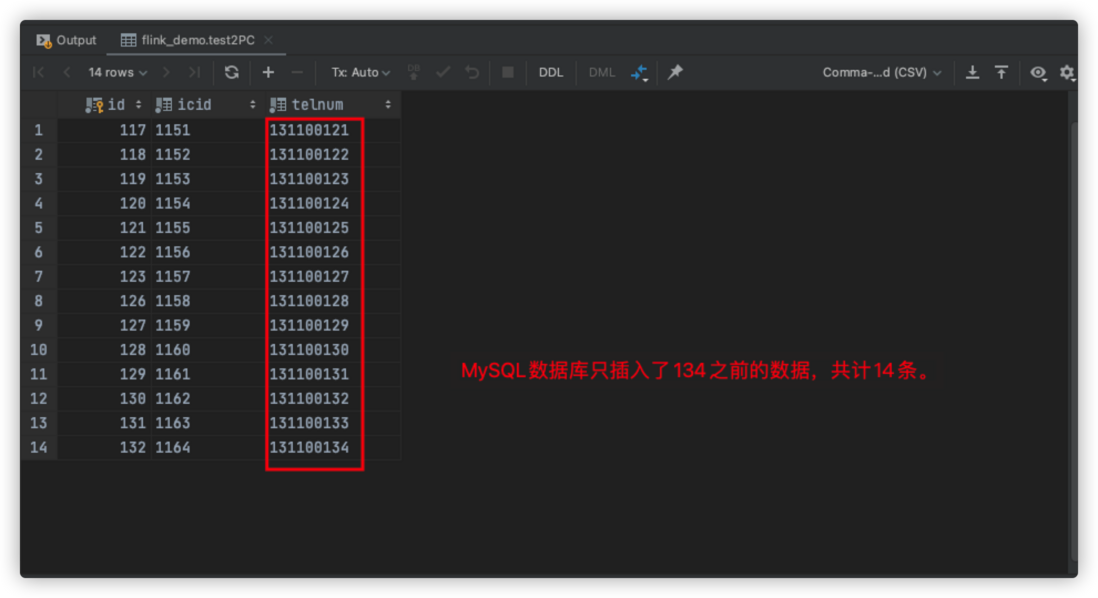
通过截图日志以及两图对比可知,checkPoint完成后回调了MySQL的commit操作,且尾数134之前的数据全部写入MySQL(即最后一次checkpoint之前的数据全部持久化成功),说明MySQL的事务是和checkpoint保持一致的。
验证猜测2:

通过对比job重启前后的日志对比,发现135-137数据发生了事务回滚,并重新进行的写入操作。
验证猜测3:
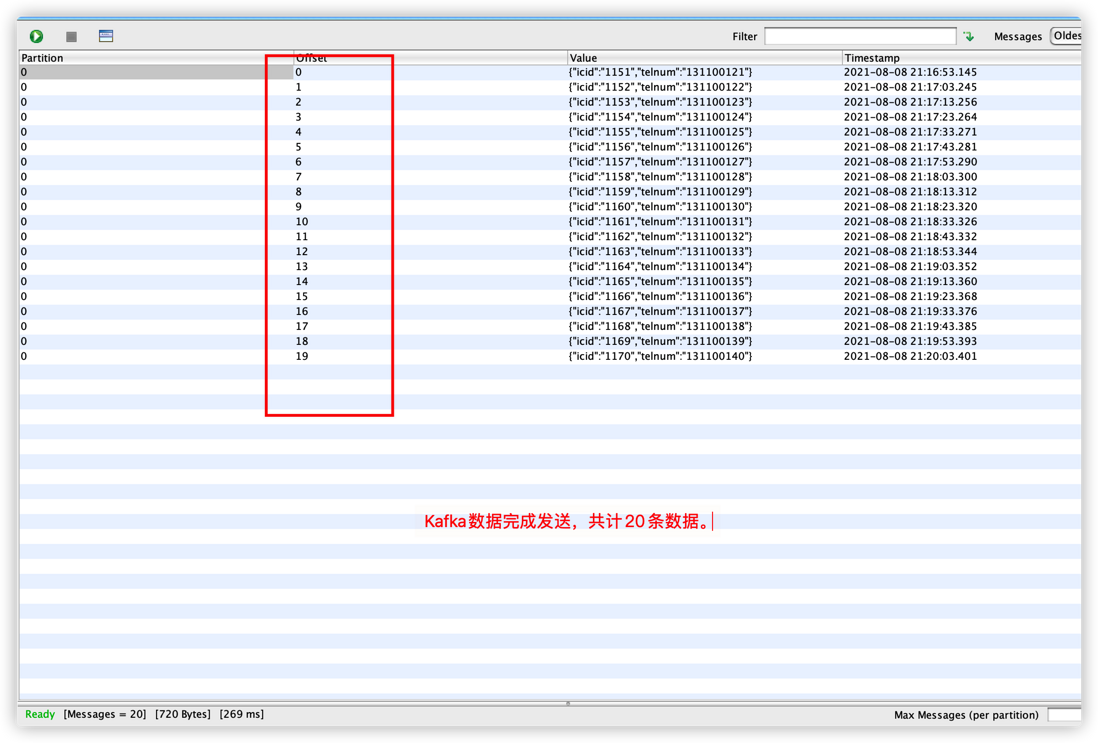
job未手动重启之前,可以看到kafka producer实际发送的数据和持久化MySQL的数据是不一致的,接下来就是验证,利用Flink的checkpoint恢复作业最终能达到精确一次消费的语义。

找到最后一次checkpoint的路径,执行以下命令进行job恢复
bin/flink run -s hdfs://lsl001:8020/checkpoint/flink-checkpoint/ca7caa1b21052bb1dbb02d5533b93df4/chk-5 flink_study-1.0-SNAPSHOT.jar --detached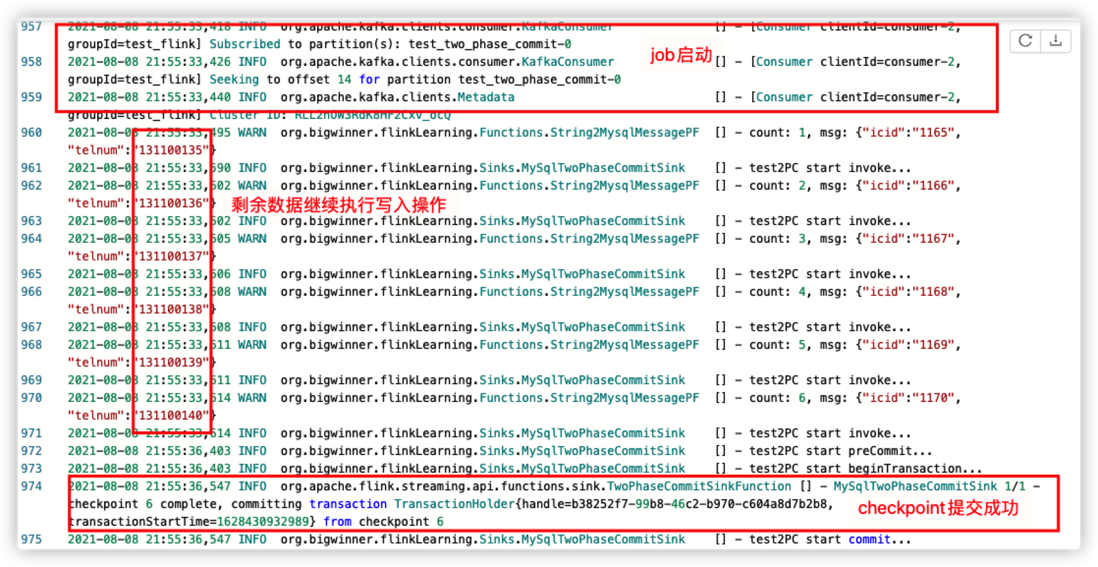
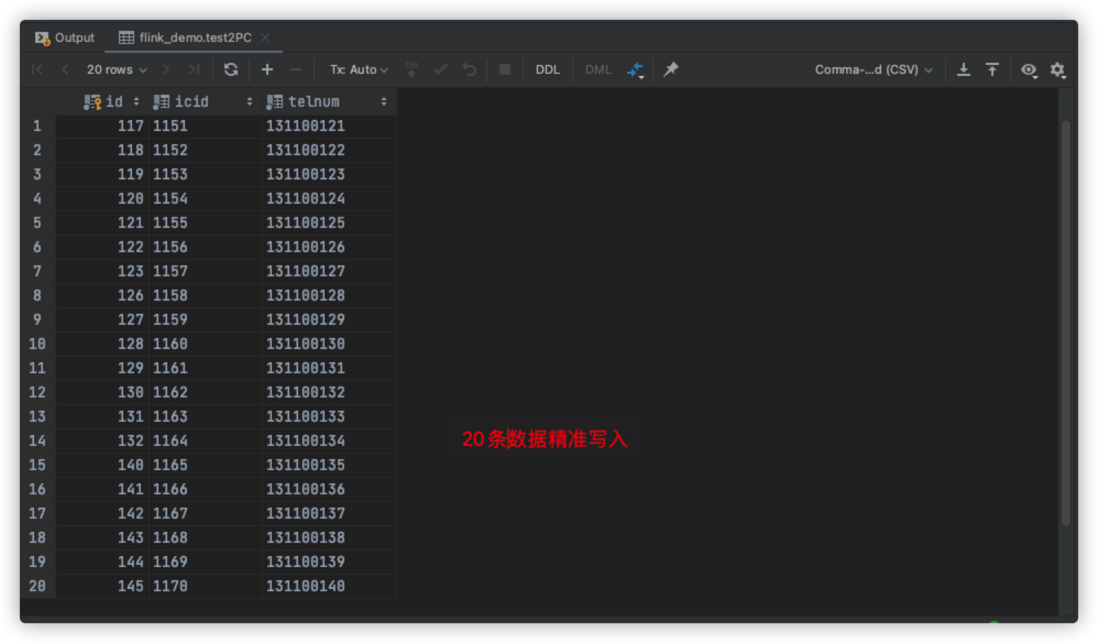
job重启成功,从截图日志可看到,没有持久化成功的数据,重新执行了写入操作,最终通过checkpoint成功提交事务。MySQL查询结果如下图:
三、总结
通过上述的测试流程,我们可以得到如下结论:
- Flink Job重启或者失败,事务都会回滚,并且都能最终保证数据的精确一次消费。
- Flink CheckPoin和两阶段提交时密切绑定的。
- 自定义MySQL sink实现TwoPhaseCommitSinkFunction类可完成MySQL系统友好的融入Flink EOS生态。
案例参考代码:flink_demo