前言
无论是在分布式系统中的ID生成,还是在业务系统中请求流水号这一类唯一编号的生成,都是软件开发人员经常会面临的一场景。而雪花算法便是这些场景的一个解决方案。
以分布式ID为例,它的生成往往会在唯一性、递增性、高可用性、高性能等方面都有所要求。并且在业务处理时,还要防止爬虫根据ID的自增进行数据爬取。而雪花算法,在这些方面表现得都不错。
常见分布式ID生成
市面上比较常见的分布式ID生成算法及类库:
UUID:Java自带API,生成一串唯一随机36位字符串(32个字符串+4个“-”)。可以保证唯一性,但可读性差,无法有序递增。
SnowFlake:雪花算法,Twitter开源的由64位整数组成分布式ID,性能较高,并且在单机上递增。GitHub上官方地址:https://github.com/twitter-ar... 。
UidGenerator:百度开源的分布式ID生成器,基于雪花算法。GitHub参考链接:https://github.com/baidu/uid-... 。该项目的说明文档及测试案例都值得深入学习一下。
Leaf:美团开源的分布式ID生成器,能保证全局唯一,趋势递增,但需要依赖关系数据库、Zookeeper等中间件。相关实现可参考该文:https://tech.meituan.com/2017... 。
雪花算法
雪花(snowflake),美丽、独特又变幻莫测。在大自然中几乎找不到两片完全一样的雪花。雪花的这些特性正好在雪花算法上有所展示。
SnowFlake算法是Twitter开源的分布式ID生成算法。核心思想就是:使用一个64 bit的 long 型的数字作为全局唯一ID。算法中还引入了时间戳,基本上保证了自增特性。
最初的版本的雪花算法是基于scala写的,当然,不同的编程语言都可以根据其算法逻辑进行实现。
### 雪花算法原理
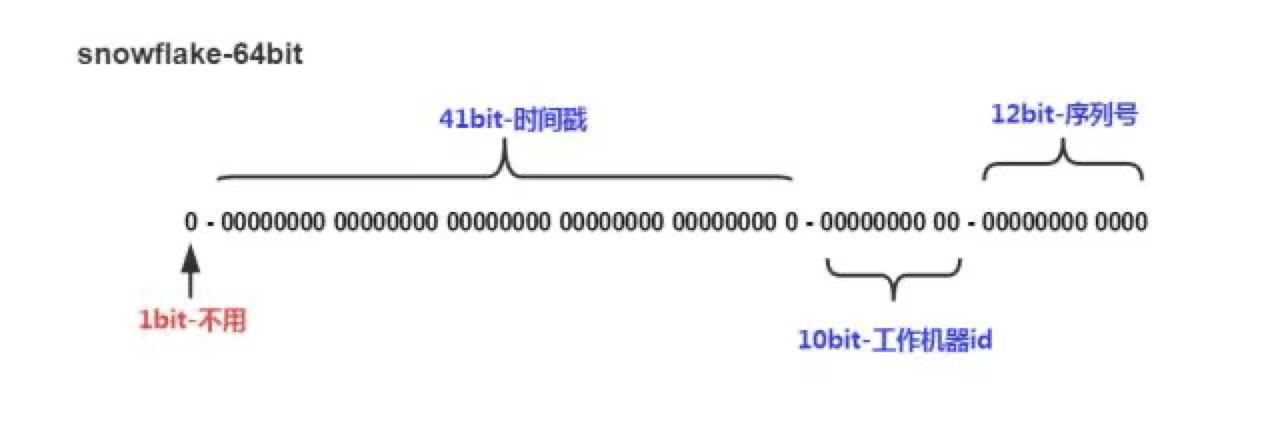
SnowFlake算法生成ID的结果是一个64bit大小的整数,结构如下图:

算法解析:
- 第一个部分:1个bit,无意义,固定为0。二进制中最高位是符号位,1表示负数,0表示正数。ID都是正整数,所以固定为0。
- 第二个部分:41个bit,表示时间戳,精确到毫秒,可以使用69年。时间戳带有自增属性。
- 第三个部分:10个bit,表示10位的机器标识,最多支持1024个节点。此部分也可拆分成5位datacenterId和5位workerId,datacenterId表示机房ID,workerId表示机器ID。
- 第四部分:12个bit,表示序列化,即一些列的自增ID,可以支持同一节点同一毫秒生成最多4095个ID序号。
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
雪花算法Java实现
雪花算法Java工具类实现:
public class SnowFlake {
/**
* 起始的时间戳(可设置当前时间之前的邻近时间)
*/
private final static long START_STAMP = 1480166465631L;
/**
* 序列号占用的位数
*/
private final static long SEQUENCE_BIT = 12;
/**
* 机器标识占用的位数
*/
private final static long MACHINE_BIT = 5;
/**
* 数据中心占用的位数
*/
private final static long DATA_CENTER_BIT = 5;
/**
* 每一部分的最大值
*/
private final static long MAX_DATA_CENTER_NUM = ~(-1L << DATA_CENTER_BIT);
private final static long MAX_MACHINE_NUM = ~(-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
/**
* 数据中心ID(0~31)
*/
private final long dataCenterId;
/**
* 工作机器ID(0~31)
*/
private final long machineId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastStamp = -1L;
public SnowFlake(long dataCenterId, long machineId) {
if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {
throw new IllegalArgumentException("dataCenterId can't be greater than MAX_DATA_CENTER_NUM or less than " +
"0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*/
public synchronized long nextId() {
long currStamp = getNewStamp();
if (currStamp < lastStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStamp == lastStamp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
//阻塞到下一个毫秒,获得新的时间戳
currStamp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStamp = currStamp;
// 移位并通过或运算拼到一起组成64位的ID
return (currStamp - START_STAMP) << TIMESTAMP_LEFT //时间戳部分
| dataCenterId << DATA_CENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewStamp();
while (mill <= lastStamp) {
mill = getNewStamp();
}
return mill;
}
private long getNewStamp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(11, 11);
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
System.out.println(snowFlake.nextId());
}
System.out.println(System.currentTimeMillis() - start);
}
}上述代码中,在算法的核心方法上,通过加synchronized锁来保证线程安全。这样,同一服务器线程是安全的,生成的ID不会出现重复,而不同服务器由于机器码不同,就算同一时刻两台服务器都产生了雪花ID,结果也是不一样的。
其他问题
41位时间戳最长只能有69年
下面来用程序推算一下,41位时间戳为什么只能支持69年。
41的二进制,最大值也就41位都是1,也就是说41位可以表示2^{41}-1个毫秒的值,转化成单位年则是(2^{41}-1) / (1000 60 60 24 365) = 69年。
通过代码验证一下:
public static void main(String[] args) {
//41位二进制最小值
String minTimeStampStr = "00000000000000000000000000000000000000000";
//41位二进制最大值
String maxTimeStampStr = "11111111111111111111111111111111111111111";
//转10进制
long minTimeStamp = new BigInteger(minTimeStampStr, 2).longValue();
long maxTimeStamp = new BigInteger(maxTimeStampStr, 2).longValue();
//一年总共多少毫秒
long oneYearMills = 1L * 1000 * 60 * 60 * 24 * 365;
//算出最大可以多少年
System.out.println((maxTimeStamp - minTimeStamp) / oneYearMills);
}所以,雪花算法生成的ID只能保证69年内不会重复,如果超过69年的话,那就考虑换个服务器(服务器ID)部署,并且要保证该服务器的ID和之前都没有重复过。
前后端数值类型
在使用雪花算法时,由于生成的ID是64位,在传递给前端时,需要考虑以字符串的类型进行传递,否则可能会导致前端类型溢出,再回传到服务器时已经变成另外一个值。
这是因为Number类型的ID在JS中最大只支持53位,直接将雪花算法的生成的ID传递给JS,会导致溢出。
小结
生成唯一性ID(其他数据)是几乎在每个系统中都会有的场景,对其生成算法不仅要保证全局唯一性、趋势递增性,还要保证信息安全(比如被爬取数据),同时还要保证算法的高可用性(QPS、可行5个9、平均延时、TP999等指标)。这就对ID生成的算法有一定的要求,而雪花算法算是一个不错的选择。
但它也是有一定的缺点的,比如强依赖机器时钟,如果机器上的时钟回拨,会导致重复或服务不可用的问题,这也是我们在使用时需要注意的事项。
博主简介:《SpringBoot技术内幕》技术图书作者,酷爱钻研技术,写技术干货文章。
公众号:「程序新视界」,博主的公众号,欢迎关注~
技术交流:请联系博主微信号:zhuan2quan