
最近在开发过程为项目中处理上下层组织关系的时候用到了递归查询,以前一般用的是直接在java中使用递归或者使用SQL的话就是编写存储过程,然后去调用这个存储过程。但是,使用java实现递归的话感觉比较麻烦,而用SQL写存储过程的话一般不建议这么做,所以这边就想到了直接用SQL实现递归。
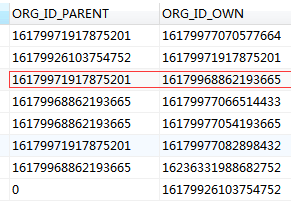
这里实现递归的是系统中的一个中间关系表(ORG_TABLE),表结构也比较简单,主要就是两个字段如下图所示ORG_ID_PARENT(上级组织机构ID)和ORG_ID_OWN(自身组织机构ID),这个比较重要一定要记住,我们在后面会有提及,此外还有一个组织机构的表这里就不讨论了,我们这里只讨论通过一个组织机构的ID获取它的所有上级组织的ID和它的所有子组织机构ID。
START WITH ... CONNECT BY PRIOR ....
我们一般使用SQL做递归的情况下用的都是上面一条语句,START WITH后面跟的是递归开始的数据,CONNECT BY后面跟的是递归的条件,PRIOR后面是递归的方向。
--查询所有子组织,父组织(包括自身)
SELECT * FROM ORG_TABLE START WITH ORG_ID_PARENT='16179968862193665' CONNECT BY ORG_ID_PARENT = PRIOR ORG_ID_OWN --查询所有子组织
union
SELECT * FROM ORG_TABLE START WITH ORG_ID_OWN='16179968862193665' CONNECT BY PRIOR ORG_ID_PARENT = ORG_ID_OWN --查询所有父组织(包括自身)
如上代码 第一条是查询出来改组织的所有下级组织,第二条数据是查出了所有组织的上级组织(包括自身)。我们这里来解析一下这写SQL的含义(16179968862193665为机构自身的ID):
1,SELECT * FROM ORG_TABLE在这里就不多做解释了,这里注意一点,我们可以把我们的WHERE条件加在后面来筛选数据。
2,START WITH ORG_ID_PARENT='16179968862193665'就是代表数据从ORG_ID_PARENT='16179968862193665'数据开始递归,先找出所有上级组织机构为'16179968862193665'的组织,这里我们可以用等号来设定一条数据,也可以用IN来设定一批数据。
3,CONNECT BY个人感觉这里就相当于WHERE的意思。
4,PRIOR在这里比较重要(注意:它放在等号之前或者之后无所谓),它代表将要递归的方向。如上代码向子组织递归,那么ORG_ID_PARENT = PRIOR ORG_ID_OWN的意思就是根据前面开始获取的那些ID开始递归,把最新获取的ID当做父组织ID,然后查找对应的子组织ID。











