
作者:八怪(高鹏) 中亦科技数据库专家
hu.com/p/d95bba14eddf
如何快速找到并杀掉引起事务阻塞的session。
本文主要讲述MySQL 5.7.29,也会加入和8.0的对比。
一、问题起源
我们在运维MySQL的过程中,肯定多多少少遇到过Innodb row lock的问题,如果在线上遇到我们可能会看到一大片的session处于堵塞状态通常我们在show processlist中会看到如下:
select for update语句处于sending data状态
update/delete语句处于updating状态
insert语句处于update状态
那么遇到这种问题如何快速的杀掉堵塞的会话呢,也许有人会说查看sys.innodb_lock_waits即可得到要杀掉的会话,但是如果我们随意模拟一下A,B,C,D 四个事务, B,C,D都同时等待A的锁(A事务不提交),那么查看sys.innodb_lock_waits会看到如下的kill语句:
mysql> select sql_kill_blocking_connection from sys.innodb_lock_waits ;+------------------------------+| sql_kill_blocking_connection |+------------------------------+| KILL 19 || KILL 18 || KILL 19 || KILL 14 || KILL 18 || KILL 19 |+------------------------------+6 rows in set (0.34 sec)
那么到底杀哪一个会话才是事务A的会话呢?
带着这个问题我们进行分析,其中加入一些代码入口。
二、sys.innodb_lock_waits的来源
实际上sys.innodb_lock_waits是一个视图,5.7.29来源为如下:
SELECT r.trx_wait_started AS wait_started, TIMEDIFF(NOW(), r.trx_wait_started) AS wait_age, TIMESTAMPDIFF(SECOND, r.trx_wait_started, NOW()) AS wait_age_secs, rl.lock_table AS locked_table, rl.lock_index AS locked_index, rl.lock_type AS locked_type, r.trx_id AS waiting_trx_id, r.trx_started as waiting_trx_started, TIMEDIFF(NOW(), r.trx_started) AS waiting_trx_age, r.trx_rows_locked AS waiting_trx_rows_locked, r.trx_rows_modified AS waiting_trx_rows_modified, r.trx_mysql_thread_id AS waiting_pid, sys.format_statement(r.trx_query) AS waiting_query, rl.lock_id AS waiting_lock_id, rl.lock_mode AS waiting_lock_mode, b.trx_id AS blocking_trx_id, b.trx_mysql_thread_id AS blocking_pid, sys.format_statement(b.trx_query) AS blocking_query, bl.lock_id AS blocking_lock_id, bl.lock_mode AS blocking_lock_mode, b.trx_started AS blocking_trx_started, TIMEDIFF(NOW(), b.trx_started) AS blocking_trx_age, b.trx_rows_locked AS blocking_trx_rows_locked, b.trx_rows_modified AS blocking_trx_rows_modified, CONCAT('KILL QUERY ', b.trx_mysql_thread_id) AS sql_kill_blocking_query, CONCAT('KILL ', b.trx_mysql_thread_id) AS sql_kill_blocking_connection FROM information_schema.innodb_lock_waits w INNER JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id INNER JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id INNER JOIN information_schema.innodb_locks bl ON bl.lock_id = w.blocking_lock_id INNER JOIN information_schema.innodb_locks rl ON rl.lock_id = w.requested_lock_id ORDER BY r.trx_wait_started;
可以看到它的来源实际上就是
information_schema.innodb_lock_waits
information_schema.innodb_trx
information_schema.innodb_locks 这三个表。
那么我们有必要搞清楚这3个表的数据到底包含了哪些事务的信息。
三、各自的信息来源
information_schema.innodb_trx:这个表的数据在每次进行查询的时候进行装载,主要包含了全部的读写事务和只读事务的全部信息来源为trx_sys.rw_trx_list和trx_sys.mysql_trx_list。在函数fetch_data_into_cache可以看到它的调用方式。
information_schema.innodb_locks:这个表的数据在每次进行查询的时候进行装载,主要包含了当前处于等待状态事务的等待某个row lock资源队列上所有request事务和blocking事务,内部有一个去重操作位于add_lock_to_cache函数中。但是在8中这里叫做performance_schema.data_locks,包含的信息不同,其会包含所有的已经获取和需要获取的全部rec lock信息,类似show engine innodb status出来的信息。
information_schema.innodb_lock_waits:这个表的数据在每次进行查询的进行装载,主要包含了每个处于等待状态事务中关于这个row lock资源队列的所有事务信息。在8中叫做performance_schema.data_lock_waits,其基本信息和5.7没有太大差别。
实际上这个等待队列实际上存在于row lock的hash查找表中,查询的时候才会根据其取出每个事务的等待锁资源的队列信息。
其内部为一个迭代器lock_queue_iterator_reset(&iter, trx->lock.wait_lock, ULINT_UNDEFINED),这个迭代器用于迭代row lock hash查找表中的队列信息,其迭代的开始就是当前处于等待状态事务的锁资源(request事务的row lock)位于trx->lock.wait_lock中,这个过程位于add_trx_relevant_locks_to_cache函数中。
其次在5.7.29中这3个信息通常是同时装载的,他们共同位于函数fetch_data_into_cache下面,有如下
fetch_data_into_cache -> fetch_data_into_cache_low(cache, true, &trx_sys->rw_trx_list) 本处循环每一个读写事务装载数据 ->add_trx_relevant_locks_to_cache 本处循环迭代整个等待队列进行转载数据,包含information_schema.innodb_locks和information_schema.innodb_lock_waits 将读写事务信息装载入information_schema.innodb_trx中 -> fetch_data_into_cache_low(cache, false, &trx_sys->mysql_trx_list) 本处循环每一个事务装载数据,并且会跳过已经装载的读写事务 将只读事务信息装载入information_schema.innodb_trx中
四、用一个图来进行说明
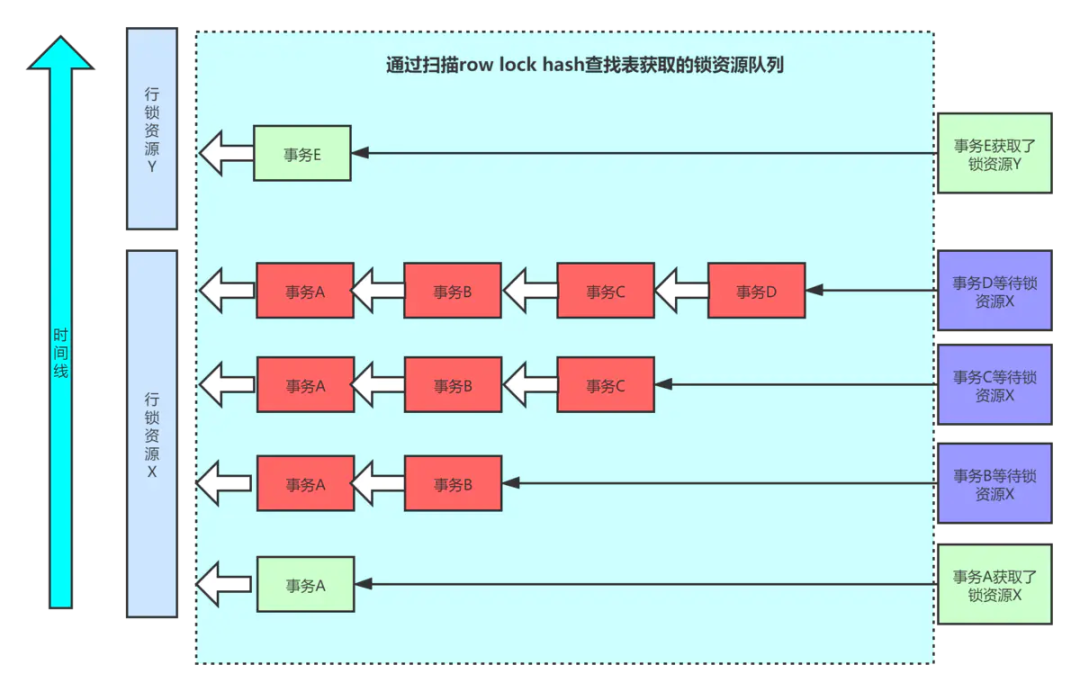
假设我们这里有5个读写事务且都没有提交,是A、B、C、D、E。其中A事务获取了某行的锁资源X,其他B、C、D都在等待,而事务E单独自己获取了一个行锁资源Y。 那 么我们分别对应一下三个表中的数据如下:
information_schema.innodb_trx:包含了A、B、C、D、E这5个事务的信息。当然这里没有只读事务,如果有只读事务也会包含在其中,代码中我可以看一下主要通过(!rw_trx_list && trx->id != 0)来进行只读事务的判断,及通过是否在读写队列和事务ID是否为0进行判定(因为只读事务没有分配事务ID为0)
information_schema.innodb_locks:包含了图中红色部分的全部事务,因此包含了A,B,C,D这4个事务,但是由于会去重,因此他们只会出现一次。这个表的信息5.7和8有所不同上面已经描述
information_schema.innodb_lock_waits:包含了图中红色部分的全部事务,并且有详细的队列信息如下,这表5.7和8没有太大差距。
事务D
事务C
事务B
waitting 事务D->blocking 事务C
waitting 事务C->blocking 事务B
waitting 事务B->blocking 事务A
waitting 事务D->blocking 事务B
waitting 事务C->blocking 事务A
waitting 事务D->blocking 事务A
那么就会出现6行信息,这一点5.7和8的行数是一样的。5.7.29如下: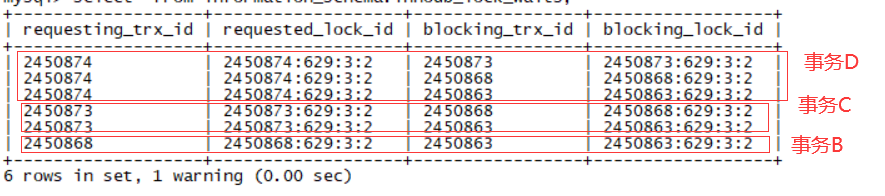
8.0.18如下:

这里我们需要注意了,既然如此那么我们可以发现information_schema.innodb_lock_waits的blocking_trx_id中出现次数最多的事务ID很可能就是堵塞的源头,而sys.innodb_lock_waits中的信息正是完全来自information_schema.innodb_lock_waits和其他两个表的join,同样也是6行如下:
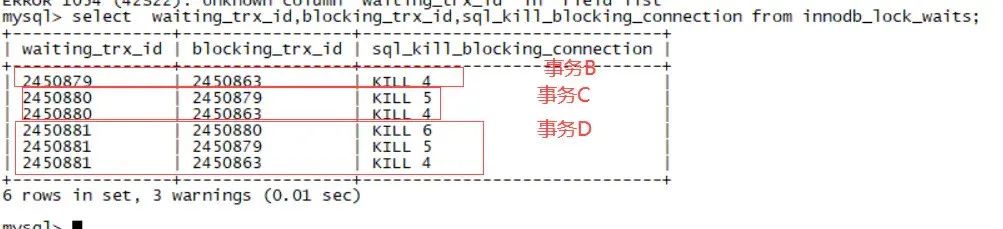
只不过通过连接找到了blocking事务的process id而已。
五、如何快速杀掉可能的堵塞源头
既然有了前面的分析就很简单了,我们可以通过如下方法(5.7/8.0通用):
1. 执行语句找出堵塞最多的session
select trim(LEADING 'KILL ' from sql_kill_blocking_connection),count(*)from sys.innodb_lock_waits group by trim(LEADING 'KILL ' from sql_kill_blocking_connection) order by count(*) desc;+---------------------------------------------------------+----------+| trim(LEADING 'KILL ' from sql_kill_blocking_connection) | count(*) |+---------------------------------------------------------+----------+| 407 | 12 || 408 | 11 || 409 | 10 || 410 | 9 || 411 | 8 || 412 | 7 || 413 | 6 || 414 | 5 || 415 | 4 || 416 | 3 || 417 | 2 || 418 | 1 |+---------------------------------------------------------+----------+
排名第一个的说明堵塞的会话越多。
2、找到process id 407当前的事务信息
观察其事务状态和可能执行的语句或者上一条语句判断是否可以杀掉。
select trx_id,trx_operation_state,trx_mysql_thread_id prs_id,now(),trx_started,to_seconds(now())-to_seconds(trx_started) trx_es_time,user,db,host,state,Time,info current_sql,PROCESSLIST_INFO last_sqlfrom information_schema.innodb_trx t1,information_schema.processlist t2,performance_schema.threads t3where t1.trx_mysql_thread_id=t2.id and t1.trx_mysql_thread_id=t3.PROCESSLIST_IDand t1.trx_mysql_thread_id!=connection_id()and t2.id=407;
当然也可以在杀掉session之前,保存一份show engine innodb status信息用于后期分析所用。
3、循环这个过程,因为堵塞的row lock资源可能不止一个
全文完。
Enjoy MySQL :)
叶老师的「MySQL核心优化」大课已升级到MySQL 8.0,扫码开启MySQL 8.0修行之旅吧

本文分享自微信公众号 - 老叶茶馆(iMySQL_WX)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










