本文分享自天翼云开发者社区《Flink 与Flink可视化平台StreamPark教程(DataStreamApi基本使用)》,作者:l****n
DataStreamApi
dataStreamApi是一切的基础,处于调度flink程序处理任务的起点。Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。因此在这里我们统称为DataStream Api。首先在这里我们需要新建一个项目,并使用maven管理版本、依赖。其中pom文件如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.ctyun</groupId>
<artifactId>flink-demo-jar-job</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
<flink.sql.connector.cdc.version>2.2.1</flink.sql.connector.cdc.version>
</properties>
<dependencies>
<!-- 引入Flink相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>mysql</groupId>-->
<!-- <artifactId>mysql-connector-java</artifactId>-->
<!-- <version>8.0.27</version>-->
<!-- </dependency>-->
<!-- flink connector cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink.sql.connector.cdc.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.80</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>之后,我们可以在此基础上完成我们的flink任务的编码。整套DataStream的流程无外乎以下几步,关于具体的使用,本章节会在代码中通过注释的方式标出来每一步的具体代码:
- 获取执行环境
- 读取数据源,一般称为source操作
- 定义数据转换流程,一般称之为transformations,我们经常听到的map reduce流程就是在这一步
- 定义结果输出,一般称为sink操作
- 最终触发程序的执行,一般称之为execute操作
MAP-REDUCE流程
Map-Reduce是大数据领域中十分传统的流程之一。和Hadoop MapReduce相似,flink中也需要对其中的Map、Reduce、Shuffle、Aggregate等接口进行实现,以供flink在运行时能够调用。
对于flink而言,其开发方法主要以实现各种Function接口为主来定义各种算子。对于Java 1.8后的版本,支持通过Lambda的方式进行代码,大量的代码使用函数式编程。
一般而言,map顾名思义代表了映射,是从一条数据到另一条或几条的映射操作,reduce代表了“减少”、“规约”是将数据从多条到一条的统计操作。通过两个操作的结合,即可实现简单的统计操作。以下将给出一个案例。
数据输入
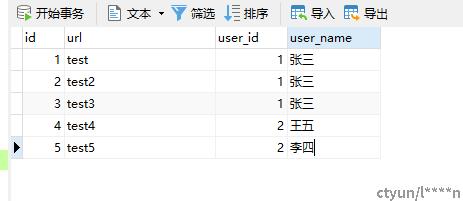
在这里我们首先创建一个数据源,通过和先前建立的mysql数据源取得交互后进行运行以下sql脚本
/*
Navicat Premium Data Transfer
Source Server : 原生mysql专用于cdc
Source Server Type : MySQL
Source Server Version : 50725
Source Host : ******
Source Schema : test_cdc_source
Target Server Type : MySQL
Target Server Version : 50725
File Encoding : 65001
Date: 24/04/2023 14:23:19
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for view_content
-- ----------------------------
DROP TABLE IF EXISTS `view_content`;
CREATE TABLE `view_content` (
`id` int(11) NOT NULL,
`url` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`user_id` int(11) NULL DEFAULT NULL,
`user_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
在完成数据源初始化后,我们建立一个数据源的输入类,作为DataStreamApi格式的数据源输入,如下所示:
package cn.ctyun.demo.api.watermark;
import cn.ctyun.demo.api.utils.TransformUtil;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
/**
* @classname: ViewContentStreamWithoutWaterMark
* @description: 浏览记录数据源不包含水位线
* @author: Liu Xinyuan
* @create: 2023-04-14 13:47
**/
public class ViewContentStreamWithoutWaterMark {
public static DataStream<JSONObject> getViewContentDataStream(StreamExecutionEnvironment env){
// 1.创建Flink-MySQL-CDC的Source
MySqlSource<String> viewContentSouce = MySqlSource.<String>builder()
.hostname("******")
.port(3306)
.username("******")
.password("******")
.databaseList("test_cdc_source")
.tableList("test_cdc_source.user_view")
.startupOptions(StartupOptions.initial())
.deserializer(new JsonDebeziumDeserializationSchema())
.serverTimeZone("Asia/Shanghai")
.build();
// 2.使用CDC Source从MySQL读取数据
DataStreamSource<String> mysqlDataStreamSource = env.fromSource(
viewContentSouce,
WatermarkStrategy.noWatermarks(),
"ViewContentStreamNoWatermark Source"
);
// 3.转换为指定格式
return mysqlDataStreamSource.map(TransformUtil::formatResult);
}
}
这里有一个针对CDC的数据转换工具类,需要在您的项目中一同定义:
package cn.ctyun.demo.api.utils;
import cn.ctyun.demo.api.enums.OpEnum;
import com.alibaba.fastjson.JSONObject;
/**
* @classname: TransformUtil
* @description: 转换工具类
* @author: Liu Xinyuan
* @create: 2023-04-14 09:44
**/
public class TransformUtil {
/**
* 格式化抽取数据格式
* 去除before、after、source等冗余内容
*
* @param extractData 抽取的数据
* @return
*/
public static JSONObject formatResult(String extractData) {
JSONObject formatDataObj = new JSONObject();
JSONObject rawDataObj = JSONObject.parseObject(extractData);
formatDataObj.putAll(rawDataObj);
formatDataObj.remove("before");
formatDataObj.remove("after");
formatDataObj.remove("source");
String op = rawDataObj.getString("op");
if (OpEnum.DELETE.getDictCode().equals(op)) {
// 新增取 before结构体数据
formatDataObj.putAll(rawDataObj.getJSONObject("before"));
} else {
// 其余取 after结构体数据
formatDataObj.putAll(rawDataObj.getJSONObject("after"));
}
return formatDataObj;
}
}完成如上操作后,我们即能够拥有一个标准的流式输入,之后的相关开发可以以此作为基础。
MapReduce流程UDF算子开发
- 上文中说到,flink中的开发主要是对各种编程接口进行实现,已达到自己的业务需求。对于一个mapreduce任务而言,自然需要实现如下几个接口的实现
- MapFunction接口:用于实现数据的转换,将一条数据进行一定规则的映射
- KeySelector接口:用于通过将数据按键统计,将相同的键值下的数据放到一块统计
- ReduceFunction接口:用于将多条数据合并成一条,一般用于将数据进行规约形成统计值
在这里,将提供一个用于统计用户访问量的案例,复用上文提供的数据源方案,进行用户的访问数据量统计。在这里,我们实现了以上一套接口的实现,达到了我们业务流程,整个接口的实现如下所示:
- 这里,我们首先实现了map接口,将一条数据的输入简单地将一条访问记录映射成了二元组(当前用户名, 1),这样表示为将一条用户登录信息映射成了一个人来了1次
- 之后我们实现了一个KeySelector接口,这个接口主要将不同数据进行分组处理,在本实例中,我们将相同用户名的数据分为一个组,供后续统计处理
- 最后地,实现了ReduceFunction接口,将多条数据映射成一条。
package cn.ctyun.demo.api;
import cn.ctyun.demo.api.watermark.ViewContentStreamWithoutWaterMark;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @classname: ApiNormalMapReduce
* @description: 标准MapReduce流程
* @author: Liu Xinyuan
* @create: 2023-04-24 14:29
**/
public class ApiNormalMapReduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithoutWaterMark.getViewContentDataStream(env);
SingleOutputStreamOperator<Tuple2<String, Long>> reduce = viewContentDataStream.map(new CountUserToOneMap())
.keyBy(new CountUserKeySelector())
.reduce(new CountUserReduceFunction());
reduce.print("用户统计数:");
env.execute();
}
public static class CountUserToOneMap implements MapFunction<JSONObject, Tuple2<String, Long>> {
/**
*
* @param value 输入数据
* @return 转换后的数据
* @throws Exception 异常
*/
@Override
public Tuple2<String, Long> map(JSONObject value) throws Exception {
return Tuple2.of(value.getString("user_name"), 1L);
}
}
public static class CountUserKeySelector implements KeySelector<Tuple2<String, Long>, String>{
/**
*
* @param value 输入的数据样式
* @return 输入数据样式中的键
* @throws Exception 异常
*/
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
}
public static class CountUserReduceFunction implements ReduceFunction<Tuple2<String, Long>>{
/**
*
* @param value1 上一条数据
* @param value2 新的数据
* @return 两条数据合并后的结果
* @throws Exception
*/
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
}
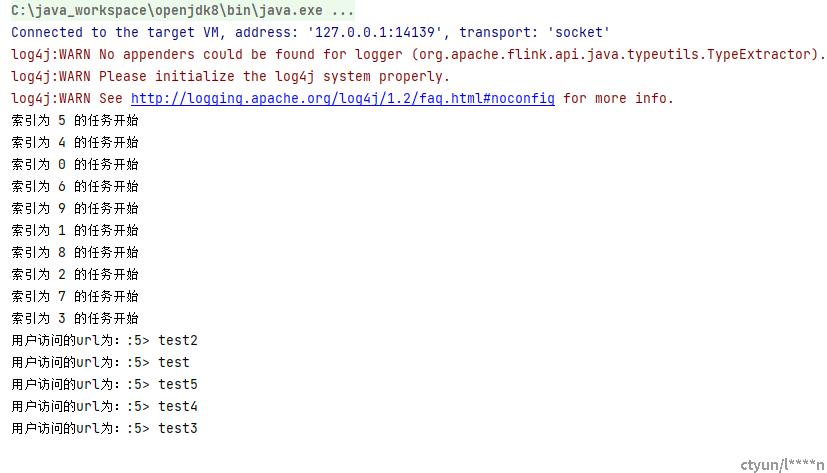
}按照如下步骤添加数据后,flink能够根据之前的统计值进行统计,当数据输入时,实时获取当前用户的访问数量。以此,我们实现了一个简单的MapReduce流程。
聚合函数的使用
直观地说,基本的转换运算符确实在“转换”——因为它们都是基于当前数据并经过处理的以及输出。在实际应用中,我们经常需要统计或整合大量数据,以提取更有用的数据信息。在之前的实例中,我们进行了统计用户的访问数量的操作,在程序运行时需要对每个访问记录进行叠加和计数。此操作计算结果不仅依赖于当前数据,还与以前的数据有关,这相当于将所有数据聚合并合并在一起--这被称为“聚合”,也对应于MapReduce中的reduce操作。
在先前的实例中,我们使用过KeyBy功能,将不同的数据按键进行分区。 KeyBy是一个运算符,必须在聚合之前使用。KeyBy可以通过指定一个键在逻辑上将流划分为不同的分区。这里提到的分区实际上是并行处理的一个子任务,它对应于一个任务槽(taskSlots)。根据不同的密钥,流中的数据将被分配到不同的分区;这样,所有具有相同密钥的数据都将被发送到同一个分区,之后,其对应的后续操作将会在特定的分区进行,实现对这一组数据的统一处理。
一般地,在经过按键聚合后,可以调用flink提供的内置简单聚合函数进行操作,如下所示:
- sum():对指定的字段做叠加求和的操作。
- min():对指定的字段求最小值。
- max():对指定的字段求最大值。
- minBy():对指定字段求最小值。不同的是,
- min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包 含字段最小值的整条数据。
- maxBy():对指定字段求最大值。 在这里,我们提供一个案例,将上述代码进行验证,同样地,其输入数据源为mysql cdc
package cn.ctyun.demo.api;
import cn.ctyun.demo.api.watermark.ViewContentStreamWithoutWaterMark;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @classname: ApiNormalAggregate
* @description: 简单聚合函数的使用
* @author: Liu Xinyuan
* @create: 2023-04-25 15:24
**/
public class ApiNormalAggregate {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithoutWaterMark.getViewContentDataStream(env);
KeyedStream<Tuple2<String, Long>, String> tuple2StringKeyedStream = viewContentDataStream.map(new CountUserToOneMap())
.keyBy(new CountUserKeySelector());
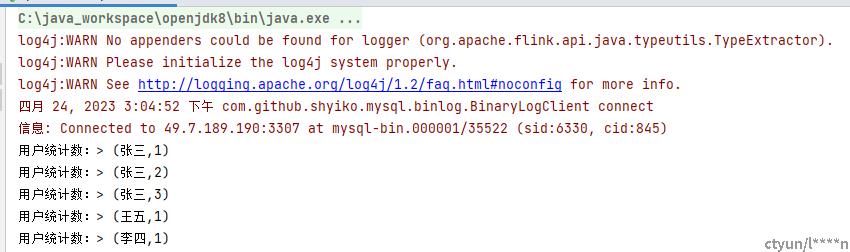
tuple2StringKeyedStream.sum(1).print("按用户名进行sum");
tuple2StringKeyedStream.min(1).print("按用户名进行min");
tuple2StringKeyedStream.max(1).print("按用户名进行max");
tuple2StringKeyedStream.minBy(1).print("按用户名进行minBy");
tuple2StringKeyedStream.maxBy(1).print("按用户名进行maxBy");
env.execute();
}
public static class CountUserToOneMap implements MapFunction<JSONObject, Tuple2<String, Long>> {
/**
*
* @param value 输入数据
* @return 转换后的数据
* @throws Exception 异常
*/
@Override
public Tuple2<String, Long> map(JSONObject value) throws Exception {
return Tuple2.of(value.getString("user_name"), 1L);
}
}
public static class CountUserKeySelector implements KeySelector<Tuple2<String, Long>, String>{
/**
*
* @param value 输入的数据样式
* @return 输入数据样式中的键
* @throws Exception 异常
*/
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
}
}需要注意的是,其这些简单聚合函数只适用于Tuple类型、Scala事例类和基元类型或者是简单的POJO类,这就对我们输入这个算子的格式有一定的要求。在下一章节中,将会继续讲解如何自定义一个这样的聚合函数(AggregateFunction),面对复杂的应用场景。
富函数的使用
在flink中,对不同的算子提供了一个Rich的版本(富函数),比如RichMapFunction、RichReduceFunction等。这类函数一般比常规函数具有更多功能,比如其可以获取运行环境的上下文、拥有着自己的生命周期。一般地,其生命周期在与数据库连接、任务状态保持功能中非常重要,与数据库连接的数据源功能一般都会使用富函数对连接状态进行保持。
我们假定一个场景,在这个场景中,我们需要在一个MAP方法使用时打印其分片名,提供一个代码如下所示:
可知的是,富函数启动后,flink框架将首先调用open方法,在这里我们的open方法提供了打印索引号的功能,在这里一般可以感知到我们flink的启动配置项(flinkConfig)。其他的,map方法和普通的MapFunction方法类似。