作者:宋彤彤
2019 新冠肺炎疫情爆发,让人们的出行发生了很大的变化——自 1 月 24 日武汉宣布封城之后,各省市陆续启动重大突发公共卫生事件一级响应以控制人口流动。很多城市都已规定必须佩戴口罩、测量体温才能搭乘公共交通。2 月 10 号返工日之前,上海、北京等重点城市也陆续放出新规:出入机场、轨道交通、长途汽车站、医疗卫生机构、商场超市等公共场所,未佩戴口罩者将被劝阻。
2 月 13 日,百度飞桨宣布开源业界首个口罩人脸检测及分类模型。基于此模型,可以在公共场景检测大量的人脸同时,把佩戴口罩和未佩戴口罩的人脸标注出来,快速识别各类场景中不重视、不注意防护病毒,甚至存在侥幸心理的人,减少公众场合下的安全隐患。同时构建更多的防疫公益应用。
在目前的社会背景下,相信很多 AI 学习者会关注计算机视觉方向的目标检测算法,所以我们就来看一下最近比较热门的 YOLO 系列算法的 v1 版本。

1 背景知识
近些年来,目标检测算法取得了很大的突破。比较流行的算法可以分为两类,一类是基于 Region Proposal 的 R-CNN 系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是 two-stage 的,需要先使用启发式方法(selective search)或者 CNN 网络(RPN)产生 Region Proposal,然后再在 Region Proposal 上做分类与回归。而另一类是 Yolo、SSD 这类 one-stage 算法,其仅仅使用一个 CNN 网络直接预测不同目标的类别与位置。第一类方法准确度高一些,但是速度慢;第二类算法速度快,但是准确性要低一些。
本文介绍的 Yolo 算法,其全称是 You Only Look Once: Unified, Real-Time Object Detection。这个题目基本上把 Yolo 算法的特点概括了:You Only Look Once 指的是只需要一次 CNN 运算;Unified 指的是这是一个统一的框架,提供 end-to-end 的预测;而 Real-Time 体现 Yolo 算法速度快。
2 设计理念

整体来看,Yolo 算法采用一个单独的 CNN 模型实现 end-to-end 的目标检测,整个系统如上图所示:首先将输入图片 resize 到 $448 \times 448$,然后送入 CNN 网络,最后处理网络预测结果得到检测的目标。相比 R-CNN 算法是一个统一的框架,其速度更快,而且 Yolo 的训练过程也是 end-to-end 的。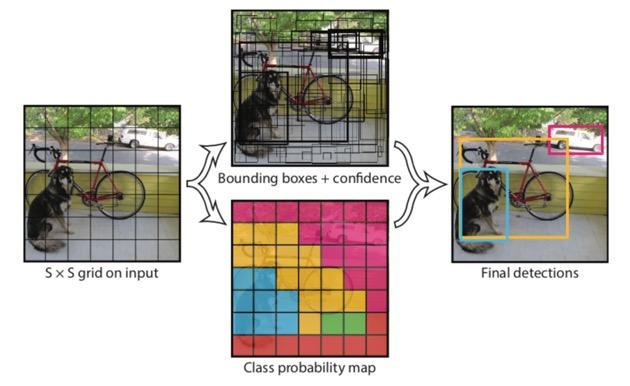
系统将输入图像划分为 $S \times S$ 网格。 如果一个目标的中心落入网格单元,则该网格单元负责检测该目标。每个网格单元预测 $B$ 个 bounding box 和 box 的置信度得分。 这些置信度得分反映了该模型对盒子包含一个对象的信心,以及它认为盒子预测的准确性。 形式上,我们将置信度定义为 $Pr(Object)\times IOU$,$IOU$ 指 intersection over union between the predicted box and the ground truth。 如果该单元格中没有预测对象,则置信度应为零;否则置信度等于 $IOU$。每个 bounding box 由$5$个预测组成:$x$,$y$,$w$,$h$和置信度。$x, y$ 表示 bounding box 相对于网格单元边界的中心;$w, h$ 相对于整个图像预测宽度和高度;最后,置信度表示预测框与真实框之间的$IOU$。
每个网格单元还预测$ C $个条件类概率 $Pr(Class_i | Object)$。 这些概率以网格单元包含检测对象为条件。 无论 B 的数量如何,仅预测每个网格单元的一组类概率。
在测试时,将条件类别的概率与各个框的置信度预测相乘:
$$ Pr(Class_i | Object) \times Pr(Object) \times IOU^{truth}_{pred} = Pr(Class_i) \times IOU^{truth}_{pred}$$
从而得出每个框的某一类的置信度。 这些结果既代表了该类别出现在盒子中的概率,也预测了 bounding box 适合所检测对象的程度。
3 网络设计

根据以上结构图,输入图像大小为 $448 \times 448$,经过若干个卷积层与池化层,变为 $7\times7\times1024$ 张量(图一中倒数第三个立方体),最后经过两层全连接层,输出张量维度为 $7\times7\times30$,这就是 Yolo v1 的整个神经网络结构,和一般的卷积物体分类网络没有太多区别,最大的不同就是:分类网络最后的全连接层,一般连接于一个一维向量,向量的不同位代表不同类别,而这里的输出向量是一个三维的张量( $7\times7\times30$)。上图中 Yolo 的网络结构,受启发于 GoogLeNet,也是 v2、v3 中 Darknet 的先锋。本质上来说没有什么特别,没有使用 BN 层,用了一层 Dropout。除了最后一层的输出使用了线性激活函数,其他层全部使用 Leaky Relu 激活函数。
论文中还训练了一种快速版本的 YOLO,旨在突破快速物体检测的界限。 Fast YOLO 使用的神经网络具有较少的卷积层( 9 个而不是 24 个),并且这些层中的过滤器较少。 除了网络的规模外,YOLO 和 Fast YOLO 之间的所有训练和测试参数都相同。
4 LOSS函数
神经网络结构确定之后,训练效果好坏,由 Loss 函数和优化器决定。Yolo v1 使用普通的梯度下降法作为优化器。这里重点解读一下 Yolo v1 使用的 Loss 函数:

Loss 函数,论文中给出了比较详细的解释。所有的损失都是使用平方和误差公式,暂时先不看公式中的 $\lambda_{coord}$与$\lambda_{noobj}$ ,输出的预测数值以及所造成的损失有:
- 预测框的中心点$(x, y)$ 。造成的损失是第一行。其中 $\mathbb{1}^{obj}_{ij}$ 为控制函数,在标签中包含物体的那些格点处,该值为 1 ;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。(x, y) 数值与标签用简单的平方和误差。
- 预测框的宽高$(w, h)$ 。造成的损失是图第二行。$\mathbb{1}^{obj}_{ij}$ 的含义一样,也是使得只有真实物体所属的格点才会造成损失。这里对(w, h)在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,$20$ 个像素点的偏差,对于 $800 \times 600$ 的预测框几乎没有影响,此时的 IOU 数值还是很大,但是对于 $30 \times 40$ 的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
- 预测框的置信度 C。第三行与第四行。当该格点不含有物体时,该置信度的标签为 0;若含有物体时,该置信度的标签为预测框与真实物体框的 IOU 数值。
- 物体类别概率 P。第五行。对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。
此时再来看 $\lambda_{coord}$与$\lambda_{noobj}$ ,Yolo 面临的物体检测问题,是一个典型的类别数目不均衡的问题。其中 49 个格点,含有物体的格点往往只有 3、4 个,其余全是不含有物体的格点。此时如果不采取措施,那么物体检测的 mAP 不会太高,因为模型更倾向于不含有物体的格点。$\lambda_{coord}$与$\lambda_{noobj}$ 的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。在论文中, $\lambda_{coord}$与$\lambda_{noobj}$ 的取值分别为 5 与 0.5。
5 一些技巧
- 回归offset代替直接回归坐标
We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1
(x,y)不直接回归中心点坐标数值,而是回归相对于格点左上角坐标的位移值。例如,第一个格点中物体坐标为 (2.3, 3.6) ,另一个格点中的物体坐标为(5.4,6.3),这四个数值让神经网络暴力回归,有一定难度。所以这里的 offset 是指,既然格点已知,那么物体中心点的坐标一定在格点正方形里,相对于格点左上角的位移值一定在区间 [0, 1) 中。让神经网络去预测 (0.3, 0.6) 与(0.4, 0.3) 会更加容易,在使用时,加上格点左上角坐标(2, 3)、(5, 6)即可。
- 同一格点的不同预测框有不同作用
At training time we only want one bounding box predictor to be responsible for each object. We assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at predicting certain sizes, aspect ratios, or classes of object, improving overall recall.
前文中提到,每个格点预测两个或多个矩形框。此时假设每个格点预测两个矩形框。那么在训练时,见到一个真实物体,我们是希望两个框都去逼近这个物体的真实矩形框,还是只用一个去逼近?或许通常来想,让两个人一起去做同一件事,比一个人做一件事成功率要高,所以可能会让两个框都去逼近这个真实物体。但是作者没有这样做,在损失函数计算中,只对和真实物体最接近的框计算损失,其余框不进行修正。这样操作之后作者发现,一个格点的两个框在尺寸、长宽比、或者某些类别上逐渐有所分工,总体的召回率有所提升。
- 使用非极大抑制生成预测框
However, some large objects or objects near the border of multiple cells can be well localized by multiple cells. Non-maximal suppression can be used to fix these multiple detections. While not critical to performance as it is for R-CNN or DPM, non-maximal suppression adds 2 - 3% in mAP.
通常来说,在预测的时候,格点与格点并不会冲突,但是在预测一些大物体或者邻近物体时,会有多个格点预测了同一个物体。此时采用非极大抑制技巧,过滤掉一些重叠的矩形框。但是 mAP 提升并没有显著提升。(非极大抑制,物体检测的老套路,这里不再赘述)
- 推理时将 $p * c$ 作为输出置信度
$$ Pr(Class_i | Object) \times Pr(Object) \times IOU^{truth}_{pred} = Pr(Class_i) \times IOU^{truth}_{pred}$$
在推理时,使用物体的类别预测最大值 $p$ 乘以 预测框的最大值 $c$ ,作为输出预测物体的置信度。这样也可以过滤掉一些大部分重叠的矩形框。输出检测物体的置信度,同时考虑了矩形框与类别,满足阈值的输出更加可信。
6 与其他算法比较
与其他算法比较的结论照搬论文,如下性能的硬件环境都是 GPU Titan X。
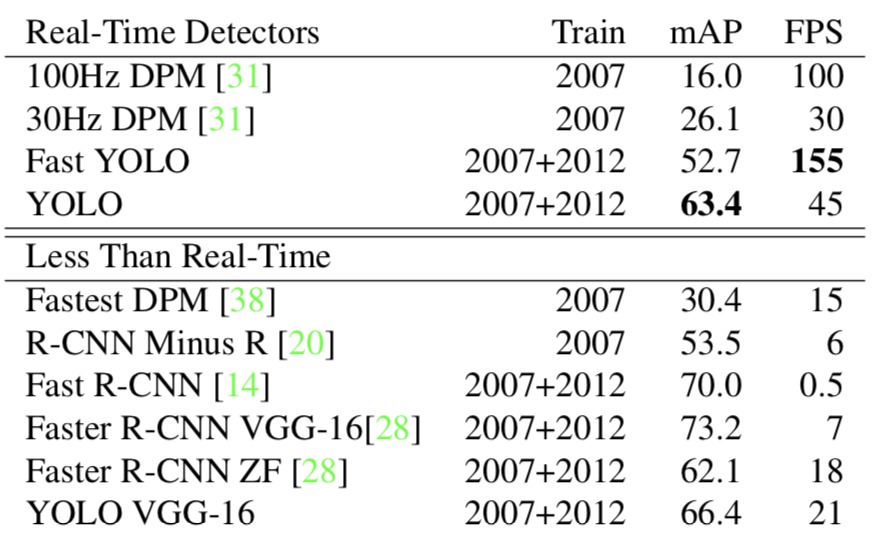
backbone 同为 VGG-16,Yolo 比 Faster R-CNN 少了将近 7 点 mAP,但是速度变为三倍,Fast Yolo 和 Yolo 相比,少 11 点 mAP,但是速度可以达到 155 张图片每秒。后续的 Yolo v3 中,准确率和速度综合再一次提升,所以 v1 的性能不再过多分析。
下面重点看论文中的错误分析: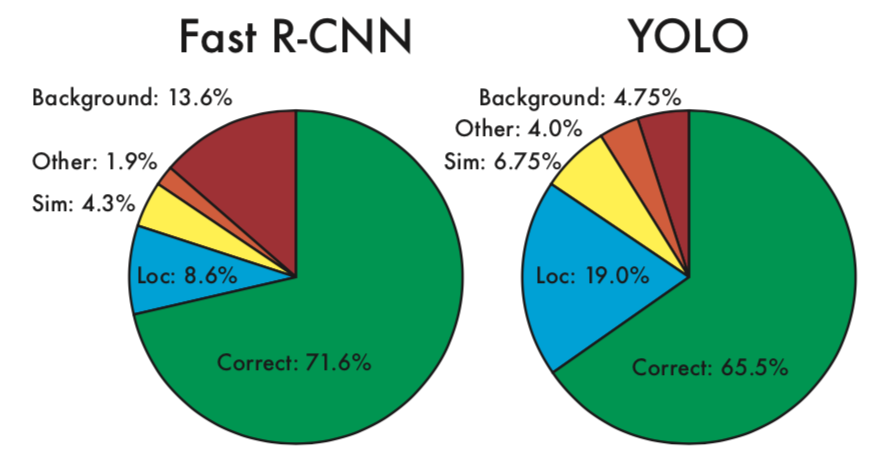
首先给出图中各个单词的含义:
• Correct: correct class and IOU > .5 >
• Localization: correct class, .1 < IOU < .5 >
• Similar: class is similar, IOU > .1 >
• Other: class is wrong, IOU > .1>
• Background: IOU < .1 for any object
其中,Yolo 的 Localization 错误率更高,直接对位置进行回归,确实不如滑窗式的检测方式准确率高。但是 Yolo 对于背景的误检率更低,由于 Yolo 在推理时,可以“看到”整张图片,所以能够更好的区分背景与待测物体。作者提到 Yolo 对于小物体检测效果欠佳,不过在 v2 与 v3 中都做了不少改进。
项目源码地址:https://momodel.cn/explore/5e5b95bc595a8c7bd5ccb5e2?type=app
7 参考文献
- 论文 You Only Look Once: Unified, Real-Time Object Detection: https://arxiv.org/abs/1506.02640
- 论文解读:https://zhuanlan.zhihu.com/p/70387154
- 论文解读:https://blog.csdn.net/c20081052/article/details/80236015
- 源码引用:https://github.com/thtrieu/darkflow
关于我们
Mo(网址:https://momodel.cn) 是一个支持 Python的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo人工智能俱乐部 是由 Mo 的研发与产品团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。