
我们正在做一个电子书的小程序。
1.0 层次模型数据库
用户购买,生成订单,订单详情里有用户购买的电子书:
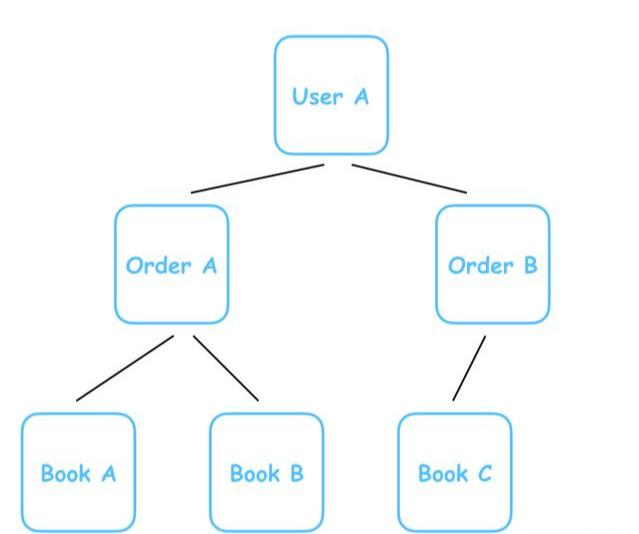
Mysql、MongoDB?如何选择合适的数据库
一层一层铺开,一对多,这是「层次模型数据库」(Hierarchical Database)。
2.0 网状模型数据库
一笔订单可以购买多本电子书,一本电子书也可以被多笔订单购买:
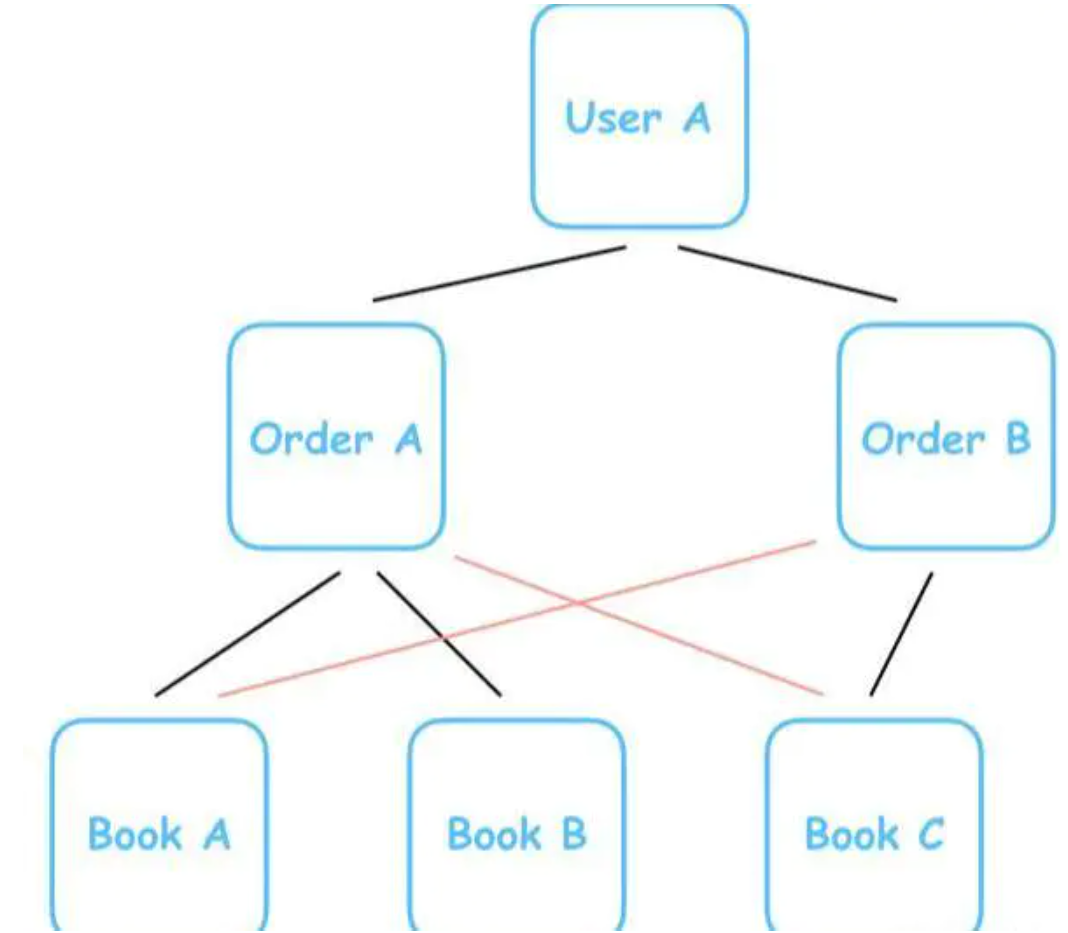
Mysql、MongoDB?如何选择合适的数据库
这就形成了「多对多」的「网状模型数据库」(Network Database)。
上面讲的两种数据库,也许你听都没听过。
我们用的,是「关系模型」,而非上面的「层次模型」或者「网状模型」。
为什么?
你会说,这样不方便遍历所有订单。
并不会,再加一个根节点就好:
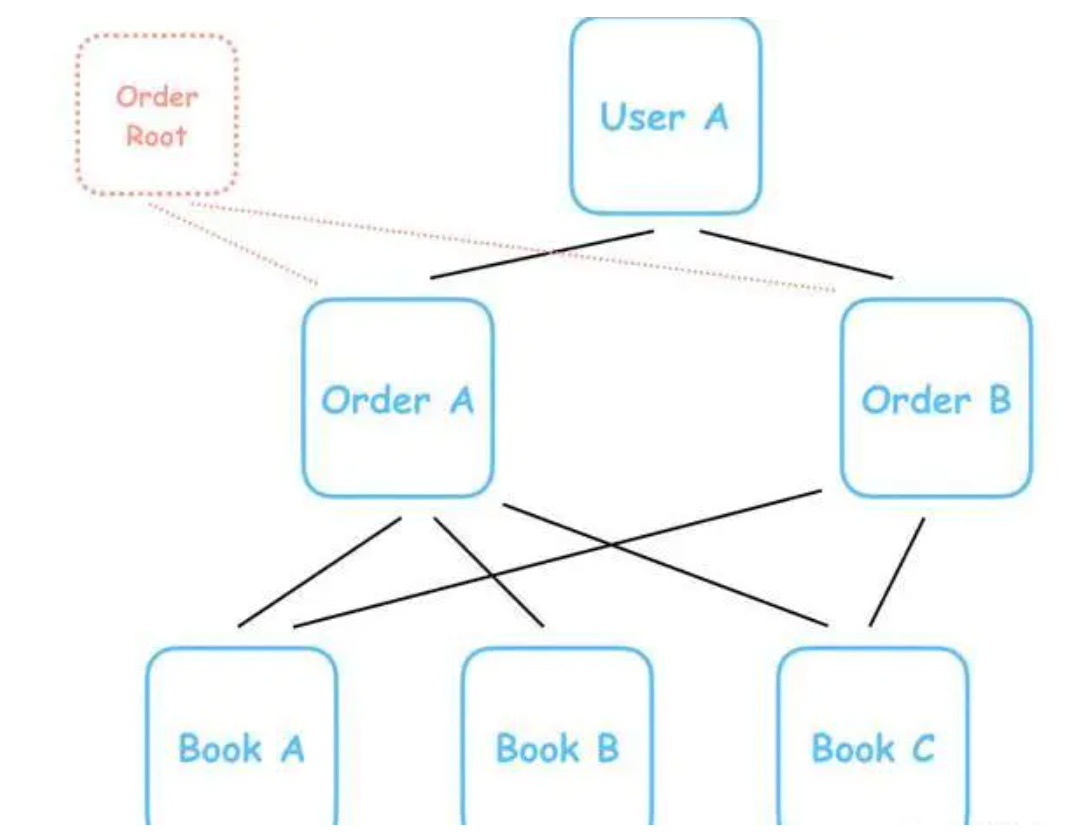
Mysql、MongoDB?如何选择合适的数据库
你会说,这样查找效率很低。
也不会,因为可以优化下数据结构,比如换成 B+ 树。
为什么我们从一开始就在用「关系模型数据库」?
3.0 关系模型数据库
无论是层次模型还是网状模型,程序员看到的,都是实实在在的物理存储结构。
查询时,你要照着里面的数据结构,用对应的算法来查;
插入时,你也要照着数据结构,用对应算法来插入,否则你就破坏了数据的组织结构,数据也就坏掉了。
因为我们都没用过前面两种数据库,所以觉得「关系模型数据库」(以下简称 RDB)的一切都理所当然,但其实,它做出了一个革命性的变革:
用逻辑结构(logical representation of data)代替物理结构(physical representation of data)
所谓「逻辑结构」,也就是我们经常看到的「表格」,User 是一张表格,Order 是一张表格,Book 又是一张表格,它们之间的关系,用 id 来关联,这些 id,可能是 number 类型,也可能是 string 类型:
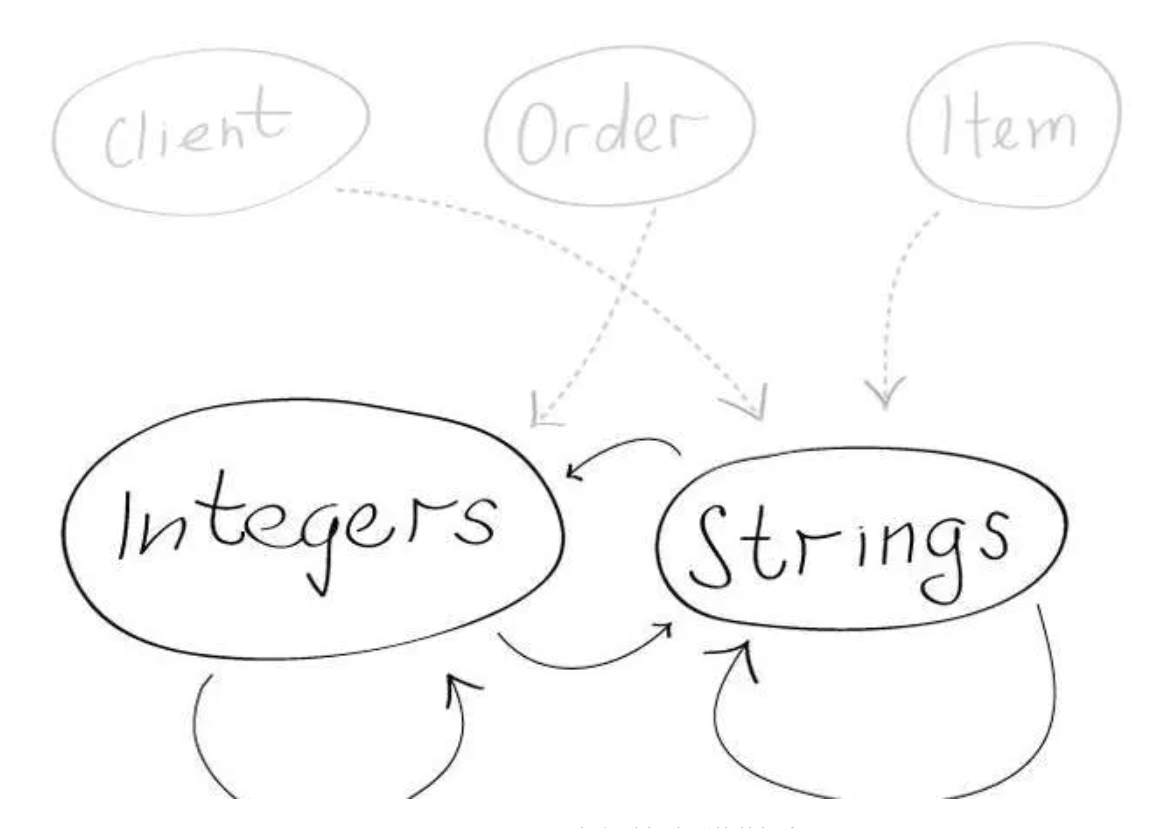
Mysql、MongoDB?如何选择合适的数据库
但你看到的,不一定就是实际的,你看到的只是让你方便理解的「逻辑结构」,真实数据自然不是这样按表格来存储,表格无异于一个数组,数组查询是很慢的。
真实的「物理结构」,也许还是像「层次模型」和「网状模型」一样,是复杂的数据结构。
但到底是怎样的数据结构,你都无需关心,你只需把它想象成一张「表」去操作,就连可视化工具,都会帮你把数据可视化成表,来方便你理解。
这个观念的提出,来自于 1970 年 Codd 的一篇论文,A Relational Model of Data for Large Shared Data Banks:
Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation).
Activities of users at terminals and most application programs should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed.
—— Codd
Codd 的这种思想,其实就是经济学里提到的:分工产生效能。
程序员们不需要直接和物理结构打交道,只负责告诉数据库,他想做什么,至于数据是如何存储、如何索引,都交给数据库,最终他们看到的就是一张张特别直观、特别好理解的 excel 表格。
而数据库则把维护物理结构的复杂逻辑,交给了自己, 对程序员屏蔽了复杂的实现细节。
开发时写的代码少了,耦合性降低了,数据也不容易损坏,也就提高了生产效率(productive)。
一切能用同样的耗能,带来更多效能的技术,都会被广泛使用。
NoSQL
那后来为什么又有了 NoSQL 呢?
在 RDB 被发明的时代,软件多用于大型企业,比如银行、金融等等,人们对数据的要求非常纯粹:准确、可靠、安全,让数据按照期望,正确的写入,不要给老子算错钱就好,于是有了具有 ACID 特性的事务:原子性、一致性、隔离性和持久性。
那时候用网络的人很少,通过终端来访问客户端的人,更少,自然的,数据库的数据量和访问量都跟现在没法比,一台机器,足矣,最多再来个一主多从:
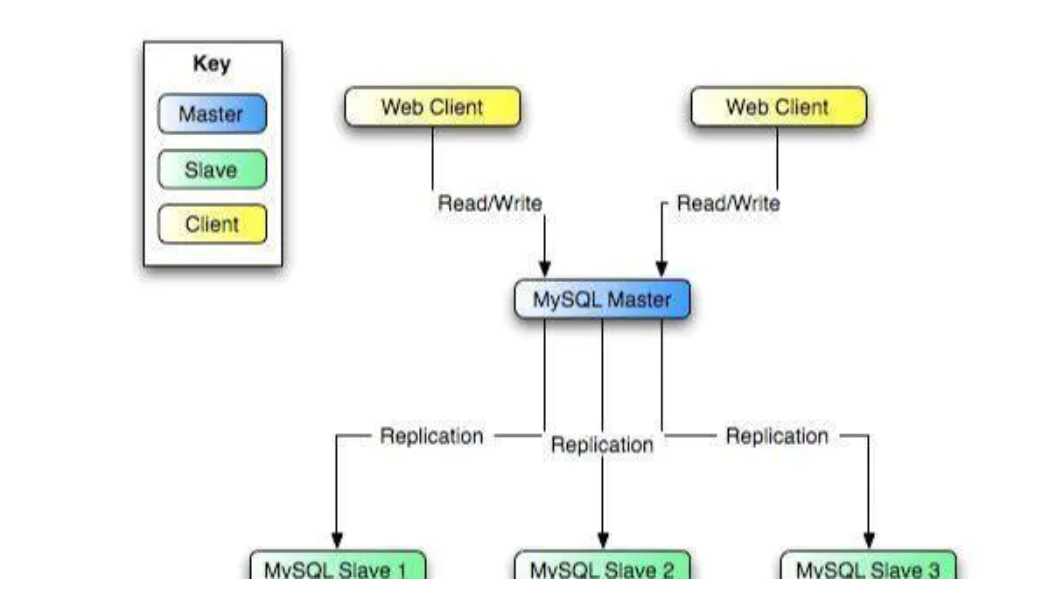
Mysql、MongoDB?如何选择合适的数据库
后来,你知道的,每个人手里都有个手机,每分每秒,都有成千上万的数据,写入你的数据库、从你的数据库被查出,于是有了「分布式」,有了 BASE 和 CAP。这时候,RDB 就会发现,自己之前的那一套 ACID,竟然有点作茧自缚了:
- 为了保证事务的隔离性,要进行加锁,在分布式的环境下,就要对多台机器的数据进行加锁;
- 为了保证事务的原子性,在机器 A 的操作和在机器 B 的操作,要么一起成功,要么一起失败;
- ……
这些都要去不同节点的机器进行通讯和协调,实现起来非常复杂,而且要付出更多的网络 IO,影响性能。
ACID 在分布式系统上实现起来就会变得难以实现,即使实现了,也要付出很大的性能成本,于是才有了后来的各种「分布式一致性协议」,Paxos、Raft、2PC …… 而 Mysql 也提供了各种方案来实现分布式,当然,这些方案自然是很复杂的,比如 「NDB Cluster」 :
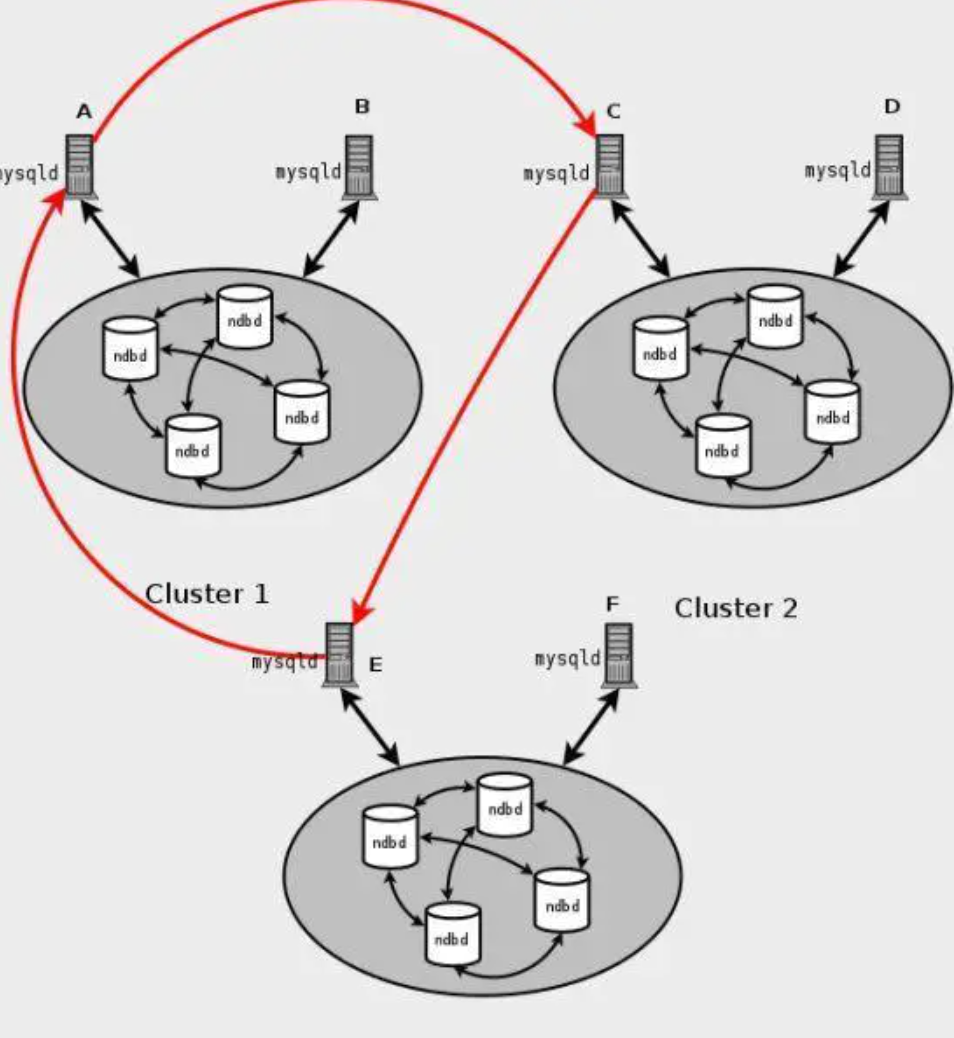
Mysql、MongoDB?如何选择合适的数据库
而 NoSQL 则没有这么多承诺,它的一致性,一般都是最终一致性,当然你可以选择强一致,那自然就要付出点性能作为代价,当然你还可以弱一致,这样会更不安全,但是更快,一切取决于你对数据的要求。
除此之外,RDB 的「数据库范式」(Database Schema),也成了限制扩展性的瓶颈。为了避免数据冗余导致的各种问题(占用空间、删除异常、更新异常等等),我们在设计关系模型时,通常都是按照最小单位来设计的。
什么叫最小单位,比如用户有地址和爱好,那么在正确设计的关系模型(比如 3NF)里,这就是三张表:
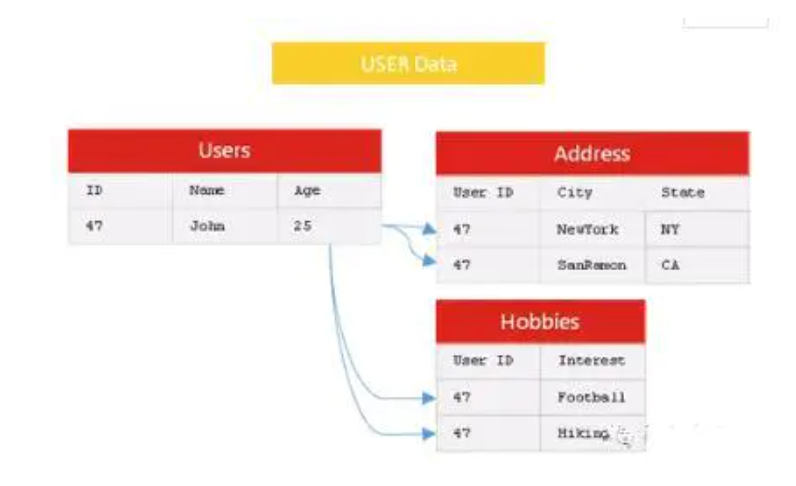
Mysql、MongoDB?如何选择合适的数据库
如果这三张表被分散在不同的机器,那进行关联查询时,就需要多次跨机器的通讯;
而对于 NoSQL,这三类信息,都可以利用 Json 格式的数据,将它们存放在一起:

Mysql、MongoDB?如何选择合适的数据库
完整的存储进去,完整的取出来,不需要额外的操作。
NoSQL 比 RDB 有更强的扩展性,可以充分利用分布式系统来提升读写性能和可靠性。
这不是谁设计好坏的问题,而是跟他们要解决的问题有关:RDB 诞生于互联网萌芽的时代,那时数据的准确、可靠是最重要的,而 NoSQL 诞生于互联网快速发展普及的时代,大数据、分布式、扩展性成了数据库的另一个重要特性。
总结一下:
- RDB 首先得是准确、可靠,然后才向更高的「可拓展性」发展;
- 而 NoSQL 生而分布式,可拓展性强,然后才向更高的「准确性」发展。
NoSQL ,not only SQL,其实就是对那种打破了 RDB 严格事务和关系模型约束的那些数据库的泛指,而随着要解决的问题的不同,又诞生了各种各样的 NoSQL。
首先是「列式数据库」(Column-oriented DBMS),数据量上去了,我们想分析网站用户的年龄分布,简单说,就是你需要对同一个特征进行大数据量的分析统计,于是把原来 RDB 的「按行存储」的范式打破,变成了「按列存储」,比如 HBase;
然后你发现有些数据变动不是很大,但是经常需要被查询, 查询时还要关联很多张表,于是你把这些来自不同表的数据,揉成一个大对象,按 key-value 的格式存起来,比如 Redis;
再后来你需要对博客内容进行相关性搜索,传统 RDB 不支持相关性搜索,最重要的,还是扩展性差,增加机器的带来边际效益有限,于是有了「全文搜索引擎」,比如 Elasticsearch;
除此之外,还有「文档数据库」、「图形数据库」……
没有一种数据库是银弹。
总结
这篇文章的题目是「如何选择数据库」,这是困扰很多人的问题,那么多数据库,到底要选什么好?
可是当你问出这样一个问题时,其实你是在问一种「手段」。我现在要做这样一个需求,用什么数据库可以帮我实现它?
但其实你需要的不只是一种「手段」,因为如果对方甩给你一个冷冰冰的名字,Mysql、Elasticsearch、MongoDB,你肯定会问,凭什么?
你需要的,是一种「解决方案」。如果你需要数据十分严格准确,分毫不差,那我会推荐你采用「事务」和「关系模型」来处理数据;如果你需要数据能够被大量读取和写入,那我会推荐你扩展性强的「分布式」;如果你的数据经常是整个读取、整个更新的,那「关系模型」就没有「文档模型」适合你。
「事务」、「关系模型」、「分布式」、「文档模型」等等,这些就是「解决方案」,知道用什么「解决方案」,用哪个数据库,自然水到渠成。
正如一位大牛说的:
设计实践中,要基于需求、业务驱动架构。无论选用 RDB/NoSQL,一定是以需求为导向,最终数据存储方案必然是各种权衡的综合性设计。
用户不会因为你用了 Mysql 或者 MongoDB 而使用你的软件,毕竟绝大多数用户都不知道 Mysql 和 MongoDB 是什么玩意。












