
1. G1****概览
G1 GC 全称是Garbage First Garbage Collector,垃圾优先垃圾回收器,以下简称G1。G1是HotSpot JVM的短停顿垃圾回收器。其实关于G1的论文早在2004年就有了,但是G1是在2012年4月发布的JDK 7u4中才实现。从长期来说,G1旨在取代CMS(Concurrent Mark Sweep)垃圾回收器。G1从JDK9开始已经作为默认的垃圾回收器。如果对于应用程序来说停顿时间比吞吐量更重要,G1是非常合适的选择。
总体来说G1具有如下特点:
- G1仍旧是分代(年轻代,老年代)的垃圾回收器
- G1实现了两种垃圾回收算法。
- 年轻代垃圾回收具有Stop-The-World,并行,和通过对象复制实现压缩的特点
- 老年代垃圾回收具有并发标记,逐步压缩的特点,并且老年代回收前需要先进行一次年轻代的回收。
2. G1****垃圾回收过程
2.1. G1****垃圾回收过程概述
G1垃圾回收过程主要包括三个:
- 年轻代回收(young gc)过程
- 老年代并发标记(concurrent marking)过程
- 混合回收过程(mixed gc)。
应用程序分配内存,当年轻代的Eden区用尽时开始年轻代回收过程;当堆内存使用达到一定值(默认45%)时,开始老年代并发标记过程;标记完成马上开始混合回收过程。
举个例子:我曾经工作的一个Web服务器,Java进程最大堆内存为4G,每分钟响应1500个请求,每45秒钟会新分配大约2G的内存。G1会每45秒钟进行一次年轻代回收,每31个小时整个堆的使用率会达到45%,会开始老年代并发标记过程,标记完成后开始四到五次的混合回收。
下面将会详细介绍这个三个过程。
2.2. G1****的内存结构
理解垃圾回收机制,必须先了解G1的内存结构,内存结构如下图:
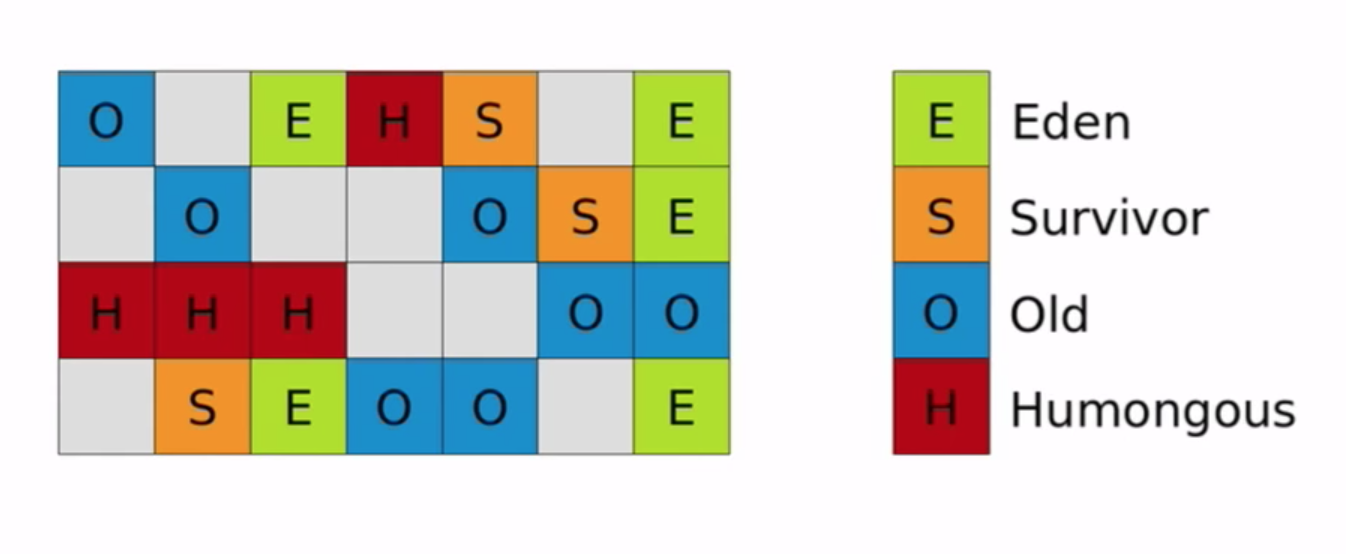
尽管G1堆内存仍然是分代的,但是同一个代的内存不再采用连续的内存结构。这个是如何实现的呢?
这里有三个关于内存的概念:代,区和内存分段。
G1把堆内存分为年轻代和老年代。年轻代分为Eden和Survivor两个区,老年代分为Old和Humongous两个区。代和区都是逻辑概念。
G1把堆内存分为大小相等的内存分段,默认情况下会把内存分为2048个内存分段,可以用-XX:G1HeapRegionSize调整内存分段的个数。比如32G堆内存,2048个内存分段每段的大小为16M。这相当于把内存化整为零。内存分段是物理概念,代表实际的物理内存空间。
每个内存分段都可以被标记为Eden区,Survivor区,Old区,或者Humongous区。这样属于不同代,不同区的内存分段就可以不必是连续内存空间了。
新分配的对象会被分配到Eden区的内存分段上,每一次年轻代的回收过程都会把Eden区存活的对象复制到Survivor区的内存分段上,把Survivor区继续存活的对象年龄加1,如果Survivor区的存活对象年龄达到某个阈值(比如15,可以设置),Survivor区的对象会被复制到Old区。复制过程是把源内存分段中所有存活的对象复制到空的目标内存分段上,复制完成后,源内存分段没有了存活对象,变成了可以使用的空的Eden内存分段了;而目标内存分段的对象都是连续存储的,没有碎片,所以复制过程可以达到内存整理的效果,减少碎片。Humongous区用于保存大对象,如果一个对象占用的空间超过内存分段的一半(比如上面的8M),则此对象将会被分配在Humongous区。如果对象的大小超过一个甚至几个分段的大小,则对象会分配在物理连续的多个Humongous分段上。Humongous对象因为占用内存较大并且连续会被优先回收。
2.3. Remembered Set
理解回收过程,需要先了解记忆集合(Remembered Set),以下简称RS。为了在回收单个内存分段的时候不必对整个堆内存的对象进行扫描(单个内存分段中的对象可能被其他内存分段中的对象引用)引入了RS数据结构。RS使得G1可以在年轻代回收的时候不必去扫描老年代的对象,从而提高了性能。每一个内存分段都对应一个RS,RS保存了来自其他分段内的对象对于此分段的引用。对于属于年轻代的内存分段(Eden和Survivor区的内存分段)来说,RS只保存来自老年代的对象的引用。这是因为年轻代回收是针对全部年轻代的对象的,反正所有年轻代内部的对象引用关系都会被扫描,所以RS不需要保存来自年轻代内部的引用。对于属于老年代分段的RS来说,也只会保存来自老年代的引用,这是因为老年代的回收之前会先进行年轻代的回收,年轻代回收后Eden区变空了,G1会在老年代回收过程中扫描Survivor区到老年代的引用。
RS里的引用信息是怎么样填充和维护的呢?简而言之就是JVM会对应用程序的每一个引用赋值语句object.field=object进行记录和处理,把引用关系更新到RS中。但是这个RS的更新并不是实时的。G1维护了一个Dirty Card Queue。对于应用程序的引用赋值语句object.field=object,JVM会在之前和之后执行特殊的操作以在dirty card queue中入队一个保存了对象引用信息的card。在年轻代回收的时候,G1会对Dirty Card Queue中所有的card进行处理,以更新RS,保证RS实时准确的反映引用关系。那为什么不在引用赋值语句处直接更新RS呢?这是为了性能的需要,RS的处理需要线程同步,开销会很大,使用队列性能会好很多。
2.4. 年轻代回收过程(Young GC****)
JVM启动时,G1先准备好Eden区,程序在运行过程中不断创建对象到Eden区,当所有的Eden区都满了,G1会启动一次年轻代垃圾回收过程。年轻代只会回收Eden区和Survivor区。首先G1停止应用程序的执行(Stop-The-World),G1创建回收集(Collection Set),回收集是指需要被回收的内存分段的集合,年轻代回收过程的回收集包含年轻代Eden区和Survivor区所有的内存分段。然后开始如下回收过程:
第一阶段,扫描根。
根是指static变量指向的对象,正在执行的方法调用链条上的局部变量等。根引用连同RS记录的外部引用作为扫描存活对象的入口。
第二阶段,更新RS。
处理dirty card queue中的card,更新RS。此阶段完成后,RS可以准确的反映老年代对所在的内存分段中对象的引用。
第三阶段,处理RS。
识别被老年代对象指向的Eden中的对象,这些被指向的Eden中的对象被认为是存活的对象。
第四阶段,复制对象。
此阶段,对象树被遍历,Eden区内存段中存活的对象会被复制到Survivor区中空的内存分段,Survivor区内存段中存活的对象如果年龄未达阈值,年龄会加1,达到阀值会被会被复制到Old区中空的内存分段。
第五阶段,处理引用。
处理Soft,Weak,Phantom,Final,JNI Weak 等引用。
2.5. G1老年代并发标记过程(Concurrent Marking)
当整个堆内存(包括老年代和新生代)被占满一定大小的时候(默认是45%,可以通过-XX:InitiatingHeapOccupancyPercent进行设置),老年代回收过程会被启动。具体检测堆内存使用情况的时机是年轻代回收之后或者houmongous对象分配之后。老年代回收包含标记老年代内的对象是否存活的过程,标记过程是和应用程序并发运行的(不需要Stop-The-World)。应用程序会改变指针的指向,并发执行的标记过程怎么能保证标记过程没有问题呢?并发标记过程有一种情形会对存活的对象标记不到。假设有对象A,B和C,一开始的时候B.c=C,A.c=null。当A的对象树先被扫描标记,接下来开始扫描B对象树,此时标记线程被应用程序线程抢占后停下来,应用程序把A.c=C,B.c=null。当标记线程恢复执行的时候C对象已经标记不到了,这时候C对象实际是存活的,这种情形被称作对象丢失。G1解决的方法是在对象引用被设置为空的语句(比如B.c=null)时,把原先指向的对象(C对象)保存到一个队列,代表它可能是存活的。然后会有一个重新标记(Remark)过程处理这些对象,重新标记过程是Stop-The-World的,所以可以保证标记的正确性。上述这种标记方法被称为开始时快照技术(SATB,Snapshot At The Begging)。这种方式会造成某些是垃圾的对象也被当做是存活的,所以G1会使得占用的内存被实际需要的内存大。
具体标记过程如下:
1. 先进行一次年轻代回收过程,这个过程是Stop-The-World的。
老年代的回收基于年轻代的回收(比如需要年轻代回收过程对于根对象的收集,初始的存活对象的标记)。
2. 恢复应用程序线程的执行。
3. 开始老年代对象的标记过程。
此过程是与应用程序线程并发执行的。标记过程会记录弱引用情况,还会计算出每个分段的对象存活数据(比如分段内存活对象所占的百分比)。
4. Stop-The-World。
5. 重新标记(Remark)。
此阶段重新标记前面提到的STAB队列中的对象(例子中的C对象),还会处理弱引用。
6. 回收百分之百为垃圾的内存分段。
注意:不是百分之百为垃圾的内存分段并不会被处理,这些内存分段中的垃圾是在混合回收过程(Mixed GC)中被回收的。
由于Humongous对象会独占整个内存分段,如果Humongous对象变为垃圾,则内存分段百分百为垃圾,所以会在第一时间被回收掉。
7. 恢复应用程序线程的执行。
2.6. 混合回收过程(Mixed GC****)
并发标记过程结束以后,紧跟着就会开始混合回收过程。混合回收的意思是年轻代和老年代会同时被回收。并发标记结束以后,老年代中百分百为垃圾的内存分段被回收了,部分为垃圾的内存分段被计算了出来。默认情况下,这些老年代的内存分段会分8次(可以通过-XX:G1MixedGCCountTarget设置)被回收。混合回收的回收集(Collection Set)包括八分之一的老年代内存分段,Eden区内存分段,Survivor区内存分段。混合回收的算法和年轻代回收的算法完全一样,只是回收集多了老年代的内存分段。具体过程请参考上面的年轻代回收过程。
由于老年代中的内存分段默认分8次回收,G1会优先回收垃圾多的内存分段。垃圾占内存分段比例越高的,越会被先回收。并且有一个阈值会决定内存分段是否被回收,-XX:G1MixedGCLiveThresholdPercent,默认为65%,意思是垃圾占内存分段比例要达到65%才会被回收。如果垃圾占比太低,意味着存活的对象占比高,在复制的时候会花费更多的时间。
混合回收并不一定要进行8次。有一个阈值-XX:G1HeapWastePercent,默认值为10%,意思是允许整个堆内存中有10%的空间被浪费,意味着如果发现可以回收的垃圾占堆内存的比例低于10%,则不再进行混合回收。因为GC会花费很多的时间但是回收到的内存却很少。
2.7. Full GC
Full GC是指上述方式不能正常工作,G1会停止应用程序的执行(Stop-The-World),使用单线程的内存回收算法进行垃圾回收,性能会非常差,应用程序停顿时间会很长。要避免Full GC的发生,一旦发生需要进行调整。什么时候回发生Full GC呢?比如堆内存太小,当G1在复制存活对象的时候没有空的内存分段可用,则会回退到full gc,这种情况可以通过增大内存解决。
3. 其他概念
3.1. 线程本地分配缓冲区(TLAB: Thread Local Allocation Buffer****)
由于堆内存是应用程序共享的,应用程序的多个线程在分配内存的时候需要加锁以进行同步。为了避免加锁,提高性能每一个应用程序的线程会被分配一个TLAB。TLAB中的内存来自于G1年轻代中的内存分段。当对象不是Humongous对象,TLAB也能装的下的时候,对象会被优先分配于创建此对象的线程的TLAB中。这样分配会很快,因为TLAB隶属于线程,所以不需要加锁。
3.2. GC“提升”线程本地分配缓冲区(PLAB: Promotion Thread Local Allocation Buffer)
前面提到过,G1会在年轻代回收过程中把Eden区中的对象复制(“提升”)到Survivor区中,Survivor区中的对象复制到Old区中。G1的回收过程是多线程执行的,为了避免多个线程往同一个内存分段进行复制,那么复制的过程也需要加锁。为了避免加锁,G1的每个线程都关联了一个PLAB,这样就不需要进行加锁了。
3.3. Remembered Set 粒度
其实RS的存储分三种粒度,前面提到的Card是最小的一种粒度。粒度的存在是因为某些内存分段中的对象可能很热门,被来自非常多的区的对象所引用,为了避免保存太多的数据,会以更大的粒度来保存这些引用,比如最大的粒度是用一个bitmap来保存其他内存分段对RS所对应的内存分段的引用。每一个内存分段对应一个bit,如果bit为0表示该bit对应的内存分段中没有引用,为1表示有引用。这种方式会减少RS的数据,但是会增加扫描和标记时的开销,因为需要扫描所有bit为1的内存分段中的对象以确定具体是来自哪个对象的引用。
后续文章会分析G1 GC的日志,介绍常见的G1 GC性能问题和常用的G1 GC参数调优。
作者公众号(码年)****扫码关注:

参考文献:
G1 Garbage Collector Details and Tuning (Simone Bordet)
Java Performance Companion (Charlie Hunt, Monica Beckwith, Poonam Parhar, Bengt Rutisson












