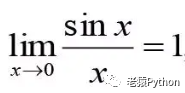资料获取地址见文末或评论!
一、预备知识
微积分(偏导数、梯度等等) 概率论与数理统计(例如极大似然估计、中央极限定理、大数法则等等) 最优化方法(比如梯度下降、牛顿-拉普什方法、变分法(欧拉-拉格朗日方程)、凸优化等等)
二、路线1
(基于普通最小二乘法的)简单线性回归 -> 线性回归中的新进展(岭回归和LASSO回归)->(此处可以插入Bagging和AdaBoost的内容)-> Logistic回归 ->支持向量机(SVM)->感知机学习 -> 神经网络(初学者可先主要关注BP算法)-> 深度学习 这些算法都是围绕着 y = Σxiβi 这个公式展开的。 其中蓝色部分主要是回归,绿色部分主要是有监督的分类学习法。
三、路线2
K-means -> EM -> 朴素贝叶斯 贝叶斯网络 -> 隐马尔科夫模型(基本模型,前向算法,维特比算法,前向-后向算法) (->卡尔曼滤波) 这条线路所涉及的基本都是那些各种画来画去的图模型,学术名词是PGM。这条线的思路和第一条是截然不同的。 其中绿色字体的部分是这个线路中的核心内容,而蓝色部分是为绿色内容作准备的部分。 K-means和EM具有与生俱来的联系,认识到这一点才能说明真正读懂了它们。而EM算法在HMM的模型训练中用到,所以要先学EM才能深入学习HMM。所以尽管在EM中看不到那种画来画去的图模型,但我还把它放在了这条线路中,这也就是原因所在。 朴素贝叶斯里面的很多内容在贝叶斯网络和HMM里都会用到,类似贝叶斯定理、先验和后验概率,边缘分布等等(主要是概念性的)。 最后,卡尔曼滤波可以作为HMM的一直深入或者后续扩展。尽管很多machine learning的书里没有把它看做是一种机器学习算法,但它也确实可以被看成是一种机器学习技术。 了解一些基础的学习理论 依次掌握各种常见的分类算法的原理与案例应用 掌握回归分析技术 掌握常见聚类算法的原理与案例应用 掌握常见关联分析算法的原理与案例应用 掌握各种常见的进阶模块与使用 掌握文本挖掘技术与常见案例应用 尝试自己写一些机器学习算法 学习深度学习技术,掌握各种神经网络算法与实际应用
四、应用层面
R、MATLAB和Python都是做数据挖掘的利器. 另一个基于Java的免费数据挖掘工具是Weka,只用点点鼠标,甚至不用编代码了。
五、机器学习可以解决的一些问题
1.分类
根据数据样本抽取出的特征,判定其属于有限个类别中的哪一个。如: 垃圾邮件识别(垃圾邮件、正常邮件) 文本情感褒贬分析(褒、贬) 图像内容识别(结果类别:喵星人、汪星人、人类) 图片分类、商品分类、客户分类、公司融资成功概率预测
2.回归问题
根据数据样本上抽取出的特征,预测一个连续值的结果,如: 票房预测 房价预测 趋势预测
3.聚类问题
根据数据样本上抽取出的特征,让相近/相关的样本在一团内。如 google的新闻分类 用户群体划分 商品聚类 公司客户价值分析
4. 关联分析问题
商品关联分析 个性化推荐 货品摆放调整指导
5. 文本挖掘问题
文本相似度计算 机器翻译 聊天机器人
6. 预测决策
下棋
7. 目标检测
目标检测
六、机器学习最典型的两个分类
1.监督学习 分类与回归问题需要用已知结果的数据做训练,属于“监督学习”。 2.非监督学习 聚类的问题不需要已知标签,属于“非监督学习”。
七、机器学习热点应用
1.计算机视觉 典型的应用包括:人脸识别、车牌识别、扫描文字识别、图片内容识别、图片搜索等。 2.自然语言处理 典型的应用包括:搜索引擎智能匹配、文本内容理解、文本情绪判断,语音识别、输入法、机器翻译等。 3.社会网络分析 典型的应用包括:用户画像、网络关联分析、欺诈作弊发现、热点发现等。 4.推荐 典型的应用:虾米音乐的“歌曲推荐”,某宝的“猜你喜欢”等。
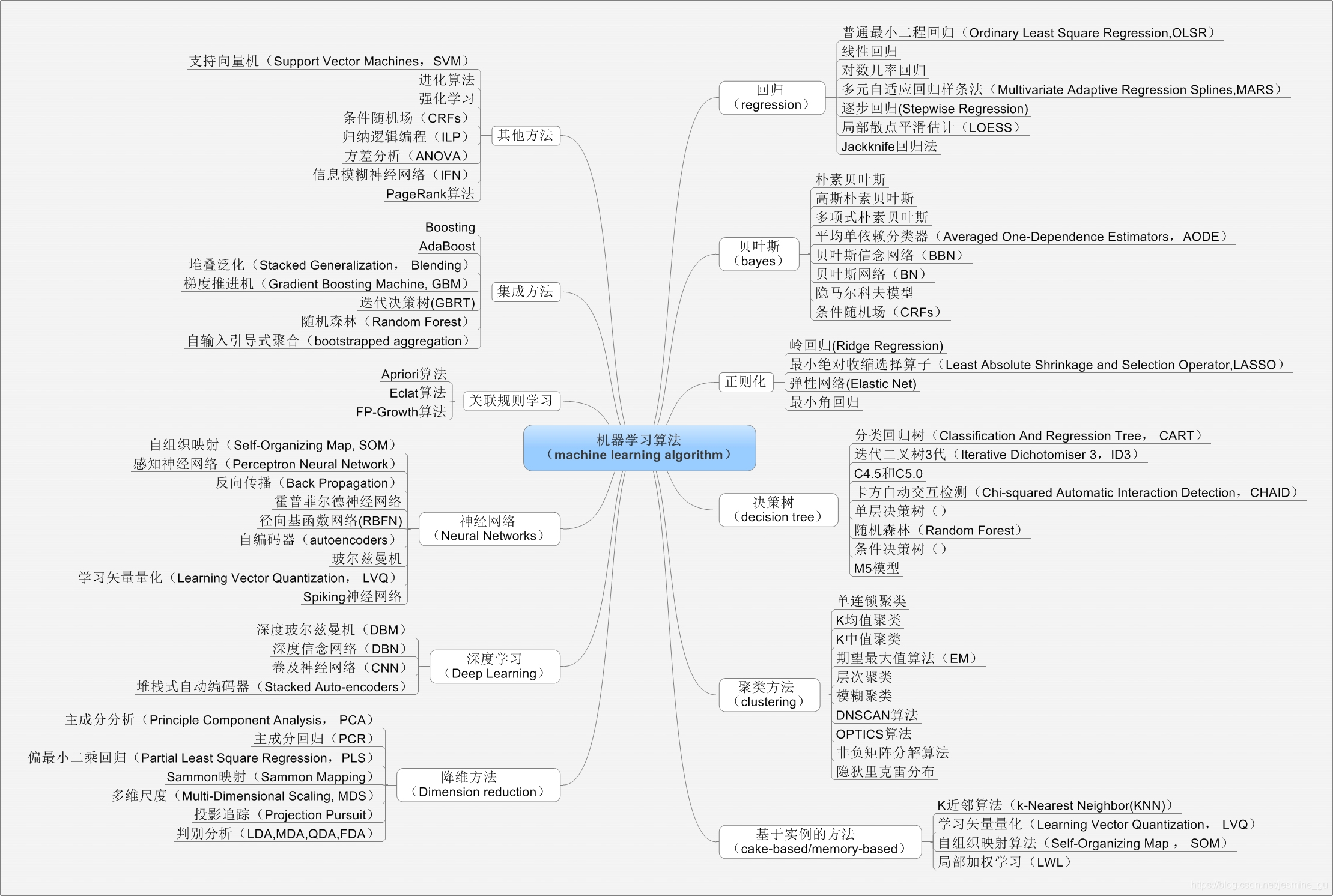
八、典型算法
处理分类的常用算法 逻辑回归 支持向量机 随机森林 朴素贝叶斯(NLP中常用) 深度神经网络(视频、图片、语音等多媒体数据中使用) 处理回归问题的常用算法 线性回归 普通最小二乘法回归(Ordinary Least Squares Regression) 逐步回归(Stepwise Regression) 多元自适应回归样条(Multivariate Adaptive Regression Splines) 处理聚类问题的常用算法 K均值(K-means) 基于密度聚类 LDA等 降维的常用算法 协同过滤算法 模型整合(model ensemble)和提升(boostring)的算法 bagging adaboost GBDT GBRT 其它重要的算法 EM算法
九、编程语言、工具和环境
1.Python PyTorch:Torch的Python版本,深度神经网络工具 网页爬虫:Scrapy 数据挖掘: -- Pandas:模拟R,进行数据浏览与预处理 -- numpy:数组运算 -- scipy:高效的科学计算 -- matplotlib:非常方便的数据可视化工具 机器学习 -- Scikit-learn:远近闻名的机器学习包。 -- libsvn:高效率的SVM模型实现 -- keras/TensorFlow:深度学习神经网络。 自然语言处理 -- nltk:自然语言处理的相关功能做得非常全面,有典型语料库,上手也非常容易。 -- ipython notebook:能直接打通数据到结果的通道。 2.R 最大的优势是开源社区,聚集了非常多功能强大可直接使用的包,绝大多数的机器学习算法在R中都有完善的包可直接使用,同时文档也非常齐全。常见的package包括: RGtk2 pmml colorspace ada amap arules biclust cba descr doBy e1071 ellipse等。 另外R的可视化效果做得也很好 3.Java WEKA Machine Learning Workbench:相当于Java的scikit-learn Massive Online Analysis(MOA) MEKA Mallet 4.C++ mlpack:高效同时可扩充性非常好的机器学习库 Shark:文档齐全的老牌C++机器学习库 5.大数据相关 Hadoop Spark 6.操作系统 mac linux Windows下推荐anaconda,一步到位安装完python的全品类数据科学工具包。
十、基本工作流程
1.抽象成数据问题 目标是一个分类还是回归或聚类的问题,等。 2.获取数据 3.特征预处理与特征选择 良好的数据要能够提取出良好的特征才能真正发挥效力。 特征预处理,数据清洗是关键的步骤,往往能够使得算法的效果和性能得到显著提高。归一化、离散化、因子化、缺失值处理、去除共线性等,数据挖掘过程中很多时间就花在它们上面。 这些工作简单可复制,是机器学习的基础必备步骤。 筛选出显著特征,摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。 4.训练模型与调优 真正考验水平的是调整算法的(超)参数,使得结果变得更加优良。这需要我们对算法的原理有深入的理解。理解越深入,就越能发现问题的症结,提出良好的调优方案。 5.模型诊断 如何确定模型调优的方向与思路?这就需要对模型进行诊断的技术。 过拟合、欠拟合 判断是模型诊断中至关重要的一步。常见的方法如交叉验证,绘制学习曲线等。 过拟合的基本调优思路是增加数据量,降低模型复杂度。 欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。 误差分析也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生的原因,是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题。 6.模型融合 7.上线运行
十一、常用的科学计算软件
Matlab GNU Octave Mathematica Maple Spss R Numpy,SciPy,matplotlib等Python科学计算平台 OpenCV 是 Intel开源计算机视觉库,它由一系列C函数和少量C++类构成,实现了图像处理和计算机视觉方面的很多通用算法。OpenCV拥有包括300多个C函数的跨平台的中高层API。它不依赖于其他的外部库(尽管也可以使用某些外部库)。 mply是基于NumPY/SciPy和GSL构建的Python模块,它提供了高层函数和类,允许使用少量代码来完成复杂的分类、特征提取、回归、聚类等任务。 BeautifulSoup是用Python写的一个HTML/XML的解析器。 Neurolab是Python神经网络库,包括基础神经网络、训练算法,并具有弹性的构架,可创建其他网络,它用纯Python和Numpy写成。
docs.qq.com/doc/DUkVNRUFXc1Z1THFz , 复制后浏览器打开获取地址