Python在近几年迅速咋程序界掀起了不小的波澜,而关于python的第三库也使广大程序员趋之若鹜,今天我们就由浅入深的探讨一下如何使用python做一个“网络爬虫”来抓取一些页面信息。今天我们使用的库(包含python自身携带的库和第三库)
Python简介
Python(英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。
Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议[2] 。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。
Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中[3] 有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。
网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
例子中设计的库
-
URLLIB
Python 3 的 urllib 模块是一堆可以处理 URL 的组件集合。如果你有 Python 2 的知识,那么你就会注意到 Python 2 中有 urllib 和 urllib2 两个版本的模块。这些现在都是 Python 3 的 urllib 包的一部分。当前版本的 urllib 包括下面几部分:urllib.request urllib.error urllib.parse urllib.rebotparser。 BeautifulSoup
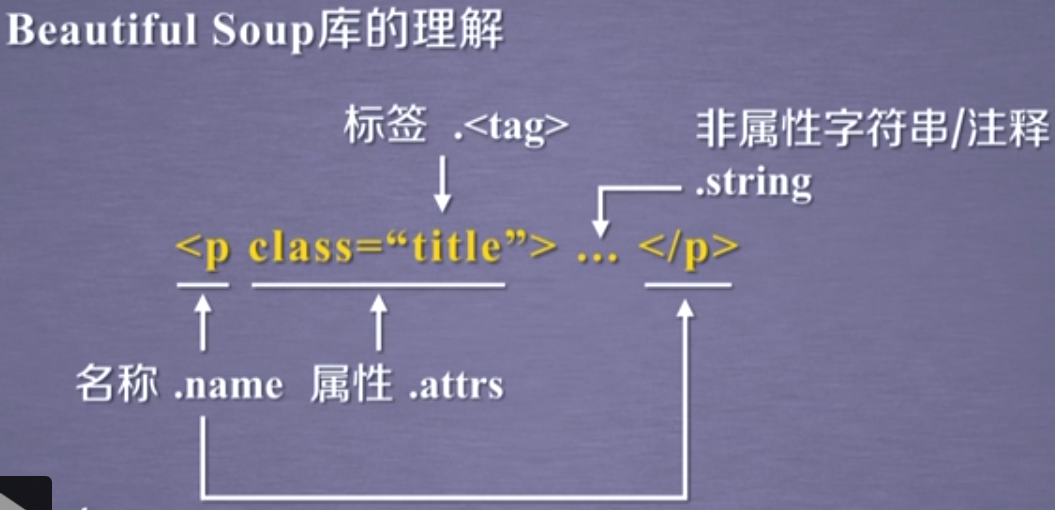
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
如何使用Urllib
#-*- coding: utf-8 -*-
#导入urllib库中的request
from urllib import request
#使用request的Request方法,括号中的参数为你想爬取的网址地址
req = request.Request("http://www.baidu.com")
#使用req的add_header方法向其中添加一些参数以使得你的爬虫看起来像一个普通的HTTP访问,这个你可以使用浏览器的开发者工具中查到,例如在谷歌浏览器中,打开你想爬取的网页,按F12,截图如下:
![图片描述][1]
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36")
#获取所需爬取网站的信息
resp = request.urlopen(req)
#打印该信息
print(resp.read().decode("utf-8"))
使用Urllib和BeautifulSoup爬取维基网站首页的链接信息
安装Beautifulsoup
在此我提供使用pip命令行来安装 ,pip install BeautifulSoup.或者可以参考一下博客也可,博客连接:
[链接描述][1][1]: http://blog.csdn.net/jenyzhang/article/details/45828481
-
具体实现(非常简单)
#-- coding: utf-8 -#
#引入开发包
from urllib.request import Request
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
#请求URL,并把URL用UTF-8编码
resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().decode("utf-8")
#使用BeautifulSoup去解析
soup = BeautifulSoup(resp,"html.parser")
#去获取所有以/wiki/开头的a标签的href属性
listUrls = soup.findAll("a",href=re.compile("^/wiki/"))
for url in listUrls:#使用正则表达式来筛选出后缀名为.jpg或者.JPG的连接 if not re.search("\.(jpg|JPG)$",url["href"]): #打印所爬取的信息 print(url.get_text(),"<---->","https://en.wikipedia.org",url["href"])
最后附上项目的源码地址,当然其中还有一些关于urllib和beautifusoup 以及如何将信息存储在mysql的联系,大家有兴趣的可以看一下。
链接:http://pan.baidu.com/s/1pLiePCn 密码:mh4t