
转自:https://blog.csdn.net/u012706811/article/details/77096257
函数式接口
函数式接口,对于Java来说就是接口内只有一个公开方法的接口,因为使用lanbda表达式,例如() -> user.getName()对应的调用则可能是func.get(),编译器会根据接口推断所属于的方法,如果有两个则无法推断.Java8提供了很多函数式接口,一般都使用注解@FunctionalInterface声明,有必要了解如下一些函数式接口.
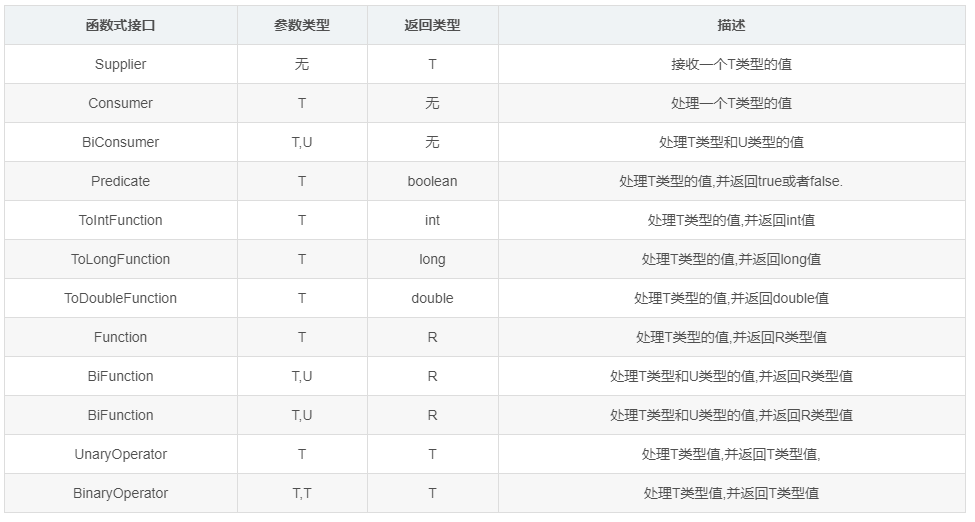
以上的函数每一个代表的都是一种基本的操作,操作之间可以自由组合,所以才有了stream这些灵活的操作.
Stream操作
Stream的操作是建立在函数式接口的组合上的,最好的学习方法是看Stream接口来学习.下面举一些例子来分析,假设有这样的一些初始数据.
List
testData.add("张三");
testData.add("李四");
testData.add("王二");
testData.add("麻子");
filter
Stream
filter接收predicate函数,predicate是接收T值,返回boolean值,那么对应的引用就可以写成如下形式,意思是取集合中以’张’开头的名字.
testData.stream()
.filter(x -> x.startsWith("张"))
map
map操作接收的是Function接口,对于Function接收T值返回R值,那map的作用就很明显是转换用的,比如下面代码,转换名称为对应的名称长度,也就是从输入String数据返回int数据.
testData.stream()
.map(x -> x.length())
flatMap
flatMap和map都是使用Function接口,不同的是返回值flatMap限定为Stream类型.所以flatMap可以作为合并流使用,如以下代码,提取出所有的字符.
testData.stream()
.flatMap(x -> Stream.of(x.split("")))
.collect(Collectors.toList());
//输出 [张, 三, 李, 四, 王, 二, 麻, 子]
peek
Stream
peek参数为Consumer,Consumer接收T值,无返回,那么该方法就可以作为调试不影响stream中内容的一些操作,不过由于对象都是地址引用,你再此做一些对象内容操作也是可以的.
reduce
U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator combiner);
Reduce比较复杂的一个接口,属于归纳性操作,看参数,第一个是U泛型,也就是输入类型的参数,最为初始值,第二个BiFunction,接收T,U参数,返回U类型参数,BinaryOperator接收U,U类型,并返回U类型.
StringBuilder identity = new StringBuilder();
StringBuilder reduce = testData.stream()
.flatMap(x -> Stream.of(x.split("")))
.reduce(identity, (r, x) -> {
r.append(x);
return r;
}, StringBuilder::append);
System.out.println(identity == reduce);
System.out.println(reduce.toString());
//输出 true
// 张三李四王二麻子
首先提供一个基本容器identity,然后两个参数r即是identity,x为每次输入参数,最后一个StringBuilder::append是并发下多个identity的合并策略.
再举个例子,既然reduce属于归纳性操作,那么也可以当成collect使用,如下:
ArrayList
ArrayList
.flatMap(x -> Stream.of(x.split("")))
.reduce(identity, (r, x) -> {
r.add(x);
return r;
},(r1,r2) -> {
r1.addAll(r2);
return r1;
});
System.out.println(identity == result);
System.out.println(result);
//输出 true
//[张, 三, 李, 四, 王, 二, 麻, 子]
强大的collect
collect无疑是stream中最强大的操作,掌握了collect操作才能说掌握了stream.为了便于使用者,Java提供了Collectors类,该类提供了很多便捷的collect操作,如Collector<T, ?, List
CollectorImpl(Supplier supplier,
BiConsumer<A, T> accumulator,
BinaryOperator combiner,
Function<A,R> finisher,
Set
this.supplier = supplier;
this.accumulator = accumulator;
this.combiner = combiner;
this.finisher = finisher;
this.characteristics = characteristics;
}
Supplier类似reduce中的u,接收一个元数据,BiConsumer则是操作数据,BinaryOperator并发下聚合,finisher完成时的转换操作,Set应该按照定义是优化一些操作中的转换.如下面的toList()操作,其finish操作为castingIdentity().
public static
Collector<T, ?, List
return new CollectorImpl<>((Supplier<List
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
再看toMap的实现
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator mergeFunction,
Supplier
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}
Function作为转换函数提供了key和value的转换,BinaryOperator提供了重复key合并策略,mapSupplier则表示最终收集到的容器.那么使用就很简单了
HashMap<Character, String> map = testData.stream()
.collect(Collectors.toMap(x -> x.charAt(0), Function.identity()
, (v1, v2) -> v2, HashMap::new)); //Function.identity()等价于o->o









