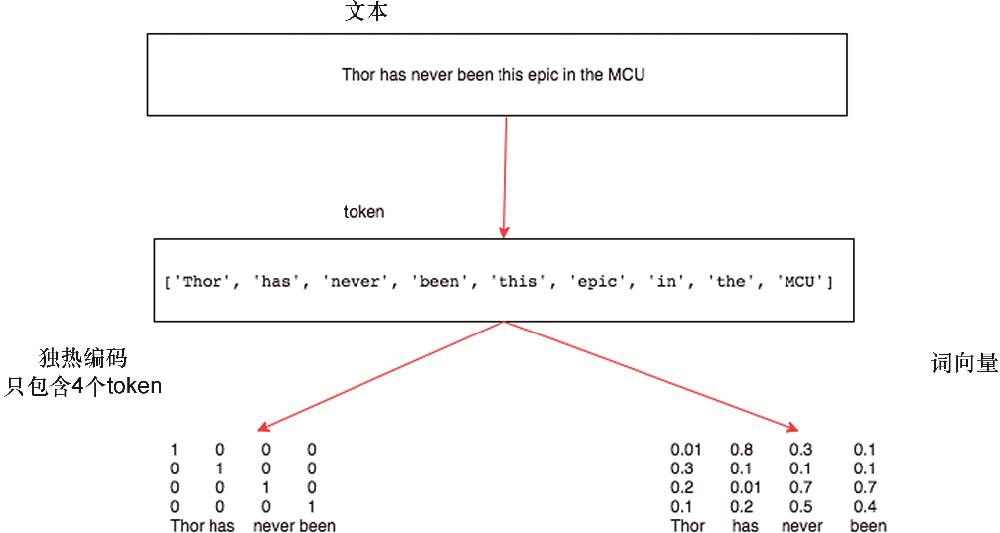
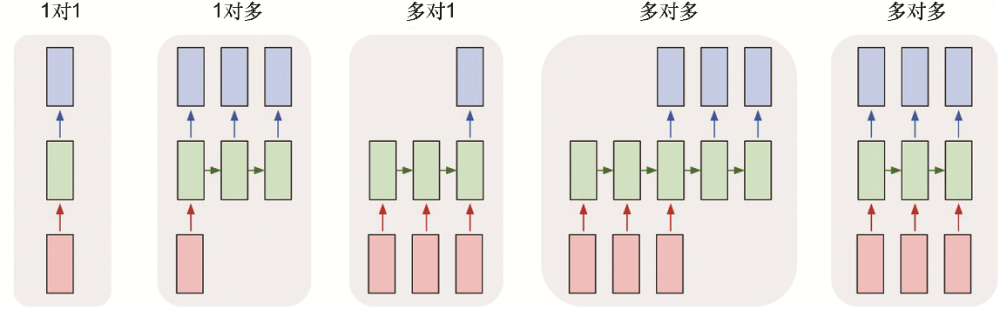
Seq2Seq模型主要在NLP,机器翻译,序列预测等问题上效果显著。
一般情况下可以分解Seq2Seq模型为两个子模型:Encoder和Decoder。
- Encoder的输入为原始的序列数据,输出为通过NN泛化的表征Tensor(常规操作);此output便是Decoder的input。通过Encoder进行编码的raw data,再通过Decoder进行解码为另外完全不同的output(例如:英文到中文的转换)
那么在构建这样一个Seq2Seq模型需要哪几步呢?
1. 定义Encoder模型中的数据输入参数
encoder_decoder_model_inputs创建并返回与模型相关的参数(tf占位符)
def enc_dec_model_inputs():
inputs = tf.placeholder(tf.int32, [None, None], name='input')
targets = tf.placeholder(tf.int32, [None, None], name='targets')
target_sequence_length = tf.placeholder(tf.int32, [None], name='target_sequence_length')
max_target_len = tf.reduce_max(target_sequence_length)
return inputs, targets, target_sequence_length, max_target_len- inputs占位符为了接收原始英文句子,shape==(None,None)分别表示batch size和句子长度。这里有个小trick,不同batch中句子的长度可能是不同的,所以不能设置为固定长度。通用解决方法是设置每一个batch中最长的句子长度为最大长度(必须通过Padding补齐)。
- targets占位符接收原始中文句子
- target_sequence_length占位符表示每个句子的长度,shape为None,是列张量,与批处理大小相同。该特定值是与后面的TrainerHelper的参数,用于构建用于训练的解码器模型。
- max_target_len是指从所有目标句子(序列)的长度中获取最大值。target_sequence_length参数中包含所有句子的长度。从中获取最大值的方法是使用tf.reduce_max。
2.建立Decoder模型
编码模型由两个不同部分组成。第一部分是嵌入层;句子中的每个单词都将使用指定为encoding_embedding_size来泛化。这一层对文字信息压缩编码表示。第二部分是RNN层。在此实践中,在应用embedding之后,多个LSTM单元被堆叠在一起。当然可以使用不同种类的RNN单元,例如GRU。
def encoding_layer(rnn_inputs, rnn_size, num_layers, keep_prob,
source_vocab_size,
encoding_embedding_size):
"""
:return: tuple (RNN output, RNN state)
"""
embed = tf.contrib.layers.embed_sequence(rnn_inputs,
vocab_size=source_vocab_size, embed_dim=encoding_embedding_size)
stacked_cells = tf.contrib.rnn.MultiRNNCell([tf.contrib.rnn.DropoutWrapper(tf.contrib.rnn.LSTMCell(rnn_size), keep_prob) for _ in range(num_layers)])
outputs, state = tf.nn.dynamic_rnn(stacked_cells,
embed, dtype=tf.float32)
return outputs, state- embedding layer:tf.keras.layers.Embedding
RNN layer:
- TF contrib.rnn.LSTMCell 描述存在多少个内在神经元节点
- TF contrib.rnn.DropoutWrapper 加入dropout参数
- TF contrib.rnn.MultiRNNCell 连接多个RNN cell
- Encoder model:TF nn.dynamic_rnn 组合embedding层与RNN层
3.定义Decoder模型中的数据输入参数
对于Decoder中的训练和推理,需要不同的输入。在训练过程中,输入由embedded后的目标label提供;在推理阶段,每个时间步的输出将是下一时间步的输入。它们也需要embedding,并且embedded向量应在两个不同的阶段之间共享。
- 那么训练过程中 如何让模型知道接下来就是target label呢? 答案是在target label之前加入标识符。如下:
def process_decoder_input(target_data, target_vocab_to_int, batch_size):
# get '<GO>' id
go_id = target_vocab_to_int['<GO>']
after_slice = tf.strided_slice(target_data, [0, 0], [batch_size, -1], [1, 1])
after_concat = tf.concat( [tf.fill([batch_size, 1], go_id), after_slice], 1)
return after_concat4.建立Decoder模型中的训练部分
解码模型可以考虑两个独立的过程,即训练和推理。不是它们具有不同的体系结构,而是它们共享相同的体系结构及其参数。他们有不同的策略来提供共享模型。
虽然编码器使用tf.contrib.layers.embed_sequence,但它可能不适用于解码器,就算需要embedded其输入。那是因为应该通过训练和推断阶段来共享相同的embedded向量。 tf.contrib.layers.embed_sequence只能在运行之前embedded准备好的数据集。推理过程所需的是动态embedded功能。在运行模型之前,不可能嵌入推理过程的输出,因为当前时间步的输出将是下一时间步的输入。
那么到底在推理过程中是如何嵌入的?下一节将会讲到。需要记住的是训练和推理过程共享相同的嵌入参数。对于培训部分,应提供嵌入的输入。在推断部分,仅传递训练部分中使用的嵌入参数。
def decoding_layer_train(encoder_state, dec_cell, dec_embed_input,
target_sequence_length, max_summary_length,
output_layer, keep_prob):
"""
Create a training process in decoding layer
:return: BasicDecoderOutput containing training logits and sample_id
"""
dec_cell = tf.contrib.rnn.DropoutWrapper(dec_cell,
output_keep_prob=keep_prob)
# for only input layer
helper = tf.contrib.seq2seq.TrainingHelper(dec_embed_input,
target_sequence_length)
decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
helper,
encoder_state,
output_layer)
# unrolling the decoder layer
outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(decoder,
impute_finished=True,
maximum_iterations=max_summary_length)
return outputs- tf.contrib.seq2seq.TrainingHelper:TrainingHelper是用来传递embedded输入参数的。顾名思义,这只是一个helper实例。该实例由BasicDecoder调用,这就是构建解码器模型的实际流程。
- tf.contrib.seq2seq.BasicDecoder:BasicDecoder构建解码器模型。这意味着它将解码器端的RNN层与TrainingHelper准备的输入连接起来。
- tf.contrib.seq2seq.dynamic_decode:dynamic_decode展开解码器模型,以便BasicDecoder可以针对每个时间步长检索实际预测。
5. 建立decoder模型中的推理部分
- tf.contrib.seq2seq.GreedyEmbeddingHelper::GreedyEmbeddingHelper动态获取当前步骤的输出,并将其提供给下一个步骤的输入。为了动态地嵌入每个输入结果,应提供嵌入参数(只是一堆权重值)。同时,GreedyEmbeddingHelper要求提供与批处理大小和end_of_sequence_id相同数量的start_of_sequence_id。
def decoding_layer_infer(encoder_state, dec_cell, dec_embeddings, start_of_sequence_id,
end_of_sequence_id, max_target_sequence_length,
vocab_size, output_layer, batch_size, keep_prob):
"""
Create a inference process in decoding layer
:return: BasicDecoderOutput containing inference logits and sample_id
"""
dec_cell = tf.contrib.rnn.DropoutWrapper(dec_cell,
output_keep_prob=keep_prob)
helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(dec_embeddings,
tf.fill([batch_size], start_of_sequence_id),
end_of_sequence_id)
decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell,
helper,
encoder_state,
output_layer)
outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(decoder,
impute_finished=True,
maximum_iterations=max_target_sequence_length)
return outputs6.建立Decoder layer
6.1. Embed the target sequences
- tf.contrib.layers.embed_sequence:创建嵌入参数的内部表示,因此我们无法调查或检索它。相反,您需要通过TF Variable手动创建嵌入参数。
- 手动创建的嵌入参数用于训练阶段,在运行训练之前通过TF nn.embedding_lookup转换提供的目标数据(句子序列)。带有手动创建的嵌入参数的TF nn.embedding_lookup返回的结果与TF contrib.layers.embed_sequence相似。对于推理过程,每当通过解码器计算当前时间步的输出时,它将被共享的嵌入参数嵌入,并成为下一个时间步的输入。您只需要向GreedyEmbeddingHelper提供embedding参数,将对处理过程有所帮助。
- tf.nn.embedding_lookup:简而言之,检索出符合指定行。
- 关于tf.variable_scope相关,请查看此链接
6.2 Construct the decoder RNN layer(s)
Decoder与Encoder中RNN的层数必须一致
6.3 创建一个输出层以将解码器的输出映射到我们词汇表的元素
全连接层以获取每个单词最后出现的概率。
def decoding_layer(dec_input, encoder_state,
target_sequence_length, max_target_sequence_length,
rnn_size,num_layers, target_vocab_to_int, target_vocab_size,
batch_size, keep_prob, decoding_embedding_size):
"""
Create decoding layer
:return: Tuple of (Training BasicDecoderOutput, Inference BasicDecoderOutput)
"""
target_vocab_size = len(target_vocab_to_int)
dec_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size]))
dec_embed_input = tf.nn.embedding_lookup(dec_embeddings, dec_input)
cells = tf.contrib.rnn.MultiRNNCell([tf.contrib.rnn.LSTMCell(rnn_size) for _ in range(num_layers)])
with tf.variable_scope("decode"):
output_layer = tf.layers.Dense(target_vocab_size)
train_output = decoding_layer_train(encoder_state,
cells,
dec_embed_input,
target_sequence_length,
max_target_sequence_length,
output_layer,
keep_prob)
with tf.variable_scope("decode", reuse=True):
infer_output = decoding_layer_infer(encoder_state,
cells,
dec_embeddings,
target_vocab_to_int['<GO>'],
target_vocab_to_int['<EOS>'],
max_target_sequence_length,
target_vocab_size,
output_layer,
batch_size,
keep_prob)
return (train_output, infer_output)7.建立Seq2Seq模型
最终,encoding_layer, process_decoder_input, and decoding_layer等函数组合起来建立Seq2Seq模型。
def seq2seq_model(input_data, target_data, keep_prob, batch_size,
target_sequence_length,
max_target_sentence_length,
source_vocab_size, target_vocab_size,
enc_embedding_size, dec_embedding_size,
rnn_size, num_layers, target_vocab_to_int):
"""
Build the Sequence-to-Sequence model
:return: Tuple of (Training BasicDecoderOutput, Inference BasicDecoderOutput)
"""
enc_outputs, enc_states = encoding_layer(input_data,
rnn_size,
num_layers,
keep_prob,
source_vocab_size,
enc_embedding_size)
dec_input = process_decoder_input(target_data,
target_vocab_to_int,
batch_size)
train_output, infer_output = decoding_layer(dec_input,
enc_states,
target_sequence_length,
max_target_sentence_length,
rnn_size,
num_layers,
target_vocab_to_int,
target_vocab_size,
batch_size,
keep_prob,
dec_embedding_size)
return train_output, infer_output8.建立静态图,loss函数,优化器,梯度裁剪(RNN网络必加)
save_path = 'checkpoints/dev'
(source_int_text, target_int_text), (source_vocab_to_int, target_vocab_to_int), _ = load_preprocess()
max_target_sentence_length = max([len(sentence) for sentence in source_int_text])
train_graph = tf.Graph()
with train_graph.as_default():
input_data, targets, target_sequence_length, max_target_sequence_length = enc_dec_model_inputs()
lr, keep_prob = hyperparam_inputs()
train_logits, inference_logits = seq2seq_model(tf.reverse(input_data, [-1]),
targets,
keep_prob,
batch_size,
target_sequence_length,
max_target_sequence_length,
len(source_vocab_to_int),
len(target_vocab_to_int),
encoding_embedding_size,
decoding_embedding_size,
rnn_size,
num_layers,
target_vocab_to_int)
training_logits = tf.identity(train_logits.rnn_output, name='logits')
inference_logits = tf.identity(inference_logits.sample_id, name='predictions')
# https://www.tensorflow.org/api_docs/python/tf/sequence_mask
# - Returns a mask tensor representing the first N positions of each cell.
masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name='masks')
with tf.name_scope("optimization"):
# Loss function - weighted softmax cross entropy
cost = tf.contrib.seq2seq.sequence_loss(
training_logits,
targets,
masks)
# Optimizer
optimizer = tf.train.AdamOptimizer(lr)
# Gradient Clipping
gradients = optimizer.compute_gradients(cost)
capped_gradients = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gradients if grad is not None]
train_op = optimizer.apply_gradients(capped_gradients)8.1 dataloader
(source_int_text, target_int_text)为输入数据,(source_vocab_to_int, target_vocab_to_int)为查找每个值对应的索引值的字典
8.2 create inputs
详见代码
def hyperparam_inputs():
lr_rate = tf.placeholder(tf.float32, name='lr_rate')
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
return lr_rate, keep_prob8.3 建立seq2seq model
返回训练与推理结果
8.4 损失函数
TF contrib.seq2seq.sequence_loss:Weighted cross-entropy loss for a sequence of logits.为时序模型专用
8.5 优化器
8.6 梯度裁剪
RNN基本都会面临的问题就是训练过程中的梯度爆炸。解决方法就是梯度裁剪。常用的梯度裁剪有两种方法:
- 直接根据参数的梯度值直接进行裁剪
- 由若干参数的梯度组成向量的L2正则化进行裁剪
此处使用的是第一种方法:
通过确定阈值以使梯度保持在某个边界内。具体一点此处是阈值范围在-1和1之间。上面代码中的构建流程为:
- 通过调用compute_gradients手动从优化器中获取梯度值,
- 然后使用clip_by_value操作梯度值
- 需要通过调用apply_gradients将修改后的梯度放回到优化器中
此框架已经扩展到生理信号分类项目,泛化性能较好。