kubernetes之pod重调度-descheduler
1. kubernetes-sigs/descheduler简介
在使用kubernetes中,你是否存在以下困扰?
- 一些节点使用不足或过度使用。
- 最初的调度决策不再成立,因为污点或标签被添加到节点或从节点删除,不再满足 pod/节点亲和性要求。
- 一些节点出现故障,它们的 pod 移动到其他节点。
- 新节点被添加到集群中。
如果你也像我一样遇到上述问题的话,救星来了,那就是kubernetes-sigs/descheduler项目,该项目可以重新平衡资源使用,避免节点利用率不均匀,造成资源空闲和浪费,descheduler根据其策略,找到可以移动的 pod 并驱逐它们。请注意,在当前的实现中,descheduler不会安排被驱逐的pod的替换,而是依赖于默认的kube-scheduler。
项目地址: https://github.com/kubernetes-sigs/descheduler
2.kubernetes-sigs/descheduler实践
- Job模式
kubectl create -f kubernetes/base/rbac.yaml
kubectl create -f kubernetes/base/configmap.yaml
kubectl create -f kubernetes/job/job.yaml
- cronjob模式
kubectl create -f kubernetes/base/rbac.yaml
kubectl create -f kubernetes/base/configmap.yaml
kubectl create -f kubernetes/cronjob/cronjob.yaml
- deployment模式
kubectl create -f kubernetes/base/rbac.yaml
kubectl create -f kubernetes/base/configmap.yaml
kubectl create -f kubernetes/deployment/deployment.yaml
- helm模式
helm repo add descheduler https://kubernetes-sigs.github.io/descheduler/
helm install my-release --namespace kube-system descheduler/descheduler
具体的chart配置参考: https://github.com/kubernetes-sigs/descheduler/blob/master/charts/descheduler/README.md
5. Kustomize模式
1. job: kustomize build 'github.com/kubernetes-sigs/descheduler/kubernetes/job?ref=v0.21.0' | kubectl apply -f -
2. cronjob: kustomize build 'github.com/kubernetes-sigs/descheduler/kubernetes/cronjob?ref=v0.21.0' | kubectl apply -f -
3. deployment: kustomize build 'github.com/kubernetes-sigs/descheduler/kubernetes/deployment?ref=v0.21.0' | kubectl apply -f -
3.kubernetes-sigs/descheduler策略
支持的策略:
- RemoveDuplicates
- LowNodeUtilization
- HighNodeUtilization
- RemovePodsViolatingInterPodAntiAffinity
- RemovePodsViolatingNodeAffinity
- RemovePodsViolatingNodeTaints
- RemovePodsViolatingTopologySpreadConstraint
- RemovePodsHavingTooManyRestarts
- PodLifeTime 目前在实现中
所有策略默认启用。
策略示意图: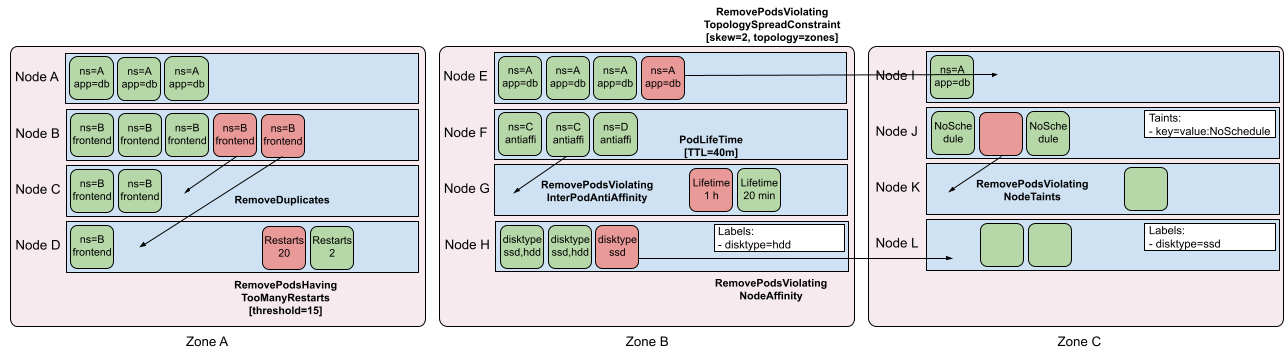
策略公共配置:
- nodeSelector - 限制处理的节点
- evictLocalStoragePods - 允许驱逐具有本地存储的 Pod
- evictSystemCriticalPods - [警告:将驱逐 Kubernetes 系统 Pod] 允许驱逐具有任何优先级的 Pod,包括像 kube-dns 这样的系统 Pod
- ignorePvcPods- 设置是否应驱逐或忽略 PVC pod(默认为false)
- maxNoOfPodsToEvictPerNode - 从每个节点驱逐的 Pod 的最大数量(通过所有策略求和)
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
nodeSelector: prod=dev
evictLocalStoragePods: true
evictSystemCriticalPods: true
maxNoOfPodsToEvictPerNode: 40
ignorePvcPods: false
strategies:
...
总结
kubernetes-sigs/descheduler可以说是在我们日常k8s运维过程中,提高资源使用效率的法宝,我们应该好好掌握它,最棒的事,它的文档写的非常详细,至于具体到策略的用法,这里就不在赘述,自行去github上学习即可,最后附上文档地址:https://github.com/kubernetes-sigs/descheduler#policy-and-strategies