
mysql> select campaign_id ,count(id) from creative_output group by campaign_id;
602843 rows in set (4 min 44.23 sec)
mysql> select is_cr_own ,count(id) from creative_output group by is_cr_own;
597684 rows in set (44.55 sec)
首先是查看tidb数据库的syncer工具的介绍
使用syncer工具的场景一般是:
全量导入历史数据后,通过增量的方式同步新的数据 (需要 checker + mydumper + loader + syncer)。该场景需要提前开启 binlog 且格式必须为 ROW。
主要的步骤我们可以看官网链接:
https://pingcap.com/docs-cn/op-guide/migration-overview/
注意:mysql必须开启几项服务才行,主要是bin-log功能,Binlog格式等等,详细请查看:https://pingcap.com/docs-cn/tools/syncer/ 的后半部分内容。
有一个文件syncer.mata需要注意:

我创建并编辑好这个文件后放在了/usr/local/tidb-tools目录下面,这个文件的目录需要在config.toml的内容中指定一下。但是我的重点是要说上面这个图片中的“binlog-gtid”这一行的内容。因为我本次实验没有用到主从环境,所以暂时不考虑binlog-gtid的问题,下面列一下我的文件内容

我只写了这两行数据,不过虽然没有用到binlog-gtid的功能,也应该指定出来,把binlog-pos设置为空就可以了,例如:binlog-pos=""
然后我们最好使用配置文件config.toml来启动syncer。config.toml文件可以放在任一位置,在启动syncer时提供文件即可:例如

其实位置是小问题,只是我在看文章的时候纠结z这个位置是在哪里呢,后来才知道是小问题。
还有几个报错的,我们需要注意一下:
1、报错:就是启动syncer的时候直接报错

居然不能连接mysql这肯定是配置文件的原因,查看一下来:
log-level = "info"
server-id = 101
## meta 文件地址
meta = "/usr/local/tidb-tools/syncer.meta"
worker-count = 16
batch = 10
## pprof 调试地址, Prometheus 也可以通过该地址拉取 syncer metrics
## 将 127.0.0.1 修改为相应主机 IP 地址
status-addr = "172.31.30.62:10086"
## 跳过 DDL 或者其他语句,格式为 **前缀完全匹配**,如: `DROP TABLE ABC`,则至少需要填入`DROP TABLE`.
# skip-sqls = ["ALTER USER", "CREATE USER"]
## 在使用 route-rules 功能后,
## replicate-do-db & replicate-ignore-db 匹配合表之后(target-schema & target-table )数值
## 优先级关系: replicate-do-db --> replicate-do-table --> replicate-ignore-db --> replicate-ignore-table
## 指定要同步数据库名;支持正则匹配,表达式语句必须以 `~` 开始
#replicate-do-db = ["~^b.*","s1"]
## 指定要同步的 db.table 表
## db-name 与 tbl-name 不支持 `db-name ="dbname,dbname2"` 格式
#[[replicate-do-table]]
#db-name ="dbname"
#tbl-name = "table-name"
#[[replicate-do-table]]
#db-name ="dbname1"
#tbl-name = "table-name1"
## 指定要同步的 db.table 表;支持正则匹配,表达式语句必须以 `~` 开始
#[[replicate-do-table]]
#db-name ="test"
#tbl-name = "~^a.*"
## 指定**忽略**同步数据库;支持正则匹配,表达式语句必须以 `~` 开始
#replicate-ignore-db = ["~^b.*","s1"]
## 指定**忽略**同步数据库
## db-name & tbl-name 不支持 `db-name ="dbname,dbname2"` 语句格式
#[[replicate-ignore-table]]
#db-name = "your_db"
#tbl-name = "your_table"
## 指定要**忽略**同步数据库名;支持正则匹配,表达式语句必须以 `~` 开始
#[[replicate-ignore-table]]
#db-name ="test"
#tbl-name = "~^a.*"
# sharding 同步规则,采用 wildcharacter
# 1. 星号字符 (*) 可以匹配零个或者多个字符,
# 例子, doc* 匹配 doc 和 document, 但是和 dodo 不匹配;
# 星号只能放在 pattern 结尾,并且一个 pattern 中只能有一个
# 2. 问号字符 (?) 匹配任一一个字符
#[[route-rules]]
#pattern-schema = "route_*"
#pattern-table = "abc_*"
#target-schema = "route"
#target-table = "abc"
#[[route-rules]]
#pattern-schema = "route_*"
#pattern-table = "xyz_*"
#target-schema = "route"
#target-table = "xyz"
[from]
host = "172.31.30.62" #是这一步出错了
user = "root"
password = "123456"
port = 3306
[to]
host = "172.31.30.62"
user = "root"
password = ""
port = 4000
不知道大概什么问题,虽然我的mysql和tidb主节点在一个机器上面,但是连接的时候指定不同的端口就可以了,可是在这里就是行不通,我猜应该是hosts文件映射的问题吧,但是我没有修改hosts文件,只是把上面的黄色区域的内容修改了为:“127.0.0.1”就成功了,我们看一下成功的例子:
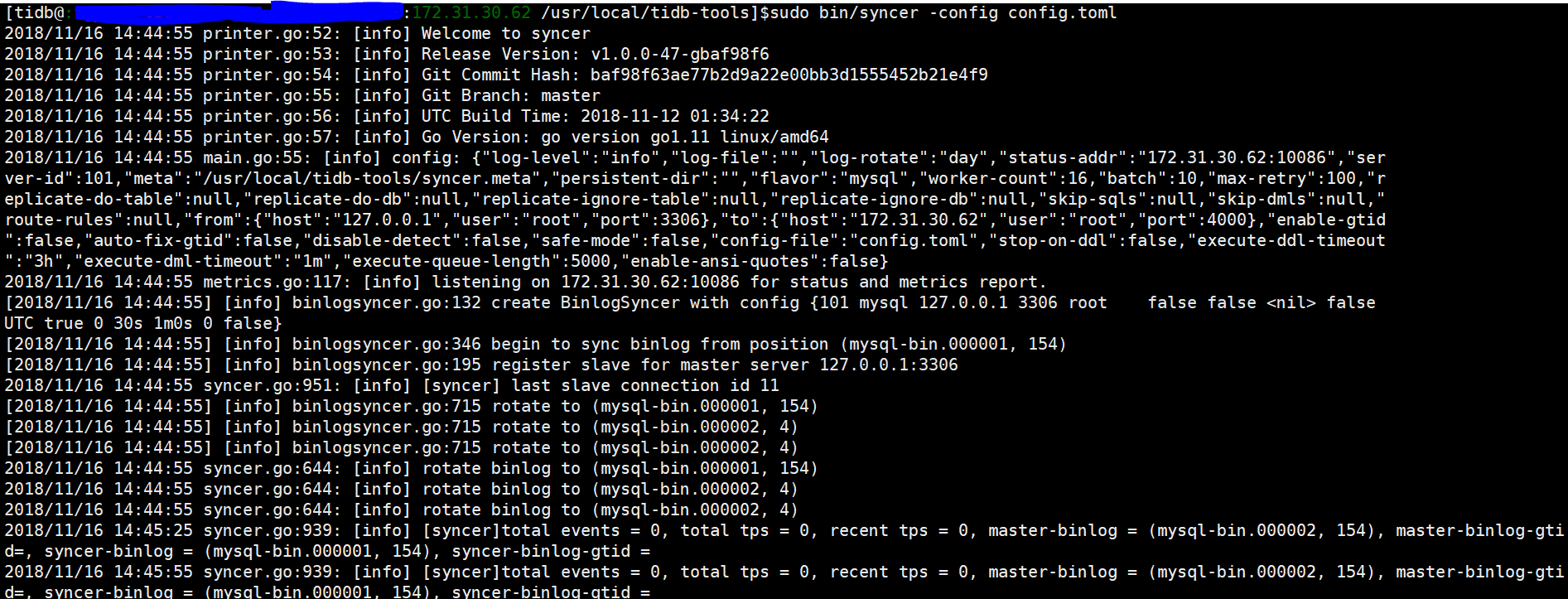
然后你在mysql中插入数据,syncer会实时写入tidb数据库中。
即便把syncer关掉之后,这个时候虽然不会同步,但是一启动进程就会立即同步mysql中之前未同步到tidb中的数据。
下面这是syncer的同步进程,在config.toml指定的













