原文链接:使用SAS代写EnterpriseMiner进行数据挖掘:信用评分构建记分卡模型
标签:
- 数据挖掘
- 风险管理
- 技巧和窍门
信用记分卡一直是信用评分的标准模型,因为它们易于理解,使您能够轻松评分新数据-即计算新客户的信用评分。本文将指导您完成使用Credit Scoring for SAS® EnterpriseMiner™开发的信用记分卡的基本步骤,这是我将在信用评分中发布的一系列技巧中的第一个。
建立记分卡用于构建信用记分卡的基本流程图中的节点包括:输入数据源,数据分区,交互式分组和记分卡。在本例中,您可以使用SAS Enterprise Miner的“帮助”菜单中提供的德语信用数据集。单击Help-> Generate Sample Data Source - > German Credit。该数据集具有二元目标good\_bad,其指示客户是否默认其每月付款(指定为值'BAD'),以及与作为输入或特征的人口统计和信用局相关的若干其他变量。

交互式分组节点简而言之,交互式分组节点是一个非常灵活的工具,用于对变量进行分箱或分组。这个节点:
- 使用您可以轻松调整的选项来分类输入变量
- 计算每个输入变量的箱的证据权重
- 计算基尼和信息值,并拒绝具有这些统计值的低值的输入变量
在幕后运行的过程可以根据您可以轻松定制的某些约束找到相对于目标的输入的最佳分级。确保使用节点的交互式应用程序直观地确认事件计数和证据权重趋势对您的分箱有意义。如有必要,您可以合并箱,创建新组或手动调整证据权重。
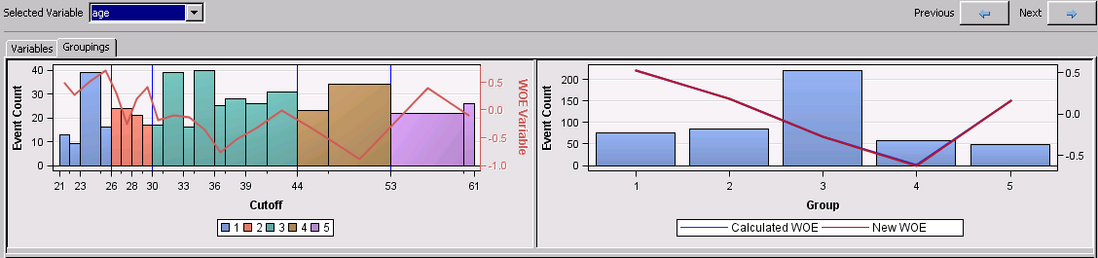
手动调整证据权重
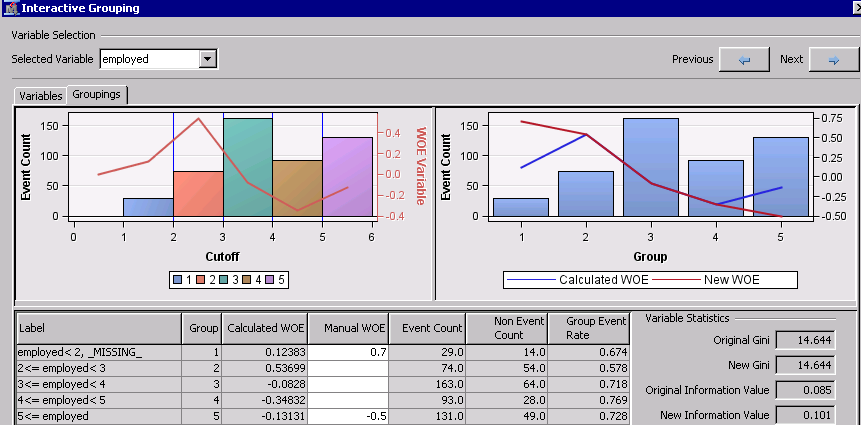
对于某些变量输入,您可能需要手动调整证据权重(WOE)。例如,可变采用总结了信用申请人在当前工作中受雇的年数。一般而言,当前工作的年数往往与信用违约成反比。对于该数据集,证据权重不会因第1组至第5组单调减少这一事实可能是由于多种原因。例如,这个数据集可能是样本偏向的,因为许多使用<2的应用程序是手动选择或“挑选”,并且它们的良好行为反映在低事件数和低权重证据中。要防止此样本偏差影响您的记分卡,您可以使用交互式应用程序中“分组”选项卡的“粗略详细信息”视图上的“手动WOE”列。对于组1,将WOE从0.1283更改为0.7,对于组2,将WOE从-0.13131更改为-0.5。新的WOE和信息值被重新计算为新信息值。
记分卡节点对使用“交互式分组”节点找到的箱或组感到满意后,运行“记分卡”节点以使用分组输入对逻辑回归进行建模。然后,它将创建每个输入组或属性的赔率的预测日志的线性变换,使其更易于解释。
默认情况下,每增加20个得分点,事件的几率就会翻倍。您正在建模的事件是付款默认值,这意味着例如,与得分为150的应用程序相比,得分为130分的应用程序的违约几率要高一倍。
在结果中,有几个有用的图表和表格,包括记分卡,分数分布,KS图,权衡图和许多其他。

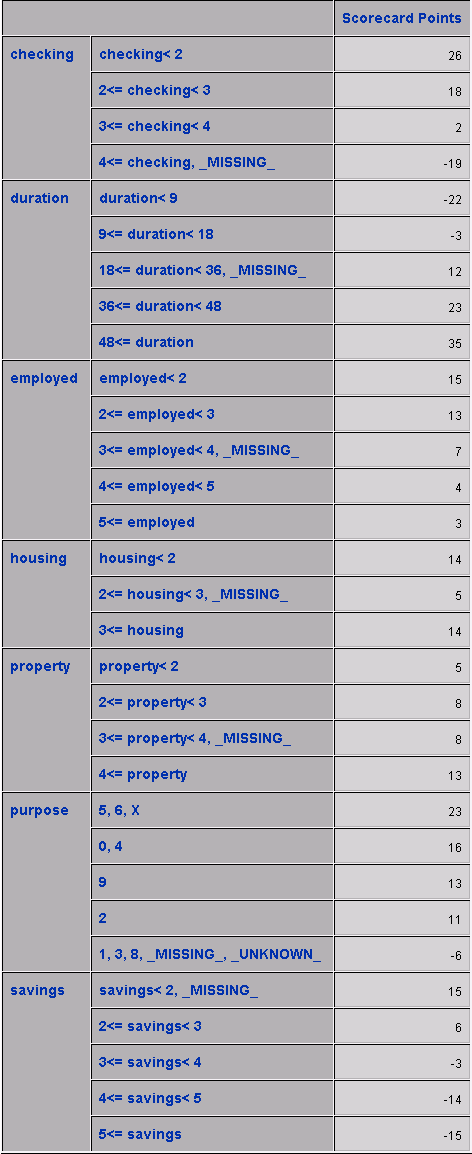
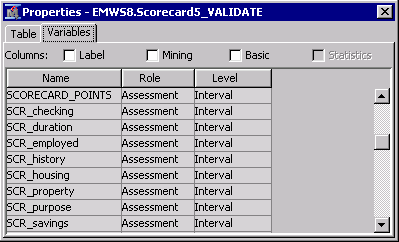
输出变量和不利特征请注意,从导出的数据集中,记分卡节点会创建多个变量。带有前缀SCR\_的变量是记分卡中每个变量的记分卡点,SCORECARD\_POINTS是每个应用程序的总点数。
当您指定记分卡属性生成报告=是以输出不良特征时,您的结果还将包括每个观察结果降低得分最多的变量。您最多可以选择5种不利特征。作为如何解释此列的示例,对于下面数据集的第一次观察,扣除了14个得分点,因为贷款的目的标记为1,3,8,缺失或未知。