
MTBF
平均无故障运行时间(即从开始运行到出现故障所经历的时间),通俗的讲时间越长,说明系统的稳定性和可靠性越好
MTTR
平均故障修复时间(即从系统发生故障到恢复正常所经历的时间),通俗的讲就是当业务系统故障时,修复系统所花费的时间。时间越短,说明我们的修复和维护工作越高效,也可从侧面说明该业务系统的自愈合能力和抗灾害能力越强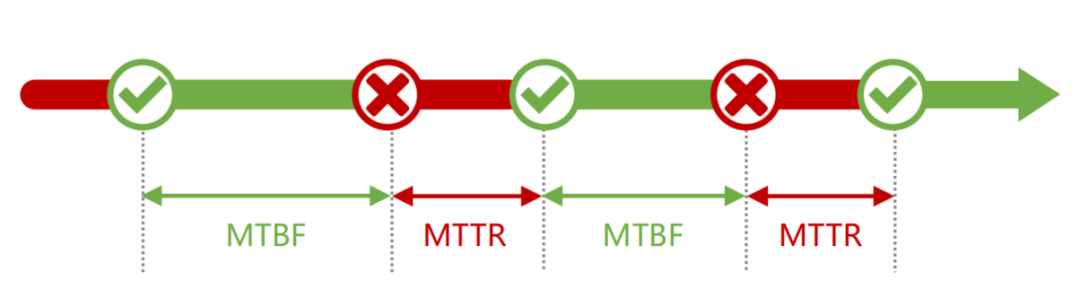
可靠性与可用性
可靠性是从故障出现的次数或频率来判断的,出现故障的次数越少则可靠性越好
可用性是从总的故障时长来判断的,故障总时间越短则可用性越好
SLI
服务水平指示器,直译不好理解。通俗的讲就是用来评价我们服务质量的指标,例如:
- 磁盘存储的可靠性:98%
- 网站访问的延迟:<40ms
- 2xx状态请求占比: 99.92%
- 服务的可使用时间: 98.75%
SLO
服务水平目标。用来描述SLI的目标值,通常指我们在服务时间内(如月度,季度,年度)需要达到的服务目标,SLO可以理解为考核值,而SLI是实际值
| 服务指标(年度) | SLI | SLO | 服务目标达成情况 |
|---|---|---|---|
| 磁盘存储的可靠性 | 98% | 99.999% | 未达成 |
| 网站访问的延迟 | <40ms | <30ms | 未达成 |
| 2xx状态请求占比 | 99.92% | 99.999% | 未达成 |
| 服务的可使用时间 | 99.75% | 99% | 达成 |
SLA
服务水平协议。和用户签订的服务条款,通常是指一些赔付条款。例如通过监控SLI值,并和SLO对比,如果未达成SLO,需要如何为客户提供赔偿
示例
奥得彪在AWS上购买了一台弹性云服务器EC2,用来搭建香蕉零售网站。结果AWS的非洲数据中心多次发生了故障,影响了奥德彪的EC2,一年宕机了共计320个小时,根据计算EC2的年度可用性指标仅仅为96.35%(SLI)。
奥德彪很生气,因为AWS的销售人员承诺他,EC2的年度可用性指标是99.75%(SLO),即故障时间小于22小时。
然而实际情况是SLI<SLO,说明AWS提供的服务质量明显没达标。于是奥德彪打开了和AWS签署的用户协议(SLA),上面写着对于额外故障时间,每小时赔付用户10美元。根据此协议,AWS为奥德彪赔偿了2980美元
说明:
从上面的例子我们理解了SLI,SLO,SLA这几个概念,设计这几个概念的初衷在于量化我们的服务质量,管理客户的预期。例如客户总是抱怨网站访问慢,但“慢”是一种很难量化的相对的心里感受状态,并不能直观反映服务质量。
我们可以告诉用户:你使用的共享实例延迟小于80ms(SLO),价格10元/天,而独享实例延迟<20ms(SLO),价格100元/天, 你可以选择独享实例来提升速度。而用户通过直观的数据,对服务质量和价格有了量化的比较,再看看钱包,也许就不觉的慢了。。。。。。
SLO的设定要合理,(SLI - SLO)的差值波动越小越好,不要给用户越级体验和预期,这对工作并无益处







