
FPGA越往底层走,越发现很多问题只是知其然,而不知其所以然。状态机编码原则就是其中之一。我们在实际开发中,只记住了建议使用独热码(one hot)作为状态编码,至于为什么(大概也就记得不容易跑飞),可能早就忘了。
以经典的案例来说明其中的一些问题:
- 序列检测,每检测到一组“11011”,然后输出一个高电平。
状态转移图如下图所示:
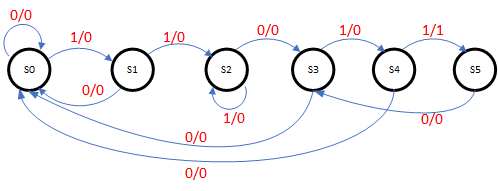
状态机的Verilog代码如下:
module FSM_test(
input clk,
input rst_n,
input d_in,
output d_out
);
/* parameter S0 = 5'b000000,
S1 = 5'b000001,
S2 = 5'b000011,
S3 = 5'b000010,
S4 = 5'b000110,
S5 = 5'b000111; */
parameter S0 = 5'b00000,
S1 = 5'b00001,
S2 = 5'b00010,
S3 = 5'b00100,
S4 = 5'b01000,
S5 = 5'b10000;
/* parameter S0 = 5'd0,
S1 = 5'd1,
S2 = 5'd2,
S3 = 5'd3,
S4 = 5'd4,
S5 = 5'd5; */
reg r_d_out;
reg [4:0] cs,ns;
always@(posedge clk or negedge rst_n) begin
if(rst_n == 1'b0) begin
cs <= S0;
end else begin
cs <= ns;
end
end
always@(*) begin
ns = 5'dx;
case(cs)
S0: begin
if(d_in == 1'b1)
ns = S1;
else
ns = S0;
end
S1: begin
if(d_in == 1'b1)
ns = S2;
else
ns = S0;
end
S2: begin
if(d_in == 1'b1)
ns = S2;
else
ns = S3;
end
S3: begin
if(d_in == 1'b1)
ns = S4;
else
ns = S0;
end
S4: begin
if(d_in == 1'b1)
ns = S5;
else
ns = S0;
end
S5: begin
if(d_in == 1'b1)
ns = S2;
else
ns = S3;
end
default:
ns = S0;
endcase
end
always@(posedge clk or negedge rst_n) begin
if(rst_n == 1'b0) begin
r_d_out <= 1'b0;
end else if(cs == S5)begin
r_d_out <= 1'b1;
end else begin
r_d_out <= 1'b0;
end
end
assign d_out = r_d_out;
endmodule
上面代码中,定义了格雷码、独热码以及二进制码(序列码)的状态编码方式,本想在vivado下看综合后的原理图,发现三种编码方式综合后的结果一样!不符合理论啊,所以想是不是被vivado优化了。果然,查书发现在综合选项中,“-fsm_extraction”选项为auto,在auto下,本段状态就会被优化成格雷码的编码方式。

取消该优化之后,仅对比格雷码和独热码的综合结果,原理图如下:
- 格雷码

- 独热码

格雷码消耗4个LUT和3个Register,而独热码消耗7个LUT和6个Register。不是说独热码更省组合逻辑吗??为什么反而消耗LUT更多。到了这一层,还是不能往下理解,是代码设计问题还是综合问题?
做了一个尝试之后,还是把前人结论和经验总结一下:
- 二进制码:
有过渡状态,容易跑飞。
- 格雷码:
减少过渡状态,每次只有一位变化,因此可以降低功耗。但是如果当一个状态到下一个状态有多种转换路径时,就不能保证状态跳转时只有一个位变化,这样就无法发挥格雷码的特点了。
- 独热码:
少用组合逻辑,多了寄存器。速度更快、可靠性更好。
至于二进制码咱不用讨论,因为对于状态少的情况(小于4),也可以使用,因为跑飞的概率极其小。
对于格雷码和独热码,到底应该怎么选择才能达到最优综合?查阅书籍及网络资料,总结起来就是:
- 格雷码:适合所有状态是顺序序列,可以用格雷码来消除毛刺,但如果有复杂分支判断,则格雷码也不能达到消毛刺的目的,简单的说,格雷码适合条件不复杂,状态多的情况;
- 独热码:消耗较少组合逻辑,消耗更多寄存器,因此在FPGA中有利于速度和可靠性。适合条件复杂,状态少的情况。
另外,在CPLD中由于组合逻辑多,而寄存器少,所以可能不适合独热码,更适合格雷码和二进制编码。













