
不使用索引
CREATE TABLE `test1` (
`id` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
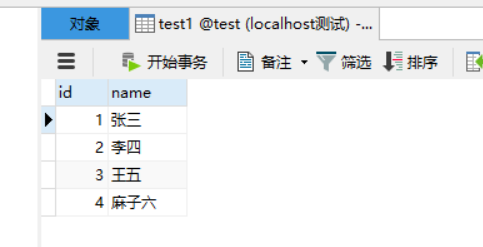
BEGIN;
-- 手动开启一个事务,并在id = 1这条数据上加上排它锁
SELECT * from test1 WHERE id = 1 for UPDATE;
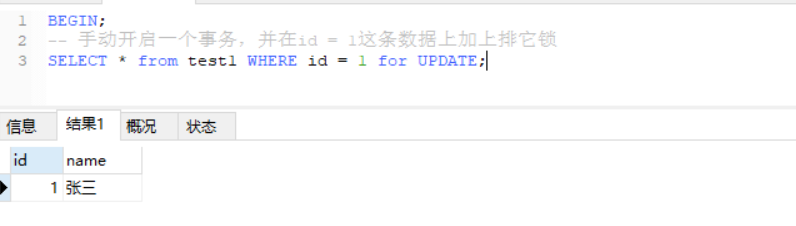
BEGIN;
-- 手动开启另外一个事务,此时给id=2的这条数据进行加排它锁,结果会如何?
SELECT * from test1 WHERE id = 2 for UPDATE
发现此时居然查询id=2的数据事务被卡住了。这是为什么呢?当表没有创建索引时或者查询语句没有命中索引时,锁住的是整个表的数据,因为没有命中索引故其会去扫描全表数据。 当一张表没有索引时,innoDB会创建一个隐藏主键索引,当通过隐藏的主键索引去检索时,将该表中所有的隐藏索引检索一遍 例子:如果手动开始事务,并在id=1的数据上手动加上排它锁.如果此时再去查询id=2的数据时,发现此语句卡住了。 故得出没有建立索引的表,一旦锁住数据及为锁住整张表。
主键索引
CREATE TABLE `test2` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
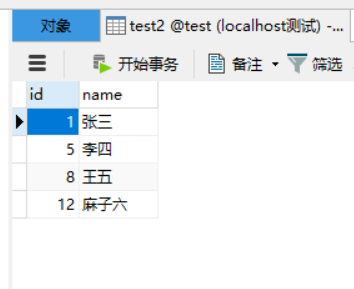
BEGIN;
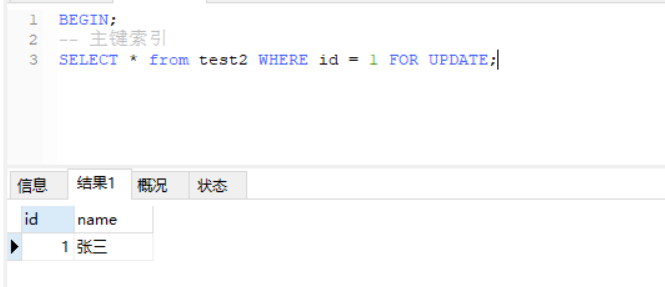
-- 主键索引
SELECT * from test2 WHERE id = 1 FOR UPDATE;
BEGIN;
-- 手动开启其他事务
SELECT * from test2 WHERE id = 5 for update;
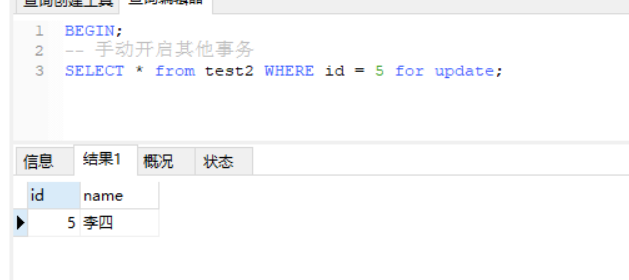 此时说明,主键索引时只会锁住匹配到的索引项,而不会影响其他事务操作其他索引
此时说明,主键索引时只会锁住匹配到的索引项,而不会影响其他事务操作其他索引
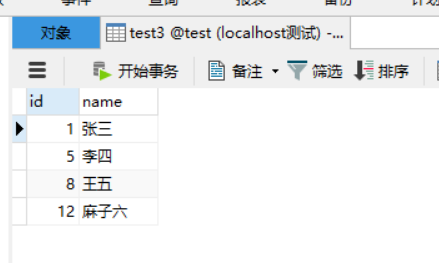
唯一索引
CREATE TABLE `test3` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
BEGIN;
-- 唯一索引
SELECT * from test3 where name = '李四' FOR update;

BEGIN;
-- 唯一索引
SELECT * from test3 where id= 5 FOR update;
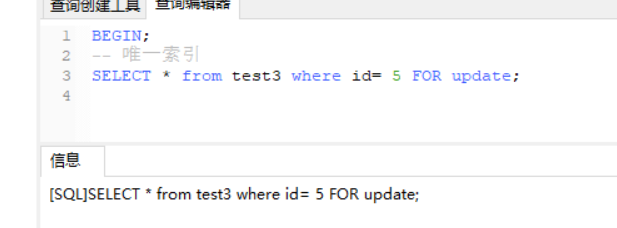 注意:此时SELECT * from test3 where id= 5 FOR update为什么执行卡住了?唯一索引锁定时,先通过唯一索引然后找到对应主键索引,也就是辅助索引--->主键索引的一个过程,所以查询id = 5的数据时也被锁住了。 通过上面几个例子发现mysql innodb是通过锁住索引来实现行锁的
注意:此时SELECT * from test3 where id= 5 FOR update为什么执行卡住了?唯一索引锁定时,先通过唯一索引然后找到对应主键索引,也就是辅助索引--->主键索引的一个过程,所以查询id = 5的数据时也被锁住了。 通过上面几个例子发现mysql innodb是通过锁住索引来实现行锁的
mysql innodb 为什么不会出现幻读?
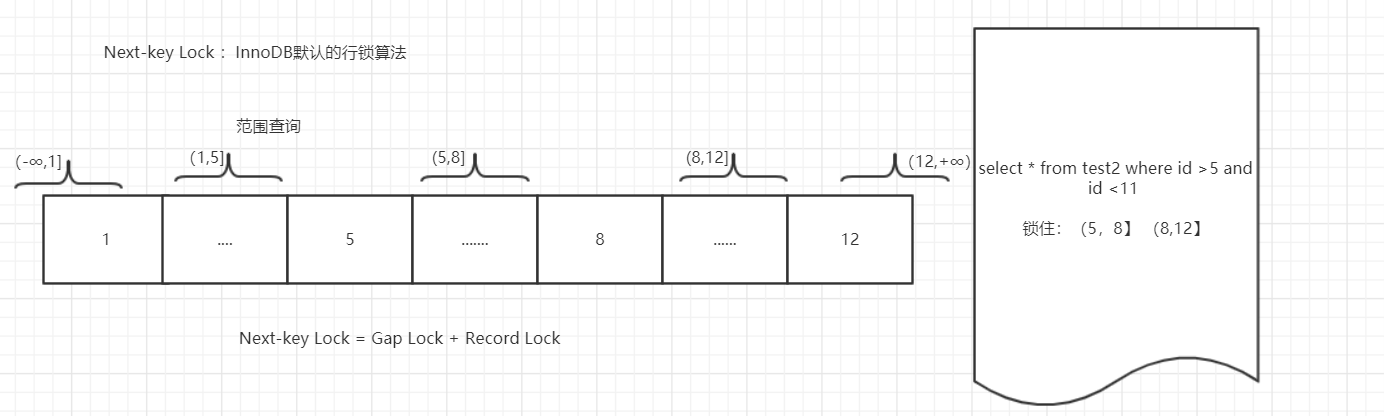
详见下面InnoDB的行锁,如下图 临界锁的操作 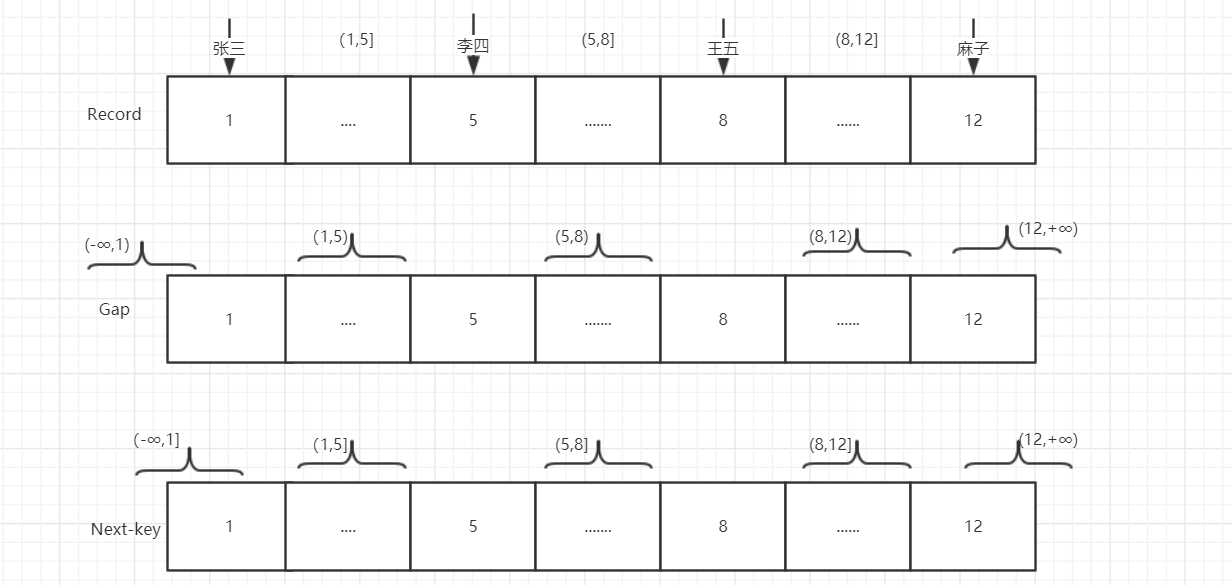
临界锁(Next-key Lock)锁定范围加记录
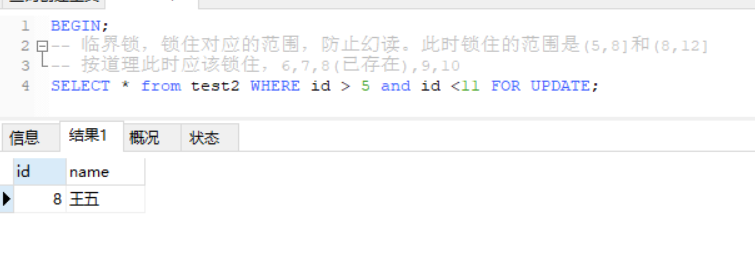
BEGIN;
-- 临界锁,锁住对应的范围,防止幻读。
-- 按道理此时应该锁住,6,7,8(已存在),9,10
SELECT * from test2 WHERE id > 5 and id <11 FOR UPDATE;
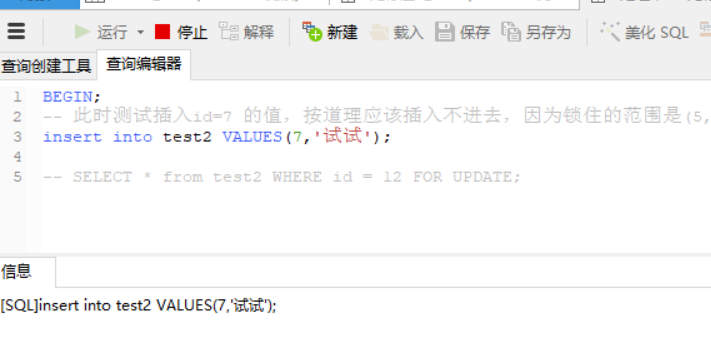
BEGIN;
-- 此时测试插入id=7 的值,按道理应该插入不进去,因为锁住的范围是(5,8]和(8,12]
insert into test2 VALUES(7,'试试');
BEGIN;
SELECT * from test2 WHERE id = 12 FOR UPDATE;
刚才不是id>5 and id <11的么?此时为什么id =12也被锁了呢?因为此时锁住的范围是(5,8]和(8,12]
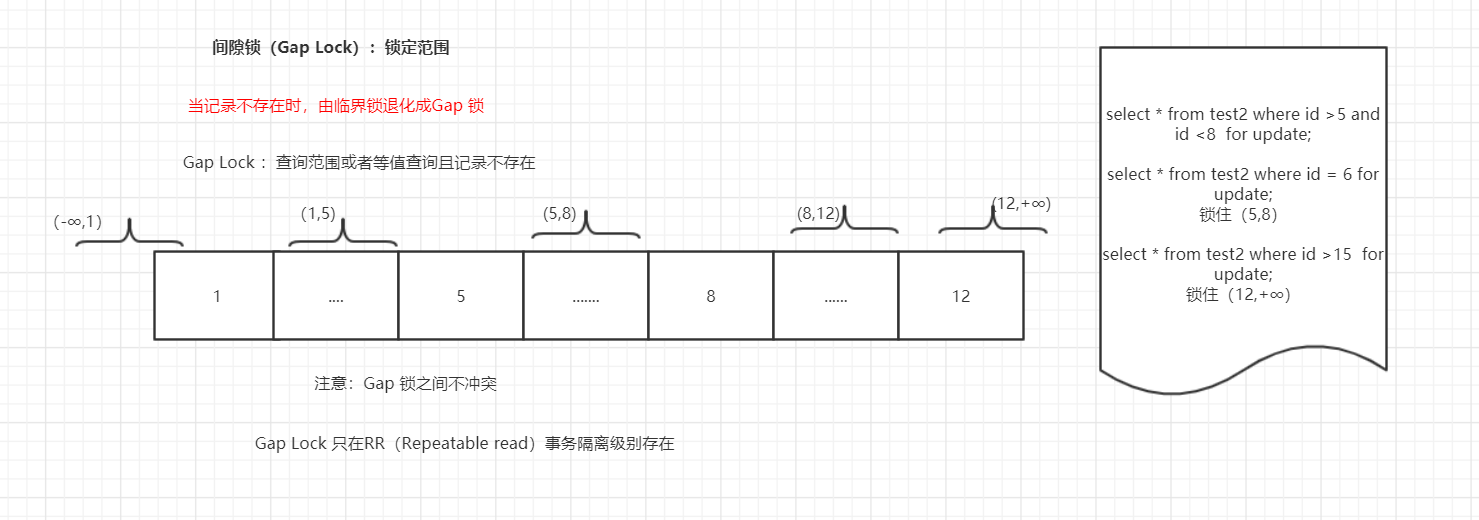
Gap Lock(间隙锁)
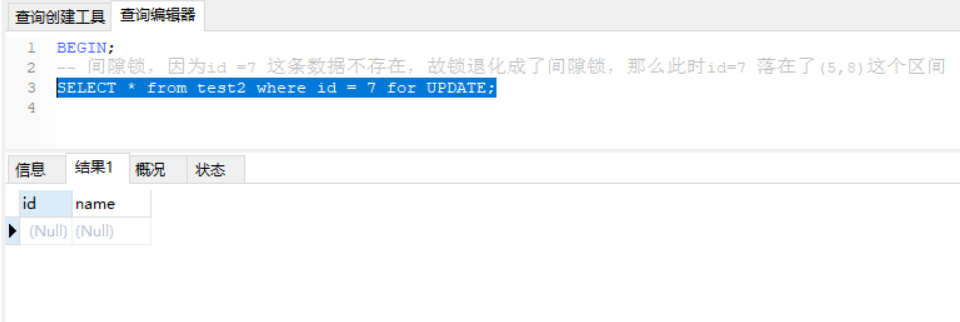
BEGIN;
-- 间隙锁,因为id =7 这条数据不存在,故锁退化成了间隙锁,那么此时id=7 落在了(5,8)这个区间
SELECT * from test2 where id = 7 for UPDATE;
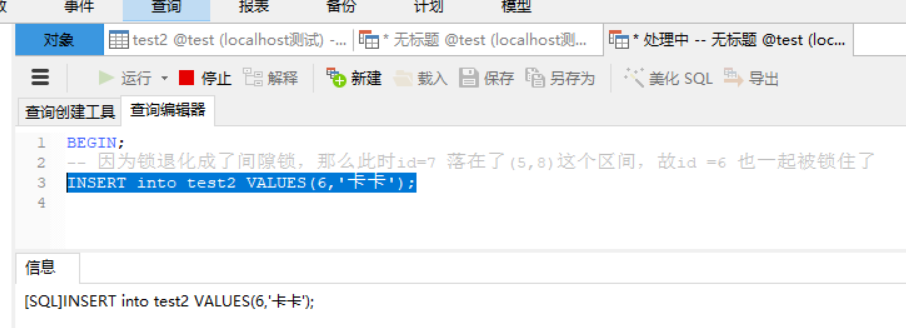
BEGIN;
-- 因为锁退化成了间隙锁,那么此时id=7 落在了(5,8)这个区间,故id =6 也一起被锁住了
INSERT into test2 VALUES(6,'卡卡');
Record Lock(记录锁)
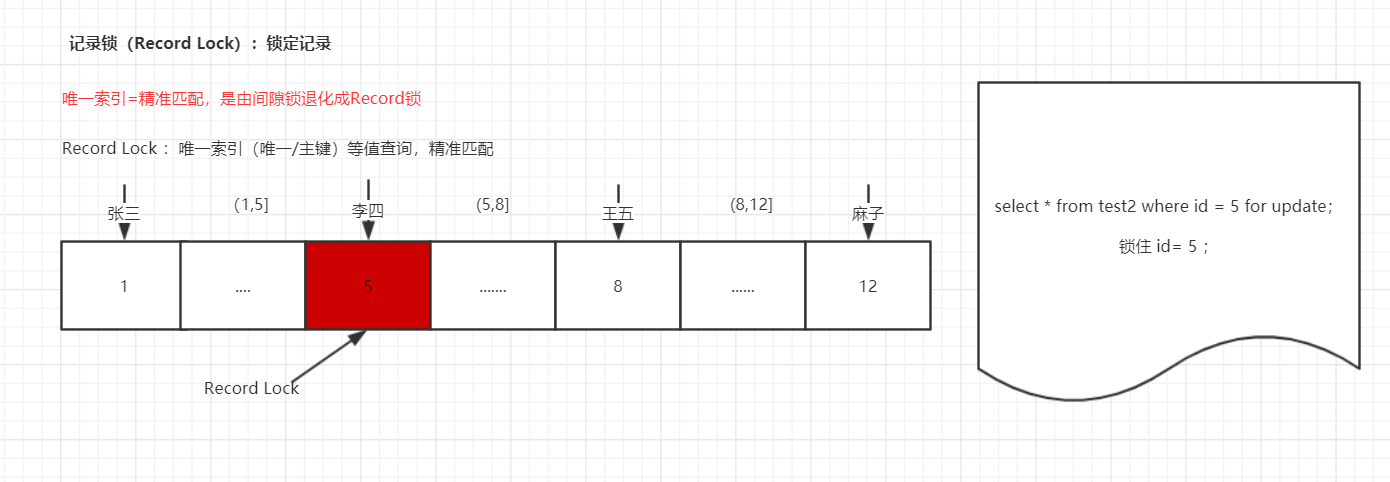
注意: 测试在test2表中,也就是主键索引。
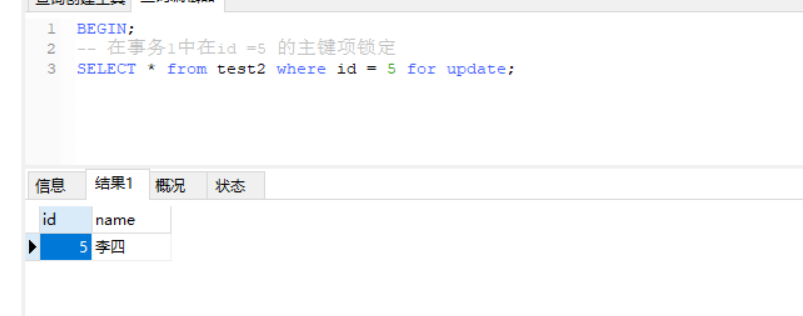
BEGIN;
-- 在事务1中在id =5 的主键项锁定
SELECT * from test2 where id = 5 for update;
本文是摘抄的,原文路径: https://my.oschina.net/u/3370769/blog/3000934
自己补充点东西把,自己不理解的地方也做下笔记。
间隙锁(gap lock),锁住的是一个区间范围,比如锁住区间(1,3),如果插入2的数据是插入不进去的,1和3是开区间,因此,1和3不受影响。
临界锁(next key lock),锁住索引上的记录+前面的间隙锁,是一个左开右闭区间,比如(1,3]。一个next-key锁=索引上的记录锁+锁住前面间隙的gap lock。














