
起因
最近部门搭建的harbor镜像仓库因为更改ip地址,导致使用 docker pull 命令时,发生错误,如下:
# docker pull 10.1.27.89:9000/vappserver/test-image:1.0
Error response from daemon:
Head "http://10.1.27.89:9000/v2/vappserver/test-image/manifests/1.0":
Get "http://10.1.27.240:9000/service/token?account=admin&scope=repository%3Avappserver%2Ftest-image%3Apull&service=harbor-registry":
dial tcp 10.1.27.240:9000: connect: no route to host仔细看错误提示,我们访问的是“10.1.27.89:9000”,缘何却访问了“http://10.1.27.240:9000/service/token”?而这里的 “10.1.27.240”刚好就是harbor的旧ip地址。
由于不了解docker pull命令背后的执行过程、以及和harbor仓库之间的通讯协议究竟是什么(http协议吗?)所以想要尝试通过抓包方式查看下docker pull命令的执行过程、以及为什么访问了旧的ip?
网上检索一番,发现有开源的rpcapd程序,可以结合wireshark的“远程接口”功能,在windows环境的wireshark中监听linux主机的网络通讯。
网上内容基本都需要源码下载、本地编译。按照惯例,先查docker镜像,果然有现成可用的。
以下做一下记录备忘。
docker-compose配置
version: '3.3'
services:
wireshark-rpcapd:
# 参考:https://github.com/rpcapd-linux/rpcapd-linux
image: soveren/rpcapd:v0.1.3
# 直接使用主机的网络,所以不再需要端口映射
network_mode: host
command:
- /bin/rpcapd
# 仅仅使用ipv4
- "-4"
# 不限制客户端连接 (否则可以限定wireshark所在的ip才能连接)
- -n
# 监听的端口,在wireshark中,使用ip+此处的端口连接rpcapd
- "-p 2002"
wireshark的配置
在wireshark中,选择捕获-选项,继续选择“管理接口”,我们添加上远程接口,其中ip为linux主机ip,端口即docker-compose文件中command部分配置的端口,例如“2002”
由于在linux主机中启动了多个docker容器,创建了多个虚拟网络接口,所以接下来对网络接口的扫描稍慢。稍等片刻,我们在自动列出的网络接口中,选择有用的接口,如主机的网络接口(例如名字ens33)、主机的环回地址接口(即127.0.0.1,名字是lo或者loopback),把剩余网络接口前面的勾选项去掉即可。
最终如下: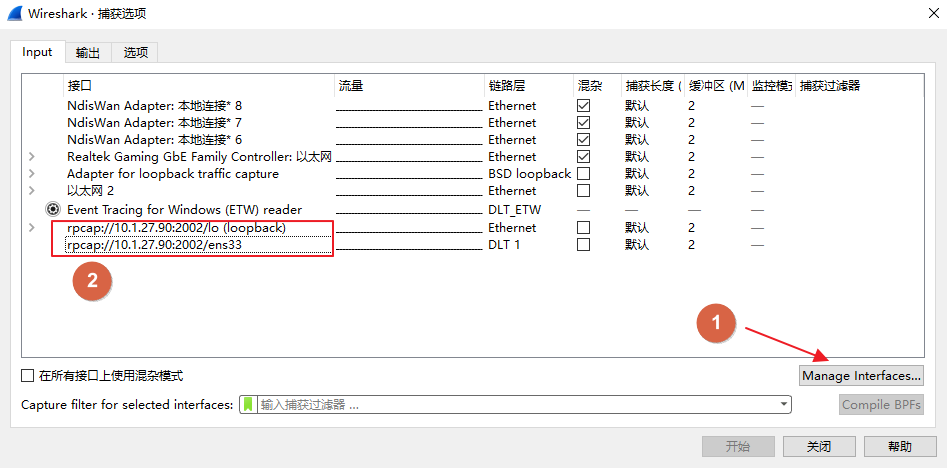
然后就可以继续愉快的玩耍了!












