
前言
在当今互联网世界,推荐系统在内容分发领域扮演着至关重要的角色。如何尽可能的提升推荐系统的推荐效果,是每个推荐算法同学工作的核心目标。在爱奇艺海外推荐业务,引入TensorFlow Ranking(TFR)框架,并在此基础上进行了研究和改进,显著提升了推荐效果。本文将分享TFR框架在海外推荐业务中的实践和应用。
01
算法的迭代:从传统CTR预估到LTR
长期以来,在推荐系统排序阶段广泛应用的CTR预估算法的研究重点在于,如何更加准确的估计一个用户对于一个item的点击概率。在这类算法中,我们将一组同时曝光在用户面前的items,当做一个一个单独的个例看待,将用户的特征、环境特征和一个一个item 的特征分别组合成为一条条训练数据,将用户对这个item的反馈(点击、未点击、播放时长等)作为训练数据的标签。这样看似合理的问题抽象其实并不能准确的表征推荐场景。
严格来讲,排序问题的本质(尤其是以瀑布流形式呈现的业务)并不是研究估计一个用户对于一个单独的item的点击概率,而是研究在一组items同时曝光的情况下,用户对这组items中哪个的点击概率更大的问题。
Learning-To-Rank(LTR)算法正是为解决这个问题而出现的。LTR算法在训练时采用pairwise或者listwise的方式组织训练数据,将一组同时曝光在用户面前的items,两两(pairwise)或者多个(listwise)items和用户特征环境特征共同组成数据对,作为一条条的训练数据。相应的,在评估模型的指标上,LTR算法更多采用NDCG、ARP、MAP等能够反映items顺序影响的指标。
同时,由于LTR算法的这种训练数据组织形式,使得这类算法在用户量相对不大的场景下,更容易取得比较好的效果。同样得益于这种数据组织形式,也很方便的实现更好的负样本采样。
(关于推荐业务中采样和模型评估指标之间还有一个有趣的研究可以参考,2020 KDD Best Paper Award ,On Sampled Metrics for Item Recommendation)
02
框架的设计:TensorFlow Ranking(TFR)
TensorFlow Ranking(TFR)是Tensorflow官方开发的LTR框架,旨在基于TensorFlow开发和整合LTR相关的技术,使开发人员可以更加方便的进行LTR算法的开发。
在实际使用过程中,可以体会到TFR框架为我们带来的收益。框架内抽象出了训练中不同层级的类,并开发了相关的loss函数,以方便我们进行pairwise和listwise的训练,同时整合了arp、ndcg等模型评估的metrics,再结合tf高阶api(Estimator),可以非常方便快捷的进行开发,而不用挣扎于各种实施上的细节。
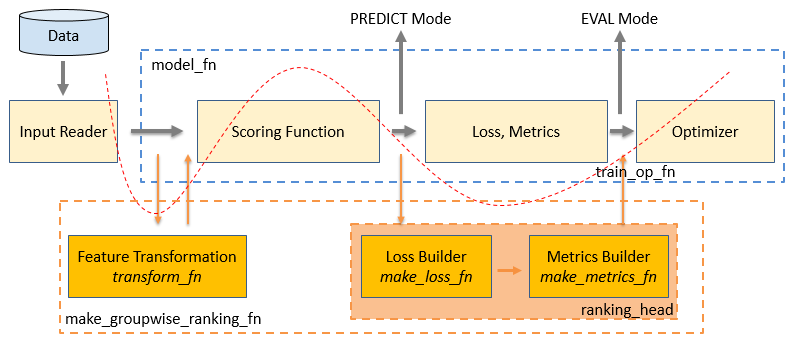
如上图所示,蓝色框图中是在使用TensorFlow Estimator时,model_fn参数内需要自己设计和开发的算法模型模块。在这个model_fn中,需要自行设计模型结构(Scoring Function),然后用模型计算的logit和label来计算Loss和Metrics,最后利用Optimizer来进行模型的优化。图中,红色虚曲线下方的部分为使用TFR框架的整个流程。
从图中可以看出,其实TFR框架主要是做了两方面的工作:
1. 把原有model_fn中Scoring Function和Loss、Metrics的计算进行了拆分,然后将原有流程中我们自行实现的Loss和Metrics替换为TFR框架中的LTR相关的Loss和Metrics。
2. 为了配合TFR框架中的LTR相关的Loss和Metrics来实现LTR的训练,训练数据需要以listwise的形式组织。但由于需要使用原有model_fn中Scoring Function,在数据输入的部分通过LTR框架中的数据转换函数来对模型输入的训练数据进行转化,使得以listwise形式组织的数据能够利用Scoring Function来计算logit。
所以,在TFR框架中,从数据到模型训练完整的流程是:训练数据--》用户定义feature_columns--》transform_fn特征转换--》Scoring Function计算score--》ranking_head的loss_fn计算loss–》ranking_head的eval_metric_fns计算评价指标–》optimizer进行优化。
从使用层面看,TFR框架就是做了上面两件事,看起来似乎并不复杂。但是从框架开发的角度上看,为了实现上述流程,TFR框架内在losses.py和metrics.py中开发了多个LTR相关的Loss和Metrics,在data.py内实现了读取和解析以listwise形式组织数据的tfrecords文件的工具,还在feature.py中开发了兼容TensorFlow特征转换函数的特征处理工具。最后通过head.py和model.py中的类对上述功能进行了层层封窗和抽象,并与TensorFlow Estimator很好的结合起来。
具体一些来看,代码组织上,TFR框架主要这样实现的:
第一:
tfr通过
tfr.model.make_groupwise_ranking_fn来对Estimator的model_fn进行了整体的封装。我们原有的基于tf的开发,在Estimator的model_fn这个参数内需要定义包括Loss、Metrics在内的完整的模型函数,但是在tfr这里就不需要了,make_groupwise_ranking_fn会整体返回一个Estimator接收的model_fn。
第二:
tfr.model.make_groupwise_ranking_fn函数的第一个参数group_score_fn,这里是需要传入我们设计和开发的模型结构(Scoring Function),但是这个模型是之前我们提到的,只需要计算出logit的模型。
第三:
tfr.model.make_groupwise_ranking_fn函数的第三个参数transform_fn,对应调用feature.py中开发了兼容TensorFlow特征转换函数来对以listwise形式组织的数据(由data.py中的工具读取进来的Dataset)进行转换,确保输入Scoring Function的数据格式正确。
第四:
tfr.model.make_groupwise_ranking_fn函数的第四个参数ranking_head,对应调用了tfr.head.create_ranking_head函数,里面的三个参数分别定义了loss、metrics和optimizer。loss和metrics分别从TFR的losses.py和metrics.py中选择我们需要的,而optimizer还是使用TensorFlow中的optimizer。
以上就是TFR框架的整体架构,其实这个框架整体设计和代码实现,还是非常优雅和巧妙的。
03
遇到的问题和实践
TFR框架的精巧设计和实现解决了我们基于TensorFlow做LTR算法中的80%到90%的问题。但是作为一个2019年才发布第一个版本的框架,TFR还是存在一些待优化的地方。
在分享TFR框架上的实践前,首先介绍一下TFR框架的版本情况,目前TFR框架发布的版本中,0.1.x版本支持TensorFlow 1.X版本,而0.2.x和0.3.x版本都只支持TensorFlow 2.X版本。考虑到TensorFlow 2.X版本还存在一些不确定性(如前段时间爆出使用 Keras 功能 API 创建的模型自定义层中的权重无法进行梯度更新的问题。
(https://github.com/tensorflow/tensorflow/issues/40638),目前大量的算法开发人员其实还在用TensorFlow 1.X版本。我们目前也在使用TensorFlow 1.X版本,所以本文介绍的内容,描述的问题和给出的解决方案,都是基于TensorFlow 1.14版本,对应最新的TFR 0.1.6版本。
我们最开始使用TFR框架是2019年年中的时候,当时TFR框架的最新版本是0.1.3。在使用的过程中,我们发现这个版本无法支持sparse/embedding features。但是推荐的特征中,稀疏特征是不可或缺的一部分,并且可能大部分特征都是稀疏的,所以我们不得不放弃使用。但是很快,在稍后发布的0.1.4版本中这个问题就得到了解决。
我们正式开始使用TFR框架是从0.1.4版本开始的。但是到目前最新的0.1.6版本,还是有两个我们不得不用的特性还是没有在TFR 0.1.x版本上得到支持:
· 训练过程中无法实施正则化
如前所述,TFR框架通过make_groupwise_ranking_fn来对Estimator的model_fn进行了整体的封装。
我们自己设计和开发的模型(Scoring Function),定义了网络,输入输出节点,最后只需要输出一个logit。这个和传统TensorFlow Estimator下model_fn模型开发不一样,传统的模型不仅仅要输出一个logit,模型里面还需要定义如何计算loss,怎样优化等内容。但是TFR框架将这部分内容已经进行了封装和整合,所以这里的score_fn就不需要这些了。这就带来一个问题,原来的模型设计中,我们可以直接拿出网络中需要正则化的参数,放在loss的计算中进行优化就可以了。但是使用TFR框架后,由于模型的设计和正向的计算在我们自己设计的模型函数中,而loss的计算在TFR框架内(ranking_head中的loss_fn)进行,这样就没办法加入正则化项了。
已经有人提出了这个issue,但是也没有很好的解决方案:(https://github.com/tensorflow/ranking/issues/52)
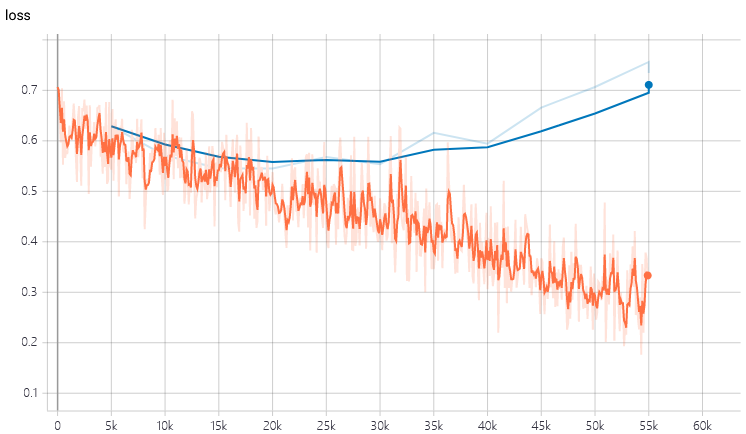
当我们使用比较复杂的网络时,正则化是我们优化过程中必不可少的一环。不加入正则化项进行优化,将无法避免的陷入到严重的过拟合中,如下图所示:
为了能够方便的利用TFR框架其他功能,我们深入TFR框架源码中试图解决正则化问题。正如上面分析,TFR框架无法实施正则化的原因在于,模型(Scoring Function)是我们自己设计和开发的,但是loss的计算是TFR框架帮我们封装好的。所以解决这个问题的核心就是如何在我们自己开发的模型中取出需要正则化的参数并传递给TFR框架中计算loss的部分就可以了。在TFR框架中,我们的模型计算好的logit,是通过ranking_head的create_estimator_spec方法,把logit,labels与TFR框架中定义的loss函数整合一起,来完成整个优化过程的。而在0.1.5版本的TFR框架中,这个create_estimator_spec方法其实已经支持传入regularization_losses了(估计未来版本一定会支持),而由于初始化ranking_model对象(我们的Scoring Function)。
GroupwiseRankingModel不支持我们拿到自己模型的正则化项,所以才无法实现。
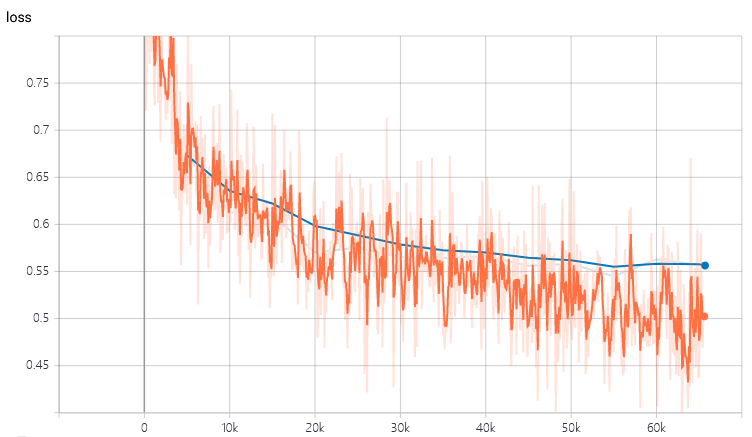
理论上,只要我们重写TFR源码中_GroupwiseRankingModel类的compute_logits方法,就能够让TFR支持正则化了。具体的代码上如何处理可以参考这里(如何解决TensorFlow Ranking框架中的正则化问题)。在加入正则化项后,跟上图同样的模型训练时就没有那么严重的过拟合现象了:
· 特征输入不支持Sequence Features
前边介绍过,在TFR框架中,模型输入的特征分为context_features和example_features,分别对应于一次请求公共的特征(上下文特征、用户特征等)和item独有的特征。以listwise形式组织的数据(一般是由data.py中的工具读取tfrecords文件生成的Dataset)需要经过TFR的特征转换函数(_transform_fn)转换后,再送入到我们的模型(Scoring Function)中。
而目前的特征转换函数(_transform_fn)只支持numeric_column、categorical_column等经典类型特征的转换,尚不支持sequence_categorical_column类型特征的转换。要解决的TFR无法支持SequenceFeatures问题,主要是对transform_fn特征转换这一步进行调整。
在transform_fn中,特征转换时用到的tfr.feature.encode_listwise_features和
tfr.feature.encode_pointwise_features函数都在feature.py中定义。
这两个函数的作用是在listwise或者pointwise模式下利用用户定义的feature columns生成输入模型的dense tensors。这两个函数都是调用encode_features函数来具体执行feature columns生成输入模型的dense tensors,而encode_features函数只支持numeric_column、categorical_column等经典类型特征的转换,尚不支持sequence_categorical_column类型特征的转换。通过这里的分析,我们可以看到特征转换的过程全部是在feature.py中完成的,因此,解决TFR框架支持SequenceFeatures的问题核心思路就是修改feature.py中的几个涉及特征转换的函数,使这些函数能够实现sequence_categorical_column类型特征的转换。
我们用到的sequence_categorical_column类型特征都在context_features中,所以我们的思路是,在处理特征的转换时,我先将sequence_categorical_column从其中拿出来,处理完经典特征的转换后,单独增加一段处理sequence_categorical_column转换的代码。待转换完成后,再合并回context_features中,最终仍然保持context_features和example_features两部分输入到模型中。具体的代码上如何处理可以参考这里。(让TensorFlow Ranking框架支持SequenceFeatures)
以上两个问题的解决方案都涉及到TFR框架对源码的修改。稍有不慎很容易引起稳定性兼容性问题以及意想不到的bug。为了尽量保障代码的稳定可靠,我们主要考虑了两个主要的代码组织原则:
第一,尽量缩小代码改动的范围,所有的改动都在尽可能少的几个函数内完成,不涉及TFR框架的其他模块代码。
第二,对于不涉及上述两个问题的项目要做到完全的兼容。对于不使用feature columns的项目或者不使用正则化(应该很少),保证原有逻辑和计算结果不变。
04
实验:LTR模型和原生模型的效果对比
究竟TFR框架训练的LTR排序模型对比同样网络结构的原生模型,能够带来多大的效果提升呢,我们也专门做了线上实验来分析。选取了一个业务场景,取出三个流量组分别做以下模型:
· BaseB:没有排序服务,为每个召回渠道配置优先级,系统按照优先级给出推荐结果。
· Ranking:TensorFlow原生Estimator开发的排序算法。
· TfrRankingB:基于TFR框架开发的LTR排序算法。
其中,TfrRankingB相比较于Ranking,模型结构完全一致,也就是采用同一个Scoring Function,训练数据集也完全一致。但是由于TfrRankingB采用TFR框架训练的LTR模型,模型优化上有以下几处不同:

以上的几处不同是模型训练方式和评估指标上的不同,这也正是采用TFR框架带给我们的。而训练数据和模型本身,包括正则化项在内,TfrRankingB和Ranking是完全一样。两个模型训练后,与BaseB一起在线上真实流量环境下测试完整4天,其中day_1和day_2为平日,day_3和day_4是休息日。线上实验考查用户的CTR(点击率)、UCTR(用户点击率)和LPLAY(长播放占比),效果如下:
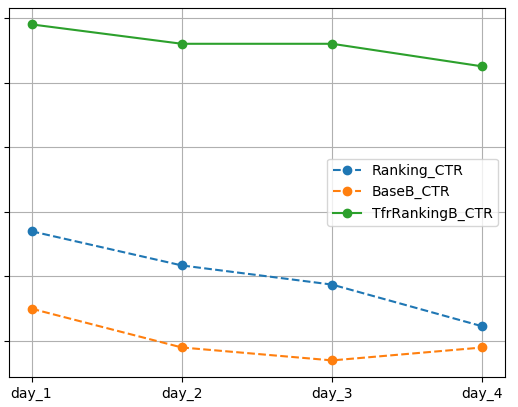
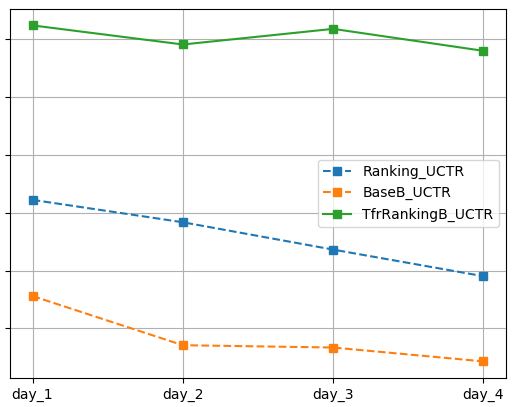
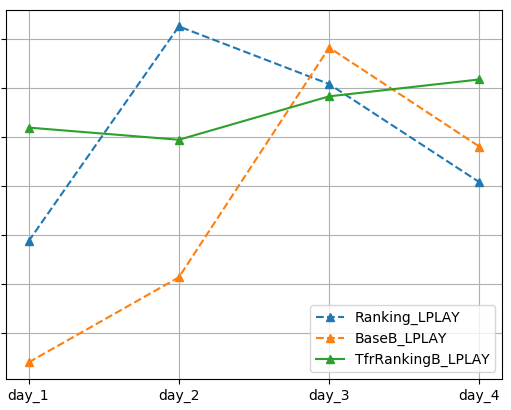
考虑到业务保密性,我们对横纵坐标的具体取值不做展示。但是结论显而易见:
1. 在CTR和UCTR指标上,TfrRankingB显著优于Ranking,Ranking显著优于BaseB。
2. 在LPLAY指标上,TfrRankingB优于Ranking,Ranking优于BaseB。
总结
使用TFR框架后,可以非常方便的基于TensorFlow开发LTR模型或者将现有模型改造为LTR模型。同时,TFR框架的模块设计、代码逻辑都非常巧妙,诸如高内聚低耦合等大家常常挂在嘴边的规范也实实在在的落在了代码上。在接下来的工作中,逐步将现有的TensorFlow 1.X版本升级到2.X版本,并观察TFR框架对TensorFlow 2.X的支持情况。
参考文献
1. Burges C J C. From ranknet to lambdarank to lambdamart: An overview[J]. Learning, 2010, 11(23-581): 81.
2. Liu T Y. Learning to rank for information retrieval[M]. Springer Science & Business Media, 2011.
3. Pasumarthi R K, Bruch S, Wang X, et al. Tf-ranking: Scalable tensorflow library for learning-to-rank[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 2970-2978.
4. Krichene W, Rendle S. On Sampled Metrics for Item Recommendation[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1748-1757.
5. https://github.com/tensorflow/ranking

也许你还想看

扫一扫下方二维码,更多精彩内容陪伴你!


本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













