前言
其实这篇文章只是从Kafka索引入手,来讲述算法在工程上基于场景的灵活运用。单单是因为看源码的时候有感而写之。
索引的重要性
索引对于我们来说并不陌生,每一本书籍的目录就是索引在现实生活中的应用。通过寥寥几页纸就得以让我等快速查找需要的内容。冗余了几页纸,缩短了查阅的时间。空间和时间上的互换,包含着宇宙的哲学。
工程领域上数据库的索引更是不可或缺,没有索引很难想象如此庞大的数据该如何检索。
明确了索引的重要性,咱再来看看索引在Kafka里是如何实现的。
索引在Kafka中的实践
首先Kafka的索引是稀疏索引,这样可以避免索引文件占用过多的内存,从而可以在内存中保存更多的索引。对应的就是Broker 端参数log.index.interval.bytes 值,默认4KB,即4KB的消息建一条索引。
Kafka中有三大类索引:位移索引、时间戳索引和已中止事务索引。分别对应了.index、.timeindex、.txnindex文件。
与之相关的源码如下:
1、AbstractIndex.scala:抽象类,封装了所有索引的公共操作
2、OffsetIndex.scala:位移索引,保存了位移值和对应磁盘物理位置的关系
3、TimeIndex.scala:时间戳索引,保存了时间戳和对应位移值的关系
4、TransactionIndex.scala:事务索引,启用Kafka事务之后才会出现这个索引(本文暂不涉及事务相关内容)


<center>索引类图</center>
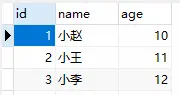
先来看看AbstractIndex的定义
image
AbstractIndex的定义在代码里已经注释了,成员变量里面还有个entrySize。这个变量其实是每个索引项的大小,每个索引项的大小是固定的。
entrySize
在OffsetIndex中是override def entrySize = 8,8个字节。
在TimeIndex中是override def entrySize = 12,12个字节。
为何是8 和12?
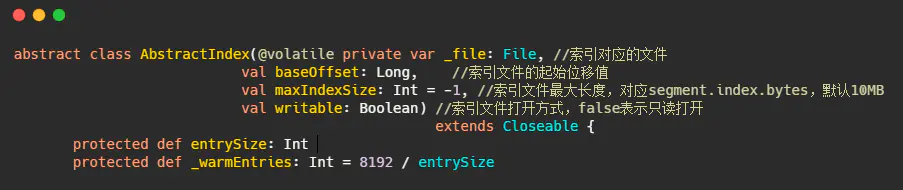
在OffsetIndex中,每个索引项存储了位移值和对应的磁盘物理位置,因此4+4=8,但是不对啊,磁盘物理位置是整型没问题,但是AbstractIndex的定义baseOffset来看,位移值是长整型,不是因为8个字节么?
因此存储的位移值实际上是相对位移值,即真实位移值-baseOffset的值。
相对位移用整型存储够么?够,因为一个日志段文件大小的参数log.segment.bytes是整型,因此同一个日志段对应的index文件上的位移值-baseOffset的值的差值肯定在整型的范围内。
为什么要这么麻烦,还要存个差值?
1、为了节省空间,一个索引项节省了4字节,想想那些日消息处理数万亿的公司。
2、因为内存资源是很宝贵的,索引项越短,内存中能存储的索引项就越多,索引项多了直接命中的概率就高了。这其实和MySQL InnoDB 为何建议主键不宜过长一样。每个辅助索引都会存储主键的值,主键越长,每条索引项占用的内存就越大,缓存页一次从磁盘获取的索引数就越少,一次查询需要访问磁盘次数就可能变多。而磁盘访问我们都知道,很慢。
互相转化的源码如下,就这么个简单的操作:
image
上述解释了位移值是4字节,因此TimeIndex中时间戳8个字节 + 位移值4字节 = 12字节。
_warmEntries
这个是干什么用的?
首先思考下我们能通过索引项快速找到日志段中的消息,但是我们如何快速找到我们想要的索引项呢?一个索引文件默认10MB,一个索引项8Byte,因此一个文件可能包含100多W条索引项。
不论是消息还是索引,其实都是单调递增,并且都是追加写入的,因此数据都是有序的。在有序的集合中快速查询,脑海中突现的就是二分查找了!
那就来个二分!

二分查找
这和_warmEntries有什么关系?首先想想二分有什么问题?
就Kafka而言,索引是在文件末尾追加的写入的,并且一般写入的数据立马就会被读取。所以数据的热点集中在尾部。并且操作系统基本上都是用页为单位缓存和管理内存的,内存又是有限的,因此会通过类LRU机制淘汰内存。
看起来LRU非常适合Kafka的场景,但是使用标准的二分查找会有缺页中断的情况,毕竟二分是跳着访问的。
这里要说一下kafka的注释写的是真的清晰,咱们来看看注释怎么说的
when looking up index, the standard binary search algorithm is not cache friendly, and can cause unnecessary
page faults (the thread is blocked to wait for reading some index entries from hard disk, as those entries are not
cached in the page cache)
翻译下:当我们查找索引的时候,标准的二分查找对缓存不友好,可能会造成不必要的缺页中断(线程被阻塞等待从磁盘加载没有被缓存到page cache 的数据)
注释还友好的给出了例子

image
简单的来讲,假设某索引占page cache 13页,此时数据已经写到了12页。按照kafka访问的特性,此时访问的数据都在第12页,因此二分查找的特性,此时缓存页的访问顺序依次是0,6,9,11,12。因为频繁被访问,所以这几页一定存在page cache中。
当第12页不断被填充,满了之后会申请新页第13页保存索引项,而按照二分查找的特性,此时缓存页的访问顺序依次是:0,7,10,12。这7和10很久没被访问到了,很可能已经不再缓存中了,然后需要从磁盘上读取数据。注释说:在他们的测试中,这会导致至少会产生从几毫秒跳到1秒的延迟。
基于以上问题,Kafka使用了改进版的二分查找,改的不是二分查找的内部,而且把所有索引项分为热区和冷区
这个改进可以让查询热数据部分时,遍历的Page永远是固定的,这样能避免缺页中断。
看到这里其实我想到了一致性hash,一致性hash相对于普通的hash不就是在node新增的时候缓存的访问固定,或者只需要迁移少部分数据。
好了,让我们先看看源码是如何做的

image
实现并不难,但是为何是把尾部的8192作为热区?
这里就要再提一下源码了,讲的很详细。
- This number is small enough to guarantee all the pages of the "warm" section is touched in every warm-section lookup. So that, the entire warm section is really "warm".
When doing warm-section lookup, following 3 entries are always touched: indexEntry(end), indexEntry(end-N), and indexEntry((end*2 -N)/2). If page size >= 4096, all the warm-section pages (3 or fewer) are touched, when we
touch those 3 entries. As of 2018, 4096 is the smallest page size for all the processors (x86-32, x86-64, MIPS, SPARC, Power, ARM etc.).大致内容就是现在处理器一般缓存页大小是4096,那么8192可以保证页数小于等3,用于二分查找的页面都能命中
- This number is large enough to guarantee most of the in-sync lookups are in the warm-section. With default Kafka settings, 8KB index corresponds to about 4MB (offset index) or 2.7MB (time index) log messages.
8KB的索引可以覆盖 4MB (offset index) or 2.7MB (time index)的消息数据,足够让大部分在in-sync内的节点在热区查询
以上就解释了什么是_warmEntries,并且为什么需要_warmEntries。
可以看到朴素的算法在真正工程上的应用还是需要看具体的业务场景的,不可生搬硬套。并且彻底的理解算法也是很重要的,例如死记硬背二分,怕是看不出来以上的问题。还有底层知识的重要性。不然也是看不出来对缓存不友好的。
从Kafka的索引冷热分区到MySQL InnoDB的缓冲池管理
从上面这波冷热分区我又想到了MySQL的buffer pool管理。MySQL的将缓冲池分为了新生代和老年代。默认是37分,即老年代占3,新生代占7。即看作一个链表的尾部30%为老年代,前面的70%为新生代。替换了标准的LRU淘汰机制。

image
MySQL的缓冲池分区是为了解决预读失效和缓存污染问题。
1、预读失效:因为会预读页,假设预读的页不会用到,那么就白白预读了,因此让预读的页插入的是老年代头部,淘汰也是从老年代尾部淘汰。不会影响新生代数据。
2、缓存污染:在类似like全表扫描的时候,会读取很多冷数据。并且有些查询频率其实很少,因此让这些数据仅仅存在老年代,然后快速淘汰才是正确的选择,MySQL为了解决这种问题,仅仅分代是不够的,还设置了一个时间窗口,默认是1s,即在老年代被再次访问并且存在超过1s,才会晋升到新生代,这样就不会污染新生代的热数据。
小结
文章先从索引入手,这就是时间和空间的互换。然后引出Kafka中索引存储使用了相对位移值,节省了空间,并且讲述了索引项的访问是由二分查找实现的,并结合Kafka的使用场景解释了Kafka中使用的冷热分区实现改进版的二分查找,并顺带提到了下一致性Hash,再由冷热分区联想到了MySQL缓冲池变形的LRU管理。
这一步步实际上都体现算法在工程中的灵活运用和变形实现。有些同学认为算法没用,刷算法题只是为了面试,实际上各种中间件和一些底层实现都体现了算法的重要性。
不说了,头有点冷。
7人点赞