
点击上面"脑机接口社区"关注我们
更多技术干货第一时间送达
大家好!
今天Rose小哥结合案例代码给大家介绍一下MNE是如何从Raw对象中解析event的。
这篇内容主要描述了如何从原始记录中读取实验事件,以及如何在MNE-Python中事件的两种不同表示形式(事件数组和注释对象)之间进行转换。
在入门教程中,我们看到了从"STIM"通道读取实验事件的示例;在这里,我们将更广泛地讨论事件和注释,提供有关从STIM通道读取的更详细的信息,并给出一个读取事件的示例。在教程"使用事件和注释连续数据"讨论了如何分别绘制、合并、加载、保存和导出事件和注释,后面的教程还介绍了Raw对象的交互式注释。
案例中为了节省内存,我对Raw对象进行了裁剪,只要60秒:
首先导入工具包
import os
加载数据
sample_data_folder = mne.datasets.sample.data_path()
对Raw对象数据进行裁剪,获取60秒数据
raw.crop(tmax=60).load_data()

事件(Events)和注释(Annotations)数据结构
一般来说,事件和注释数据结构都具有相同的目的:它们提供了EEG/MEG记录期间的时间与事件发生时的描述之间的映。换句话说,他们把时间和内容联系起来。主要区别如下:
单位:事件(Events)这种数据结构以样本为单位表示时间,而注释(Annotations)数据结构以秒为单位表示时间。
描述上的限制:事件数据结构将"what"表示为整数"Event ID"代码,而注释数据结构将what表示为字符串。
持续时间的编码方式:事件数组的事件没有持续时间(尽管可以在事件数组中用成对的开始/偏移事件来表示持续时间),而Annotations对象的每个元素都必须包含持续时间(如果需要一个瞬时事件,则持续时间可以是零)。
内部表示:事件存储为普通的NumPy数组,而注释是在MNE-Python中定义的类似列表的类。
什么是STIM渠道?
STIM通道("刺激通道[stimulus channel]"的缩写)是指不接收来自EEG、MEG或其他传感器的信号的通道。相反,刺激通道记录电压(通常是从实验控制计算机发送的固定大小的短矩形直流脉冲)被时间锁定在实验事件上,例如受试者的刺激或按钮按下反应(这些脉冲有时被称为TTL脉冲、事件脉冲、触发信号,或者仅仅是"触发器[triggers]")。在其他情况下,这些脉冲可能不会被严格地锁定在实验事件上,而是可能发生在两次试验验之间,以表明在接下来的实验中将要发生的刺激类型(或实验条件)。
直流脉冲可能全部在一个STIM通道上(在这种情况下,不同的实验事件或试验类型被编码为不同的电压幅度),或者它们也可能分布在多个通道上,在这种情况下,脉冲发生的信道可以被用来编码不同的事件或条件。
即使在具有多个STIM通道的系统中,通常也有一个通道记录其他STIM通道的加权和,这样就可以将该通道上的电压水平明确解码为特定的事件类型。
在较老的Neuromag系统(例如用于记录样本数据的系统)上,这个"总和通道"通常是STI 014;在较新的系统中,通常是STI101。
你可以在原始数据文件看到STIM通道:
raw.copy().pick_types(meg=False, stim=True).plot(start=3, duration=6)
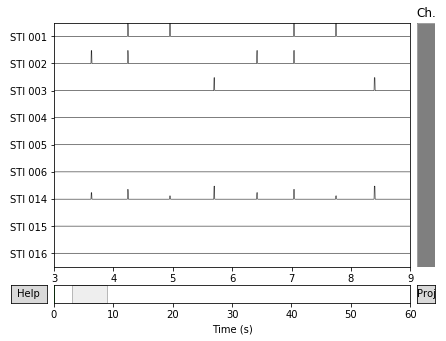
从上面的结果可以看到STI 014(总和通道)包含不同幅度的脉冲,而其他通道上的脉冲幅度较为一致。
从上图中还可以看到,每次在其他STIM通道上有一个脉冲时,STI 014上也有一个相对应的脉冲。
将STIM通道信号转换为事件数组
如果数据在STIM通道上记录了事件,则可以使用mne.find_events()将它们转换成事件数组。
每个脉冲的开始(或偏移)的样本数被记录为事件时间,脉冲幅度被转换为整数,
这些样本数以及整数代码对 被存储在NumPy数组中(通常称为"事件数组"或"事件")。
在其最简单的形式中,该函数只需要Raw对象以及用于读取事件的通道的名称:
events = mne.find_events(raw, stim_channel='STI 014')

如果不提供STIM通道的名称,find_events()将首先为变量MNE_STIM_CHANNEL、MNE_STIM_CHANNEL_1等查找MNE-Python配置变量。
如果没有找到,则尝试使用STI 014和STI101通道,然后使用raw.ch_names中第一个类型为"STIM"的通道。
find_events()有多个选项,包括用于将事件与STIM通道脉冲的开始或偏移对齐,设置最小脉冲持续时间以及处理连续脉冲(它们之间不返回零)的选项。例如,可以通过将output='step'传递给mne.find_events()来有效地编码事件持续时间,更多详细信息,可以参阅find_events()的文档。
将嵌入式事件作为注释读取(Reading embedded events as Annotations)
一些EEG/MEG系统生成文件,其中事件存储在单独的数据数组中,而不是作为脉冲存储在一个或多个STIM通道中。例如,EEGLAB格式将事件作为数组的集合存储在.set文件中。读取这些文件时,MNE-Python会自动将存储的事件转换成Aannotation对象,并将其存储为Raw对象的Annotations属性:
testing_data_folder = mne.datasets.testing.data_path()
可以通过三个属性访问注释(Annotations)对象中的核心数据:开始、持续时间和描述。在这里我们可以看到EEGLAB文件中存储了154个事件,它们的持续时间都是0秒,有两种不同类型的事件,第一个事件发生在录音开始后大约1秒:
print(len(eeglab_raw.annotations))
154{0.0}{'rt', 'square'}1.000068359375
有关注释(Annotations)对象的更多信息,包括如何以交互方式向原始(Raw)对象添加注释,以及如何绘图、连接、加载、保存和导出注释对象,可以在注释连续数据的教程中找到。
事件数组和注释对象之间的转换
一旦将实验事件读入MNE-Python(作为事件数组或注释对象),就可以根据需求对这两种格式之间进行转换。这样做可能是因为,例如,需要一个事件数组来提取连续数据。
要将注释对象转换为事件数组,请在包含注释的Rwa文件上使用函数mne.events_from_annotations()。
该函数将为raw.annotations.description的每个唯一元素分配一个整数Event ID,并将返回描述到整数事件ID的映射以及派生的事件数组。默认情况下,在每个注释开始时创建一个事件;这可以通过events_from_annotations()的chunk_duration参数进行修改,以在每个注释范围内创建等间隔的事件(请参见下面的为每个注释创建多个事件,或参见直接创建等距事件的事件数组的等距事件数组)。
events_from_annot, event_dict = mne.events_from_annotations(eeglab_raw)
Used Annotations descriptions: ['rt', 'square']{'rt': 1, 'square': 2}[[128 0 2] [217 0 2] [267 0 1] [602 0 2] [659 0 1]]
如果要控制将哪些整数映射到每个唯一的描述值,则可以传递一个dict,将映射指定为events_from_annotations()的event_id参数;此dict将未经修改地返回为event_dict。
custom_mapping = {'rt': 77, 'square': 42}
Used Annotations descriptions: ['rt', 'square']{'rt': 77, 'square': 42}[[128 0 42] [217 0 42] [267 0 77] [602 0 42] [659 0 77]]
要进行相反的转换(从事件(Events)数组到注释(Annotations)对象),可以创建从整数事件ID到字符串描述的映射,并使用Annotations构造函数创建注释对象,使用set_annotations()方法将注释添加到原始(Raw)对象。因为样本数据是在Neuromag系统上记录的(其中样本编号是在采集系统启动时开始的,而不是在记录启动时开始的),所以我们还需要传入orig_time参数,以便onsets与记录开始时正确对齐:
mapping = {1: 'auditory/left', 2: 'auditory/right', 3: 'visual/left',
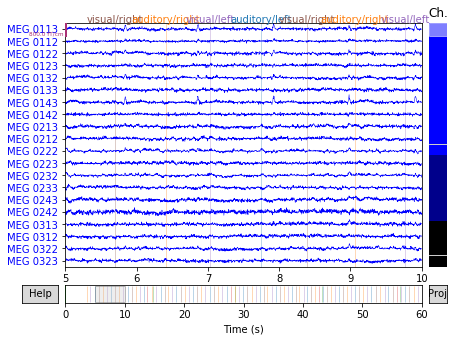
现在,在绘制原始数据时,注释将自动显示,并根据它们的标签值进行颜色编码:
raw.plot(start=5, duration=5)
更多阅读
动态脑电图(Ambulatory EEG)及其工作过程、数据处理!
脑机头条 第39期| MIT最新黑科技—3D打印柔软大脑植入物
北大团队成功实现精准删除特定记忆,马斯克脑机接口有望今年人体测试
脑机接口BCI学习交流QQ群:941473018
微信群请扫码添加,Rose拉你进群
(请务必填写备注**,eg. 姓名+单位+专业)**

长按加群

长按关注我们
欢迎转发、点个在看
本文分享自微信公众号 - 脑机接口社区(Brain_Computer)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












