
在数字化转型的浪潮下,大数据产业作为城市数字化转型的重要助力,带来了城市管理手段、模式、理念的深刻变革与创新。为了更好地了解国家城镇的职住分布结构,帮助城市管理部门制定更加合理的规划策略,为城市商业产业提供有效的规划依据。本期【极客星球】特邀MobTech袤博科技数据工程师锟锟为大家介绍一种居住办公人口的统计技术的思路。
1、人口统计的常用方法
统计某一特定范围内的人口情况,包括居住人口、工作人口、人群情况、人口流动分析等,是了解该片区经济、社会发展情况的基础,也是政府或企业进行区域分析,进行未来规划的重要依据。现有的人口统计指标和数据模型纷繁多样,按照数据源的类型,大致可以分为两类方法:
一类是比较传统的方法,比如:政府发起的大规模全国性人口普查或地方政府的年度统计数据;组织人员实地统计,如:问卷、在特定地点数人数等方式;根据小区的规划户数,与写字楼的建筑面积,估算入驻的人口情况;另一类则是基于人工智能的数据管理及联邦学习、多方安全技术等核心技术的攻关,在数据安全得到有效保护的前提下,通过更加精确的数据分析实现人口数据统计。
2、居住办公人口统计解决方案
无论新型的统计方法还是传统的统计方法,在人口数据分析的准确度方面,都面临着几个共同的问题:比如,如何区分居住人群和工作人群及其人群属性;如何剔除失真异常的定位数据;如何修正定位数据的人群覆盖率不足导致的数据缺失等等。
为此,MobTech袤博科技数据工程师锟锟表示,针对这些统计痛点,基于大数据分析和智能算法模型,通过五个步骤,可以快速、高效、低成本、灵活地统计某一个特定范围内当前的居住人口数量和工作人口数量。
首先,数据准备。在数据准备阶段,需要对特定范围内的功能区域进行划分,用经纬度来划分出居住区、工作区、工作居住两用区。功能区域划分的方式有很多种,我们一般采用公开地图信息和人工描绘等方法。
其次,数据清洗。清洗数据是为了解决数据异常和数据重复的情况,这些异常数据在统计过程中很难完全避免,如果不剔除,将会导致某些范围内的人口计算结果大幅失真。为处理异常数据,统计时需将经纬度数据截取到小数点后六位,捞取一定时间范围内在这些经纬度处产生报点的数量,当数量大于平均数一定倍数以上的经纬度点,即标记为异常经纬度。
第三,人群常住城市计算。人总是向往远方,不断融入新的环境。由于人群流动的不确定性,为了更精准地确定其居住地,首先需要先明确其常住城市。明确其常住城市的方法就是对人群在一段时间内所在的城市做一轮统计,出现频率最高的城市即常住城市。在常住城市之外出现的数据做剔除处理。
第四,居住和工作人群特征区分。如何区分居住和工作人群,主要依靠两项数据支撑:一是空间上的判断,依赖于在数据准备阶段获得的居住和工作地的经纬度围栏;二是时间上的判断,依赖于数据的时间分析。
最后,数据覆盖率修正。由于该类数据不可能覆盖全部人口,因此在数据清洗统计完成后,还需要用覆盖率系数进行修正。对于整个行政区的统计,该系数的确定可以使用行政区的官方统计人口数据;如果统计的范围较小,则可以使用该片区居住小区的规划人口等信息进行修正。
在完成上述五步动作之后,我们将清洗去重后的数据与划分的居住工作地围栏进行匹配,即可快速统计所需范围内的居住和办公人口数量,最终计算得到的数据分布情况示例如下图:图中的蓝色虚线,是自定义圈选的范围,图中的栅格,则代表了人口的分布密度。
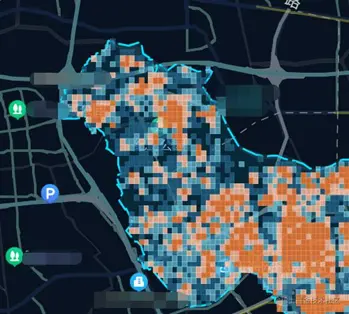
人口密度分布示意图
随着大数据产业的发展,大数据技术更新迭代加速。人工智能的数据管理及联邦学习、多方安全技术等核心技术的攻关,大大助力于释放数据价值,推动城市数字化转型。以上方法在部分应用中已投入使用,帮助政府机构和企业解决了实际问题。当然所有的技术和算法未来还有很大的改进空间,比如对于功能复合的片区,如商场上盖小区,商场上盖写字楼,或者商住两用的建筑,如何更好地将人群的特征区分开;再比如地铁,公交等人流较大的点位,如何加以修正等等。对这方面感兴趣的伙伴也可以多多留言交流。
相关阅读:极客星球 | 机器学习赋能商业地产决策进阶












