
数据库高可用
1.1 数据库高可用说明
当数据库的主库宕机之后.如果没有高可用机制,则可能导致整个服务全部不能正常的使用.
解决策略: 双主模式(双机热备)
1.2 数据库双机热备实现
1.2.1 双机热备的说明
将2台数据库设置为双主模式.互为主从的结构.其中任意的数据库服务器既是主机.也是从机.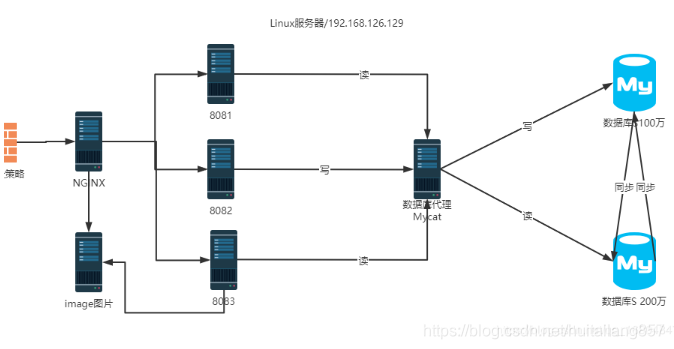
1.2.1 双机热备实现
规划:
之前配置:
192.168.126.129:3306 主机.
192.168.126.130:3306 从机.
优化后的配置
192.168.126.129:3306 主机.从机
192.168.126.130:3306 从机.主机
配置:
1).检查130 主机的状态信息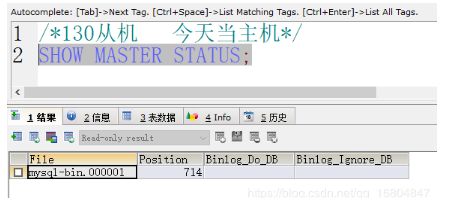
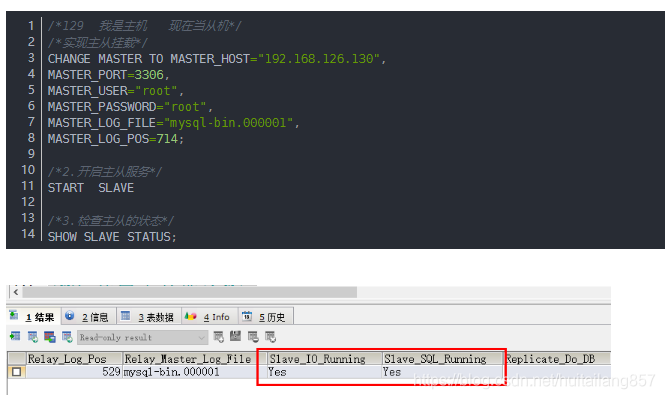
2).实现主从的挂载 操作的是129
/129 我是主机 现在当从机/
/实现主从挂载/
CHANGE MASTER TO MASTER_HOST=“192.168.126.130”,
MASTER_PORT=3306,
MASTER_USER=“root”,
MASTER_PASSWORD=“root”,
MASTER_LOG_FILE=“mysql-bin.000001”,
MASTER_LOG_POS=714;
/2.开启主从服务/
START SLAVE
/3.检查主从的状态/
SHOW SLAVE STATUS;
1.2.2 双机热备的测试
测试A: 修改129中的数据,检查130中是否实现了数据的同步!!
测试B: 修改130中的数据.检查129种是否实现了数据的同步!!!
1.3 数据库高可用实现
1.3.1 Mycat配置
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--name属性是自定义的 dataNode表示数据库的节点信息 jtdb表示逻辑库-->
<schema name="jtdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="jtdb"/>
<!--定义节点名称/节点主机/数据名称-->
<dataNode name="jtdb" dataHost="localhost1" database="jtdb" />
<!--参数介绍-->
<!--balance 0表示所有的读操作都会发往writeHost主机 -->
<!--1表示所有的读操作发往readHost和闲置的主节点中-->
<!--writeType=0 所有的写操作都发往第一个writeHost主机-->
<!--writeType=1 所有的写操作随机发往writeHost中-->
<!--dbType 表示数据库类型 mysql/oracle-->
<!--dbDriver="native" 固定参数 不变-->
<!--switchType=-1 表示不自动切换, 主机宕机后不会自动切换从节点-->
<!--switchType=1 表示会自动切换(默认值)如果第一个主节点宕机后,Mycat会进行3次心跳检测,如果3次都没有响应,则会自动切换到第二个主节点-->
<!--并且会更新/conf/dnindex.properties文件的主节点信息 localhost1=0 表示第一个节点.该文件不要随意修改否则会出现大问题-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select 1</heartbeat>
<!--配置第一台主机主要进行写库操作,在默认的条件下Mycat主要操作第一台主机在第一台主机中已经实现了读写分离.因为默认写操作会发往137的数据库.读的操作默认发往141.如果从节点比较忙,则主节点分担部分压力.
-->
<writeHost host="hostM1" url="192.168.126.129:3306" user="root" password="root">
<!--读数据库1-->
<readHost host="hostS1" url="192.168.126.130:3306" user="root" password="root" />
<!--读数据库2-->
<readHost host="hostS2" url="192.168.126.129:3306" user="root" password="root" />
</writeHost>
<!--定义第二台主机 由于数据库内部已经实现了双机热备.-->
<!--Mycat实现高可用.当第一个主机137宕机后.mycat会自动发出心跳检测.检测3次.-->
<!--如果主机137没有给Mycat响应则判断主机死亡.则回启东第二台主机继续为用户提供服务.-->
<!--如果137主机恢复之后则处于等待状态.如果141宕机则137再次持续为用户提供服务.-->
<!--前提:实现双机热备.-->
<writeHost host="hostM2" url="192.168.126.130:3306" user="root" password="root">
<!--读数据库1-->
<readHost host="hostS1" url="192.168.126.130:3306" user="root" password="root" />
<!--读数据库2-->
<readHost host="hostS2" url="192.168.126.129:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
1.3.2 上传配置文件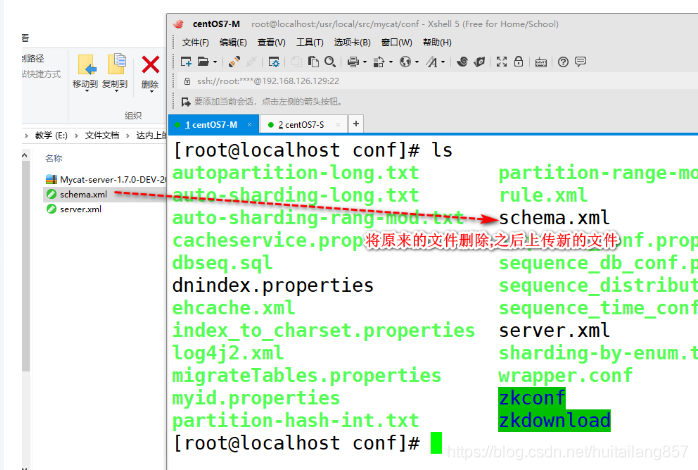
重启mycat.
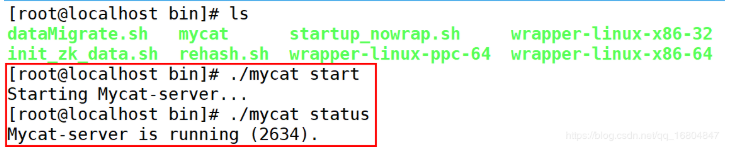
1.3.3数据库高可用测试
测试策略:
1).启动服务器检查用户数据是否正确获取.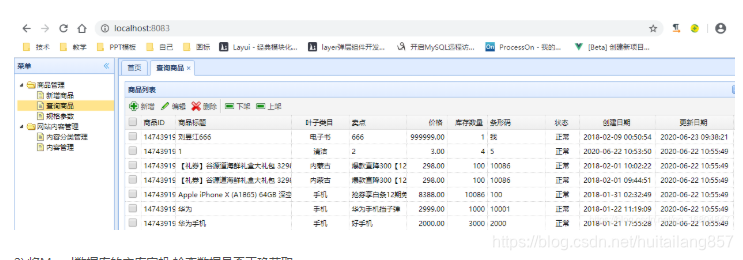
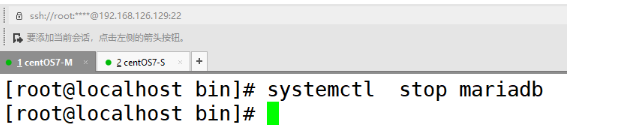
2).将Mysql数据库的主库宕机.检查数据是否正确获取
关闭mysql主机.
修改数据库记录: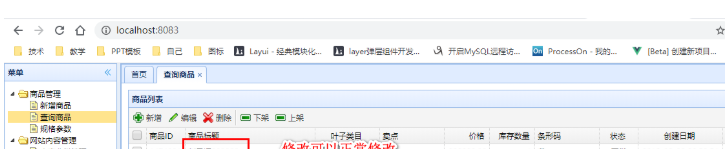
3).将mysql数据库重启,检查mysql数据库是否实现数据的同步.
检查主库记录:
1.4 京淘项目Linux发布(终极)
1.4.1 发布架构图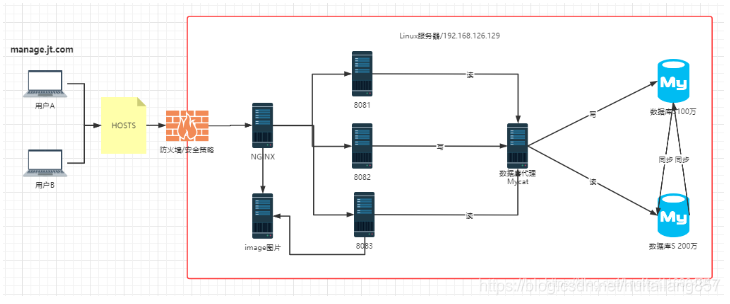
1.4.2 项目打包部署
1.4.3 重启nginx服务器

1.4.4 京淘后台项目发布测试
2 Redis 缓存机制
2.1 准备工作
1).还原端口号信息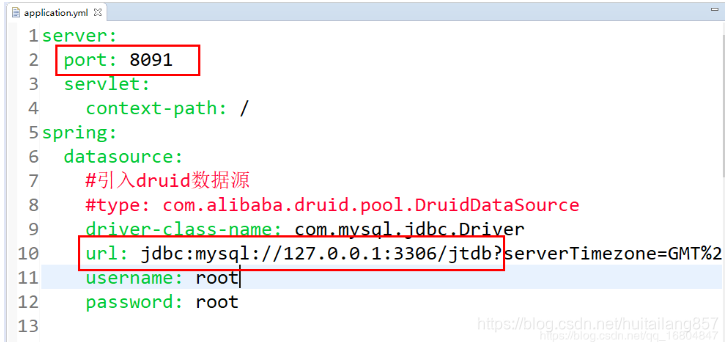
2).修改图片上传地址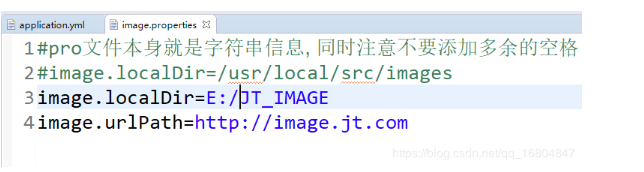
3).修改HOSTS文件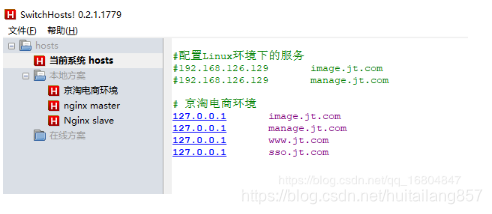
4).修改nginx.conf文件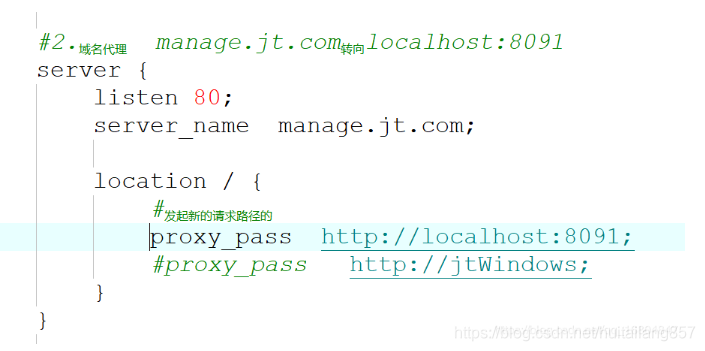
修改完成之后,重启nginx服务器.
2.2 为什么要引入缓存
说明:提供用户查询数据的速度.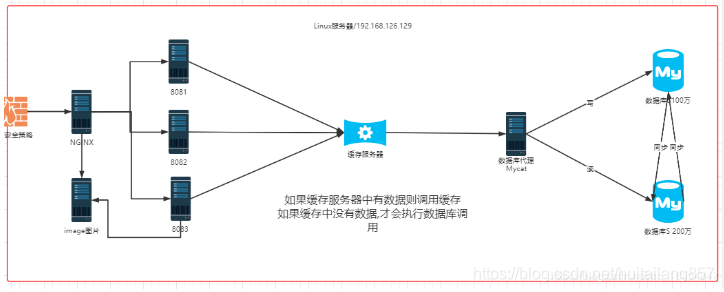
2.3 缓存设计的因素
缓存的存储的数据结构应该 K-V结构. key是唯一标识符.
缓存的运行环境 应该让缓存运行在内存中.
缓存的开发语言 C语言开发
缓存中的内存优化策略 LRU算法/LFU算法
缓存数据有效性的设定 多久超时
如何防止内存数据丢失 数据落地(数据进行持久化操作)
2.4 Redis
2.4.1 Redis介绍
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
核心: 内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件
数据类型: 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets)
处理速度: 写操作 8.6万/秒 读操作 11.2万/秒 平均10万/秒
2.5 Redis安装
2.5.1 上传安装包
2.5.2 解压安装包
命令:
1).tar -xvf redis-5.0.4.tar.gz
2).删除安装包,修改文件名称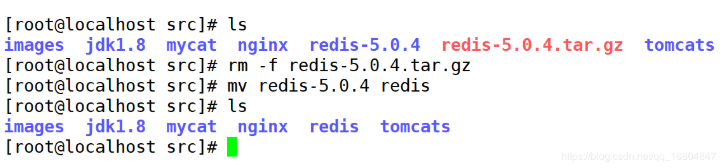
2.5.3 安装Redis
说明:跳转到redis根目录中执行如下指令
make
make install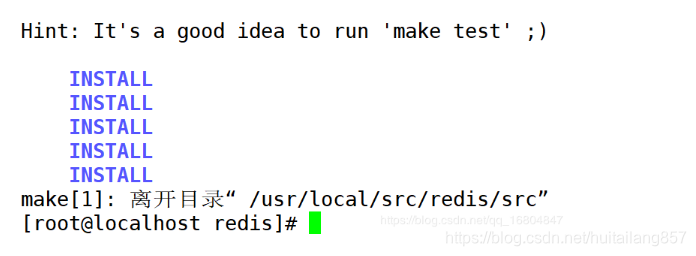
2.5.3 修改redis配置文件
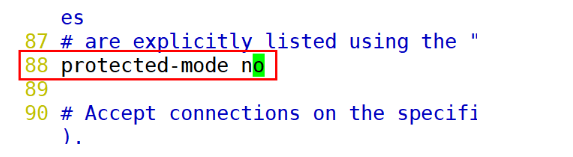
1).编辑配置文件 vim redis.conf
2).注释IP绑定
3).关闭保护模式
4).开启后台启动
2.5.4redis常规命令
1).启动redis redis-server redis.conf
2).进入redis客户端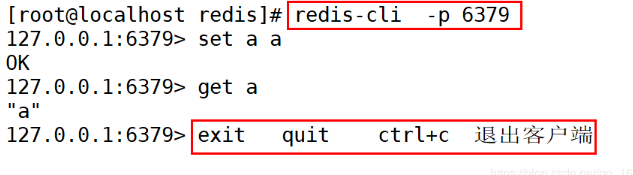
2).关闭redis redis-cli -p 6379 shutdown
小结
1.完成数据库高可用!!!
2.了解为什么需要使用redis
3.redis基本方法 开启 关闭等
2.6 Redis入门案例
2.6.1 引入jar包
<!--spring整合redis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</dependency>
2.6.2 String类型的测试
public class TestRedis {
/**
* 如果测试有误,则检查上午修改的三处配置文件. 重启redis.
* @throws InterruptedException
*/
@Test
public void testString() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.set("aaaa","123456");
System.out.println(jedis.get("aaaa"));
//判断redis中的key是否存在
if(!jedis.exists("abc")) {
jedis.set("abc","123456");
}
//为数据添加超时时间
jedis.set("h", "123");
jedis.expire("h", 10);
Thread.sleep(2000);
System.out.println("剩余的存活时间:"+jedis.ttl("h")+"秒");
}
/**
* 要求:如果key已经存在,则不允许修改!!!
* @throws InterruptedException
*/
@Test
public void testStringSetNX() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.flushAll(); //清空redis
jedis.setnx("abc", "123"); //只有当数据不存在时才会赋值.
jedis.setnx("abc", "456");
System.out.println(jedis.get("abc"));
}
/**
* 虽然expire可以为数据添加超时时间,但是从宏观角度分析,该方法不具备原子性的操作
* 使用该方法可能存在风险.
* @throws InterruptedException
*/
@Test
public void testStringSetEx() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.flushAll(); //清空redis
jedis.setex("abc", 100, "123"); //保证了数据的原子性操作
}
/**
* 1.set操作时,如果该数据存在则不允许赋值
* 2.set操作的同时要求添加超时时间
* 3.上述的操作,必须同时成功或者同时失败 保证原子性操作.
*
* XX = "xx"; 当key存在时 才会赋值
NX = "nx"; 当key不存在时才会赋值.
PX = "px"; 添加超时时间的单位 毫秒
EX = "ex"; 秒
*/
@Test
public void testStringSet() throws InterruptedException {
Jedis jedis = new Jedis("192.168.126.129",6379);
jedis.flushAll(); //清空redis
SetParams params = new SetParams();
params.nx().ex(60);
jedis.set("abc", "123456", params);
}
}
2.7 商品分类缓存实现原理说明
2.7.1 什么样的数据添加缓存
说明: 变化范围不大的数据,并且需要被频繁查询的数据 可以添加缓存,
常见用法: 省/市/县/乡, 商品分类信息
2.7.2 缓存实现策略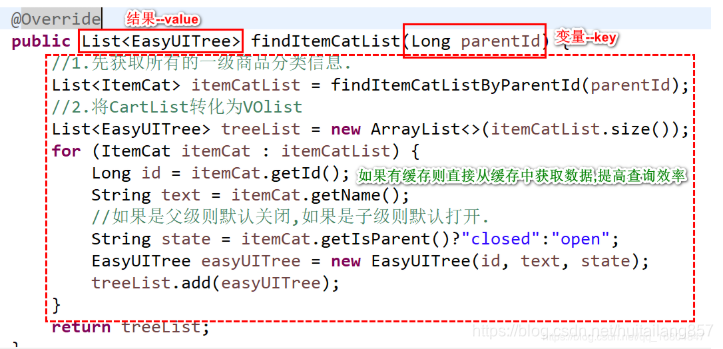
说明:
1.商品分类信息采用redis方式进行缓存存取.
2.如果需要存储到Redis中,则必须准备 key(String)-value(String)
3.由于redis通常情况下使用String的数据类型.所以需要将key-value转化为String数据类型.
4.需要将返回值结果List对象转化为JSON数据.
2.8 ObjectMapper学习
2.8.1 入门案例
public class TestObjectMapper {
@Test
public void testObject() throws JsonProcessingException {
//1.创建工具API对象
ObjectMapper objectMapper = new ObjectMapper();
//2.封装转化对象
ItemDesc itemDesc = new ItemDesc();
itemDesc.setItemId(1001L).setItemDesc("测试json转化")
.setCreated(new Date()).setUpdated(itemDesc.getCreated());
//对象------JSON-------String字符串
//3.对象转化为JSON时,调用的是对象的get()
String json = objectMapper.writeValueAsString(itemDesc);
System.out.println(json); //{key:value,key2:value2}
//4.将json串转化为对象 调用的是对象的set方法为属性赋值....
ItemDesc itemDesc2 = objectMapper.readValue(json, ItemDesc.class);
System.out.println(itemDesc2.toString());
}
@Test
public void testList() throws JsonProcessingException {
//1.创建工具API对象
ObjectMapper objectMapper = new ObjectMapper();
List<ItemDesc> list = new ArrayList<ItemDesc>();
ItemDesc itemDesc1 = new ItemDesc();
itemDesc1.setItemId(100L);
ItemDesc itemDesc2 = new ItemDesc();
itemDesc2.setItemId(200L);
list.add(itemDesc1);
list.add(itemDesc2);
//测试list集合转化为JSON
String json = objectMapper.writeValueAsString(list);
System.out.println(json);
//测试json结构,能否转化为List集合
List<ItemDesc> list2 = objectMapper.readValue(json, list.getClass());
System.out.println(list2);
}
}
2.8.2 JSON转化的工具API封装
说明:该工具API主要的目的为了简化对象与JSON转化的过程.编辑如下的API
//简化代码而生!!
public class ObjectMapperUtil {
//定义一个常量对象
private static final ObjectMapper MAPPER = new ObjectMapper();
//1.将对象转化为json串
public static String toJSON(Object target) {
String json = null;
try {
json = MAPPER.writeValueAsString(target);
} catch (JsonProcessingException e) {
e.printStackTrace();
//将检查异常,转化为运行时异常!!!!
throw new RuntimeException();
}
return json;
}
//2.将json串按照指定的类型转化为对象
//实现:传递什么类型,就返回什么对象
// <T> 定义泛型
public static <T> T toObj(String json,Class<T> target) {
T t = null;
try {
t = MAPPER.readValue(json, target);
} catch (JsonProcessingException e) {
e.printStackTrace();
throw new RuntimeException();
}
return t;
}
}
2.9 Spring容器管理Redis对象
2.9.2 编辑pro文件
说明:在jt-common中添加配置文件.指定redis的链接地址
redis.host=192.168.126.129
redis.port=6379
2.9.1 编辑配置类
说明:如果需要将redis对象交给Spring容器管理则必须通过配置文件/配置类的形式管理.
package com.jt.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import redis.clients.jedis.Jedis;
//代表早期的配置文件
@Configuration
@PropertySource("classpath:/properties/redis.properties")
public class RedisConfig {
@Value("${redis.host}")
private String host;
@Value("${redis.port}")
private Integer port;
//bean注解 将生成的jedis对象交给Spring容器管理
@Bean
public Jedis jedis() {
return new Jedis(host,port);
}
}
2.10 实现商品分类缓存
2.10.1 编辑ItemCatController
/**
* url:http://localhost:8091/item/cat/list
* 参数: 当展现二三级信息时,会传递父级的Id信息,如果展现1级菜单,则应该设定默认值
* 返回值: List<EasyUITree>
*/
@RequestMapping("list")
public List<EasyUITree> findItemCatList
(@RequestParam(name="id",defaultValue="0")Long parentId){
//1.查询一级商品分类信息,所以
//return itemCatService.findItemCatList(parentId); //数据库操作
return itemCatService.findItemCatCache(parentId); //缓存操作
}
2.10.2 编辑ItemCatService
/**
* 思路:
* 1.定义查询redis的key, key要求唯一的
* 2.第一次查询先查询redis.
* 没有数据: 表示缓存中没有数据, 查询数据库,之后将数据保存到redis中
* 有数据: 证明缓存中有值, 直接返回给用户即可.
*/
@SuppressWarnings("unchecked")
@Override
public List<EasyUITree> findItemCatCache(Long parentId) {
String key = "ITEM_CAT_PARENTID_"+parentId;
List<EasyUITree> treeList = new ArrayList<>();
//1.判断redis中是否有记录
if(jedis.exists(key)) {
//表示redis中有记录.
String json = jedis.get(key);
treeList =
ObjectMapperUtil.toObj(json, treeList.getClass());
System.out.println("实现redis缓存查询");
}else {
//redis中没有记录,需要先查询数据库.
treeList = findItemCatList(parentId);
//将数据库记录转化为json之后保存到redis中
String json = ObjectMapperUtil.toJSON(treeList);
jedis.set(key, json);
System.out.println("第一次查询数据库!!!!!");
}
return treeList;
}











